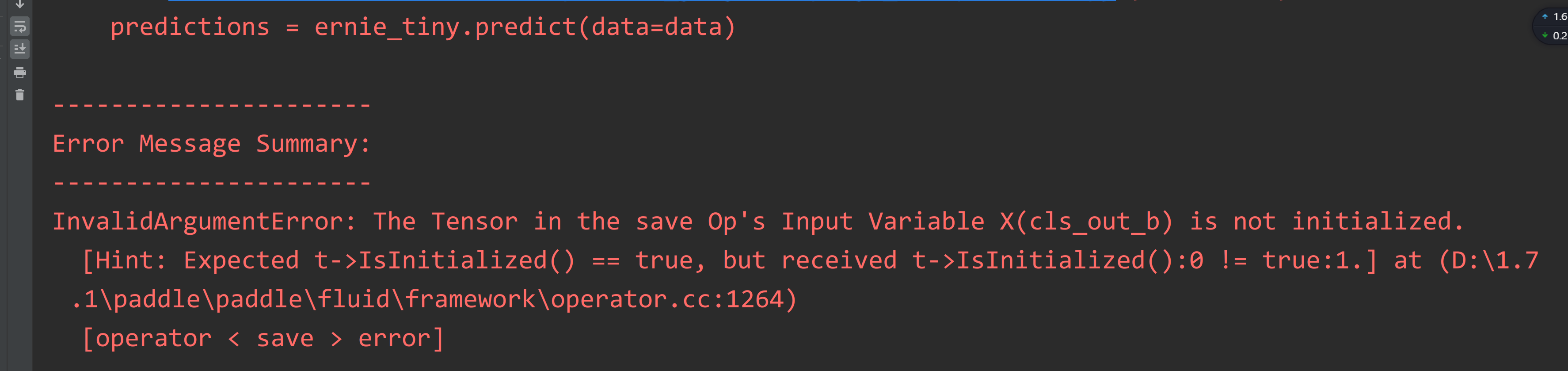
模型部署中模型预加载错误
Created by: Malestudents
模型代码
-- coding:utf-8 --
Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""Finetuning on classification task """ from future import absolute_import from future import division from future import print_function
import os
import numpy as np from paddlehub.common.logger import logger from paddlehub.module.module import moduleinfo, serving import paddlehub as hub
@moduleinfo( name="ERNIEFinetuned", version="1.0.0", summary="ERNIE tiny which was fine-tuned on the chnsenticorp dataset.", author="anonymous", author_email="", type="nlp/semantic_model") class ERNIEFinetuned(hub.Module): def _initialize(self, ckpt_dir="ckpt_ner", num_class=3, max_seq_len=128, use_gpu=False, batch_size=16): self.ckpt_dir = os.path.join(self.directory, ckpt_dir) self.num_class = num_class self.MAX_SEQ_LEN = max_seq_len
self.params_path = os.path.join(self.ckpt_dir, 'best_model')
# Load Paddlehub ERNIE Tiny pretrained model
self.module = hub.Module(name='ernie')
inputs, outputs, program = self.module.context(max_seq_len=128)
# Download dataset and use accuracy as metrics
# Choose dataset: GLUE/XNLI/ChinesesGLUE/NLPCC-DBQA/LCQMC
# metric should be acc, f1 or matthews
# For ernie_tiny, it use sub-word to tokenize chinese sentence
# If not ernie tiny, sp_model_path and word_dict_path should be set None
reader = hub.reader.SequenceLabelReader(
vocab_path=self.module.get_vocab_path(),
max_seq_len=128)
# Construct transfer learning network
# Use "pooled_output" for classification tasks on an entire sentence.
# Use "sequence_output" for token-level output.
sequence_output = outputs["sequence_output"]
# Setup feed list for data feeder
# Must feed all the tensor of module need
feed_list = [
inputs["input_ids"].name,
inputs["position_ids"].name,
inputs["segment_ids"].name,
inputs["input_mask"].name,
]
strategy = hub.AdamWeightDecayStrategy(
weight_decay=0.01,
warmup_proportion=0.1,
learning_rate=5e-5)
# Setup runing config for PaddleHub Finetune API
config = hub.RunConfig(
use_cuda=False,
num_epoch=1,
checkpoint_dir=self.ckpt_dir,
batch_size=16,
eval_interval=50,
strategy=strategy)
# Define a classfication finetune task by PaddleHub's API
self.cls_task = hub.SequenceLabelTask(
data_reader=reader,
feature=sequence_output,
feed_list=feed_list,
add_crf=True,
max_seq_len=128,
num_classes=3,
config=config)
def predict(self, data, return_result=False, accelerate_mode=True):
"""
Get prediction results
"""
run_states = self.cls_task.predict(
data=data,
return_result = return_result,
accelerate_mode = accelerate_mode)
print(run_states)
return result1if name == "main":
ernie_tiny = ERNIEFinetuned(
ckpt_dir="./ckpt_ner", num_class=3)
# Data to be prdicted
data=[]
result = '梅小二主治医师查房记录'
data.append(["\002".join(result)])
print(data)
predictions = ernie_tiny.predict(data=data)
print(predictions)
错误代码: