- PaddleOCR R&D team would like to share the released tools with developers, at 20:15 pm on August 4th, [Live Address](https://live.bilibili.com/21689802).
- PaddleOCR R&D team would like to share the released tools with developers, at 20:15 pm on September 8th, [Live Address](https://live.bilibili.com/21689802).
- 2021.9.7 release PaddleOCR v2.3, [PP-OCRv2](#PP-OCRv2) is proposed. The CPU inference speed of PP-OCRv2 is 220% higher than that of PP-OCR server. The F-score of PP-OCRv2 is 7% higher than that of PP-OCR mobile.
- 2021.8.3 released PaddleOCR v2.2, add a new structured documents analysis toolkit, i.e., [PP-Structure](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/ppstructure/README.md), support layout analysis and table recognition (One-key to export chart images to Excel files).
- 2021.8.3 released PaddleOCR v2.2, add a new structured documents analysis toolkit, i.e., [PP-Structure](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/ppstructure/README.md), support layout analysis and table recognition (One-key to export chart images to Excel files).
- 2021.4.8 release end-to-end text recognition algorithm [PGNet](https://www.aaai.org/AAAI21Papers/AAAI-2885.WangP.pdf) which is published in AAAI 2021. Find tutorial [here](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_en/pgnet_en.md);release multi language recognition [models](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_en/multi_languages_en.md), support more than 80 languages recognition; especically, the performance of [English recognition model](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_en/models_list_en.md#English) is Optimized.
- 2021.4.8 release end-to-end text recognition algorithm [PGNet](https://www.aaai.org/AAAI21Papers/AAAI-2885.WangP.pdf) which is published in AAAI 2021. Find tutorial [here](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_en/pgnet_en.md);release multi language recognition [models](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_en/multi_languages_en.md), support more than 80 languages recognition; especically, the performance of [English recognition model](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_en/models_list_en.md#English) is Optimized.
- 2021.1.21 update more than 25+ multilingual recognition models [models list](./doc/doc_en/models_list_en.md), including:English, Chinese, German, French, Japanese,Spanish,Portuguese Russia Arabic and so on. Models for more languages will continue to be updated [Develop Plan](https://github.com/PaddlePaddle/PaddleOCR/issues/1048).
- 2020.12.15 update Data synthesis tool, i.e., [Style-Text](./StyleText/README.md),easy to synthesize a large number of images which are similar to the target scene image.
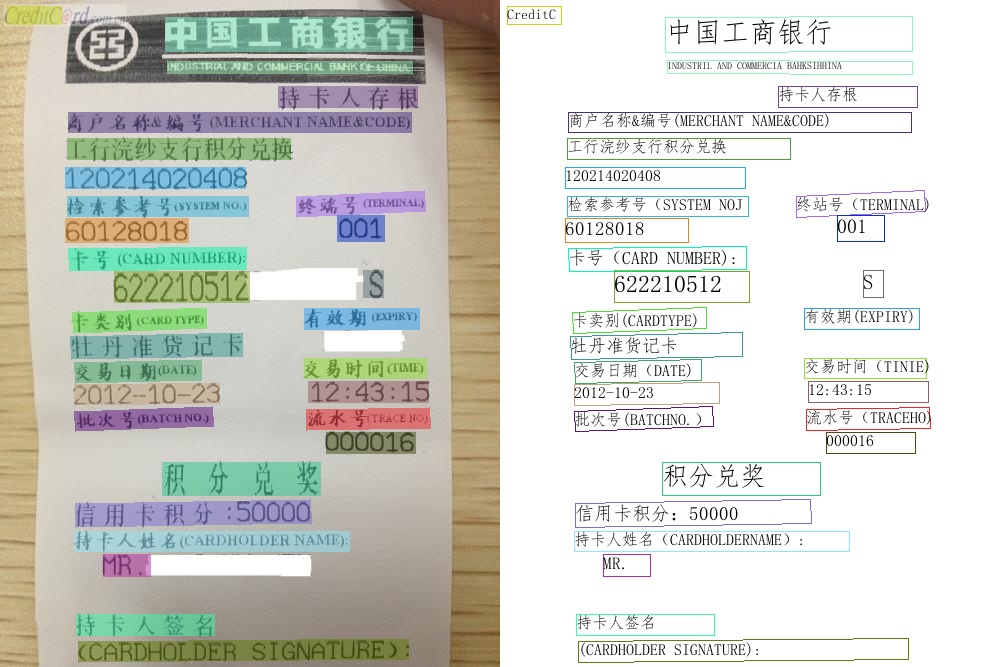
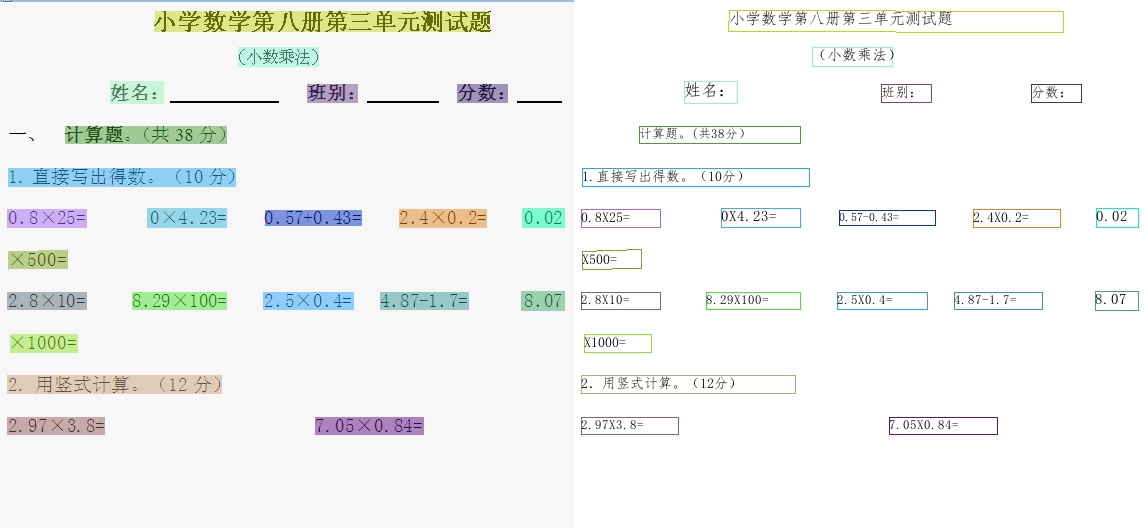
- 2020.11.25 Update a new data annotation tool, i.e., [PPOCRLabel](./PPOCRLabel/README.md), which is helpful to improve the labeling efficiency. Moreover, the labeling results can be used in training of the PP-OCR system directly.
- 2020.9.22 Update the PP-OCR technical article, https://arxiv.org/abs/2009.09941
-[more](./doc/doc_en/update_en.md)
-[more](./doc/doc_en/update_en.md)
## Features
## Features
- PPOCR series of high-quality pre-trained models, comparable to commercial effects
- PP-OCR series of high-quality pre-trained models, comparable to commercial effects
- Ultra lightweight ppocr_mobile series models: detection (3.0M) + direction classifier (1.4M) + recognition (5.0M) = 9.4M
- Ultra lightweight PP-OCRv2 series models: detection (3.1M) + direction classifier (1.4M) + recognition 8.5M) = 13.0M
- General ppocr_server series models: detection (47.1M) + direction classifier (1.4M) + recognition (94.9M) = 143.4M
- Ultra lightweight PP-OCR mobile series models: detection (3.0M) + direction classifier (1.4M) + recognition (5.0M) = 9.4M
- General PP-OCR server series models: detection (47.1M) + direction classifier (1.4M) + recognition (94.9M) = 143.4M
- Support Chinese, English, and digit recognition, vertical text recognition, and long text recognition
- Support Chinese, English, and digit recognition, vertical text recognition, and long text recognition
- Support multi-language recognition: Korean, Japanese, German, French
- Support multi-language recognition: Korean, Japanese, German, French
- Rich toolkits related to the OCR areas
- Rich toolkits related to the OCR areas
...
@@ -88,16 +82,16 @@ Mobile DEMO experience (based on EasyEdge and Paddle-Lite, supports iOS and Andr
...
@@ -88,16 +82,16 @@ Mobile DEMO experience (based on EasyEdge and Paddle-Lite, supports iOS and Andr
<aname="Supported-Chinese-model-list"></a>
<aname="Supported-Chinese-model-list"></a>
## PP-OCR 2.0 series model list(Update on Dec 15)
## PP-OCR series model list(Update on September 8th)
**Note** : Compared with [models 1.1](https://github.com/PaddlePaddle/PaddleOCR/blob/develop/doc/doc_en/models_list_en.md), which are trained with static graph programming paradigm, models 2.0 are the dynamic graph trained version and achieve close performance.
| Model introduction | Model name | Recommended scene | Detection model | Direction classifier | Recognition model |
| Model introduction | Model name | Recommended scene | Detection model | Direction classifier | Recognition model |
| Chinese and English ultra-lightweight OCR model (9.4M) | ch_ppocr_mobile_v2.0_xx | Mobile & server |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar)|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
| Chinese and English ultra-lightweight PP-OCRv2 model(11.6M) | ch_ppocrv2_xx |Mobile&Server|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/chinese/ch_ppocr_mobile_v2.1_det_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/chinese/ch_ppocr_mobile_v2.1_det_distill_train.tar)| [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/chinese/ch_ppocr_mobile_v2.1_rec_train.tar)|
| Chinese and English general OCR model (143.4M) | ch_ppocr_server_v2.0_xx | Server |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_traingit.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
| Chinese and English ultra-lightweight PP-OCR model (9.4M) | ch_ppocr_mobile_v2.0_xx | Mobile & server |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar)|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
| Chinese and English general PP-OCR model (143.4M) | ch_ppocr_server_v2.0_xx | Server |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_traingit.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
For more model downloads (including multiple languages), please refer to [PP-OCR v2.1 series model downloads](./doc/doc_en/models_list_en.md).
For more model downloads (including multiple languages), please refer to [PP-OCR series model downloads](./doc/doc_en/models_list_en.md).
