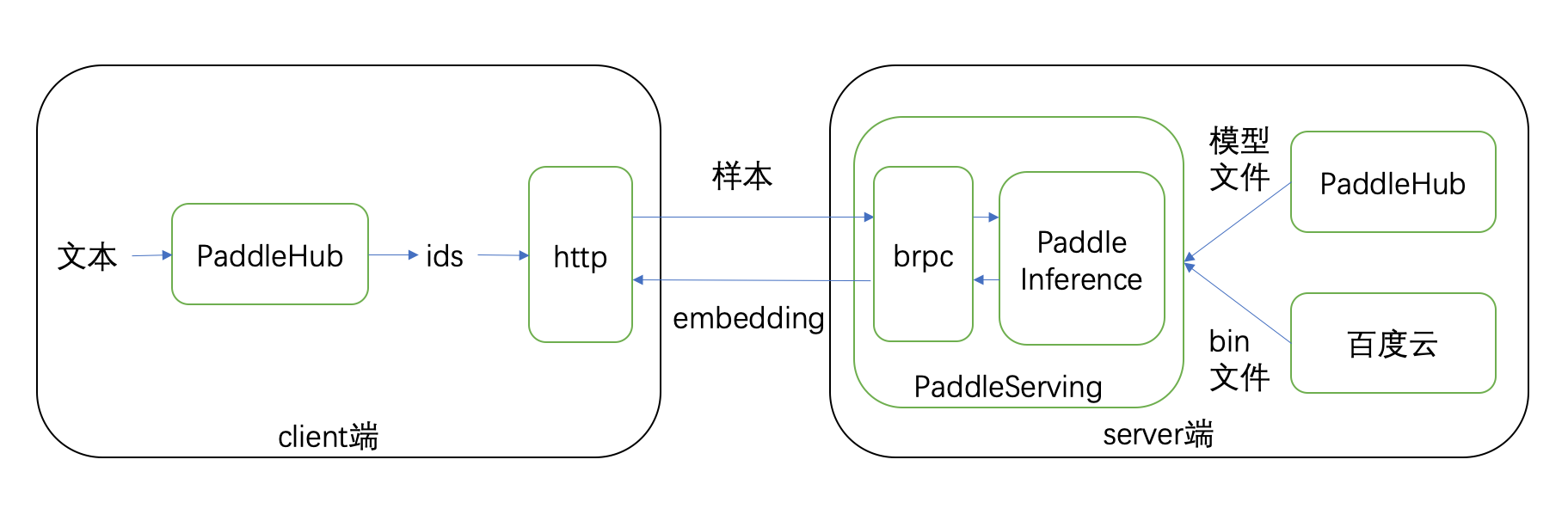
Bert as Service是基于Paddle Serving框架的快速部署模型远程计算服务方案,可将embedding过程通过调用API接口的方式实现,减少了对机器资源的依赖。使用PaddleHub可在服务器上一键部署`Bert as Service`服务,在另外的普通机器上通过客户端接口即可轻松的获取文本对应的embedding数据。
> Q : 启动时显示"Check out http://yq01-gpu-255-129-12-00.epc.baidu.com:8887 in web
browser.",这个页面有什么作用。
> A : 这是`BRPC`的内置服务,主要用于查看请求数、资源占用等信息,可对server端性能有大致了解,具体信息可查看[BRPC内置服务](https://github.com/apache/incubator-brpc/blob/master/docs/cn/builtin_service.md)。
{kind=link}