For a new language request, please refer to [Guideline for new language_requests](#language_requests).
For a new language request, please refer to [Guideline for new language_requests](#language_requests).
...
@@ -143,17 +137,18 @@ For a new language request, please refer to [Guideline for new language_requests
...
@@ -143,17 +137,18 @@ For a new language request, please refer to [Guideline for new language_requests
-[License](#LICENSE)
-[License](#LICENSE)
-[Contribution](#CONTRIBUTION)
-[Contribution](#CONTRIBUTION)
<aname="PP-OCRv2"></a>
## PP-OCRv2 Pipeline
<divalign="center">
<imgsrc="./doc/ppocrv2_framework.jpg"width="800">
</div>
<aname="PP-OCR-Pipeline"></a>
[1] PP-OCR is a practical ultra-lightweight OCR system. It is mainly composed of three parts: DB text detection, detection frame correction and CRNN text recognition. The system adopts 19 effective strategies from 8 aspects including backbone network selection and adjustment, prediction head design, data augmentation, learning rate transformation strategy, regularization parameter selection, pre-training model use, and automatic model tailoring and quantization to optimize and slim down the models of each module (as shown in the green box above). The final results are an ultra-lightweight Chinese and English OCR model with an overall size of 3.5M and a 2.8M English digital OCR model. For more details, please refer to the PP-OCR technical article (https://arxiv.org/abs/2009.09941).
## PP-OCR Pipeline
[2] On the basis of PP-OCR, PP-OCRv2 is further optimized in five aspects. The detection model adopts CML(Collaborative Mutual Learning) knowledge distillation strategy and CopyPaste data expansion strategy; The recognition model adopts LCNet lightweight backbone network, U-DML knowledge distillation strategy and enhanced CTC loss function improvement (as shown in the red box above), which further improves the inference speed and prediction effect. For more details, please refer to the technical report of PP-OCRv2 (arXiv link is coming soon).
<divalign="center">
<imgsrc="./doc/ppocr_framework.png"width="800">
</div>
PP-OCR is a practical ultra-lightweight OCR system. It is mainly composed of three parts: DB text detection[2], detection frame correction and CRNN text recognition[7]. The system adopts 19 effective strategies from 8 aspects including backbone network selection and adjustment, prediction head design, data augmentation, learning rate transformation strategy, regularization parameter selection, pre-training model use, and automatic model tailoring and quantization to optimize and slim down the models of each module. The final results are an ultra-lightweight Chinese and English OCR model with an overall size of 3.5M and a 2.8M English digital OCR model. For more details, please refer to the PP-OCR technical article (https://arxiv.org/abs/2009.09941). Besides, The implementation of the FPGM Pruner [8] and PACT quantization [9] is based on [PaddleSlim](https://github.com/PaddlePaddle/PaddleSlim).
- 2021.9.7 release PaddleOCR v2.3, [PP-OCRv2](#PP-OCRv2) is proposed. The CPU inference speed of PP-OCRv2 is 220% higher than that of PP-OCR server. The F-score of PP-OCRv2 is 7% higher than that of PP-OCR mobile.
- 2021.8.3 released PaddleOCR v2.2, add a new structured documents analysis toolkit, i.e., [PP-Structure](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/ppstructure/README.md), support layout analysis and table recognition (One-key to export chart images to Excel files).
- 2021.4.8 release end-to-end text recognition algorithm [PGNet](https://www.aaai.org/AAAI21Papers/AAAI-2885.WangP.pdf) which is published in AAAI 2021. Find tutorial [here](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_en/pgnet_en.md);release multi language recognition [models](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_en/multi_languages_en.md), support more than 80 languages recognition; especically, the performance of [English recognition model](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_en/models_list_en.md#English) is Optimized.
- 2021.1.21 update more than 25+ multilingual recognition models [models list](./doc/doc_en/models_list_en.md), including:English, Chinese, German, French, Japanese,Spanish,Portuguese Russia Arabic and so on. Models for more languages will continue to be updated [Develop Plan](https://github.com/PaddlePaddle/PaddleOCR/issues/1048).
- 2020.12.15 update Data synthesis tool, i.e., [Style-Text](../../StyleText/README.md),easy to synthesize a large number of images which are similar to the target scene image.
- 2020.12.15 update Data synthesis tool, i.e., [Style-Text](../../StyleText/README.md),easy to synthesize a large number of images which are similar to the target scene image.
- 2020.11.25 Update a new data annotation tool, i.e., [PPOCRLabel](../../PPOCRLabel/README.md), which is helpful to improve the labeling efficiency. Moreover, the labeling results can be used in training of the PP-OCR system directly.
- 2020.11.25 Update a new data annotation tool, i.e., [PPOCRLabel](../../PPOCRLabel/README.md), which is helpful to improve the labeling efficiency. Moreover, the labeling results can be used in training of the PP-OCR system directly.
- 2020.9.22 Update the PP-OCR technical article, https://arxiv.org/abs/2009.09941
- 2020.9.22 Update the PP-OCR technical article, https://arxiv.org/abs/2009.09941
{kind=link}
{kind=link}
{kind=link}
