Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleHub
提交
e80dbf15
P
PaddleHub
项目概览
PaddlePaddle
/
PaddleHub
大约 2 年 前同步成功
通知
285
Star
12117
Fork
2091
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
200
列表
看板
标记
里程碑
合并请求
4
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleHub
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
200
Issue
200
列表
看板
标记
里程碑
合并请求
4
合并请求
4
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
e80dbf15
编写于
9月 17, 2021
作者:
C
chenjian
提交者:
GitHub
9月 17, 2021
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Update the image gan modules docs according to the template (#1602)
上级
6ca472e5
变更
13
隐藏空白更改
内联
并排
Showing
13 changed file
with
1387 addition
and
971 deletion
+1387
-971
modules/image/Image_gan/style_transfer/stylepro_artistic/README.md
...mage/Image_gan/style_transfer/stylepro_artistic/README.md
+158
-122
modules/thirdparty/image/Image_gan/gan/stgan_bald/README.md
modules/thirdparty/image/Image_gan/gan/stgan_bald/README.md
+106
-50
modules/thirdparty/image/Image_gan/style_transfer/Photo2Cartoon/README.md
...ty/image/Image_gan/style_transfer/Photo2Cartoon/README.md
+96
-53
modules/thirdparty/image/Image_gan/style_transfer/U2Net_Portrait/README.md
...y/image/Image_gan/style_transfer/U2Net_Portrait/README.md
+103
-59
modules/thirdparty/image/Image_gan/style_transfer/UGATIT_100w/README.md
...arty/image/Image_gan/style_transfer/UGATIT_100w/README.md
+96
-78
modules/thirdparty/image/Image_gan/style_transfer/animegan_v1_hayao_60/README.md
...e/Image_gan/style_transfer/animegan_v1_hayao_60/README.md
+106
-80
modules/thirdparty/image/Image_gan/style_transfer/animegan_v2_hayao_64/README.md
...e/Image_gan/style_transfer/animegan_v2_hayao_64/README.md
+104
-80
modules/thirdparty/image/Image_gan/style_transfer/animegan_v2_hayao_99/README.md
...e/Image_gan/style_transfer/animegan_v2_hayao_99/README.md
+106
-80
modules/thirdparty/image/Image_gan/style_transfer/animegan_v2_paprika_74/README.md
...Image_gan/style_transfer/animegan_v2_paprika_74/README.md
+103
-80
modules/thirdparty/image/Image_gan/style_transfer/animegan_v2_paprika_98/README.md
...Image_gan/style_transfer/animegan_v2_paprika_98/README.md
+105
-80
modules/thirdparty/image/Image_gan/style_transfer/animegan_v2_shinkai_33/README.md
...Image_gan/style_transfer/animegan_v2_shinkai_33/README.md
+105
-80
modules/thirdparty/image/Image_gan/style_transfer/animegan_v2_shinkai_53/README.md
...Image_gan/style_transfer/animegan_v2_shinkai_53/README.md
+105
-80
modules/thirdparty/image/semantic_segmentation/FCN_HRNet_W18_Face_Seg/README.md
...ge/semantic_segmentation/FCN_HRNet_W18_Face_Seg/README.md
+94
-49
未找到文件。
modules/image/Image_gan/style_transfer/stylepro_artistic/README.md
浏览文件 @
e80dbf15
<p
align=
"center"
>
# stylepro_artistic
<img
src=
"https://paddlehub.bj.bcebos.com/resources/style.png"
hspace=
'10'
/>
<br
/>
</p>
|模型名称|stylepro_artistic|
| :--- | :---: |
更多详情请参考StyleProNet论文
[
https://arxiv.org/abs/2003.07694
](
https://arxiv.org/abs/2003.07694
)
|类别|图像 - 图像生成|
|网络|StyleProNet|
## 命令行预测
|数据集|MS-COCO + WikiArt|
|是否支持Fine-tuning|否|
```
|模型大小|28MB|
hub run stylepro_artistic --选项 选项值
|最新更新日期|2021-02-26|
```
|数据指标|-|
**选项说明:**
## 一、模型基本信息
*
content (str): 待转换风格的图片的存放路径;
*
styles (str): 作为底色的风格图片的存放路径,不同图片用英文逗号
`,`
间隔;
-
### 应用效果展示
*
weights (float, optional) : styles 的权重,用英文逗号
`,`
间隔;
-
样例结果示例:
*
alpha (float, optioal):转换的强度,
\[
0, 1
\]
之间,默认值为1;
<p
align=
"center"
>
*
use
\_
gpu (bool, optional): 是否使用 gpu,默认为 False;
<img
src=
"https://paddlehub.bj.bcebos.com/resources/style.png"
width=
'80%'
hspace=
'10'
/>
<br
/>
*
output
\_
dir (str, optional): 输出目录,默认为 transfer
\_
result;
</p>
*
visualization (bool, optioanl): 是否将结果保存为图片,默认为 True。
-
### 模型介绍
## API
-
艺术风格迁移模型可以将给定的图像转换为任意的艺术风格。本模型StyleProNet整体采用全卷积神经网络架构(FCNs),通过encoder-decoder重建艺术风格图片。StyleProNet的核心是无参数化的内容-风格融合算法Style Projection,模型规模小,响应速度快。模型训练的损失函数包含style loss、content perceptual loss以及content KL loss,确保模型高保真还原内容图片的语义细节信息与风格图片的风格信息。预训练数据集采用MS-COCO数据集作为内容端图像,WikiArt数据集作为风格端图像。更多详情请参考StyleProNet论文
[
https://arxiv.org/abs/2003.07694
](
https://arxiv.org/abs/2003.07694
)
。
```
python
def
style_transfer
(
images
=
None
,
paths
=
None
,
## 二、安装
alpha
=
1
,
use_gpu
=
False
,
-
### 1、环境依赖
visualization
=
False
,
output_dir
=
'transfer_result'
):
-
paddlepaddle >= 1.6.2
```
-
paddlehub >= 1.6.0 |
[
如何安装paddlehub
](
../../../../docs/docs_ch/get_start/installation.rst
)
对图片进行风格转换。
-
### 2、安装
**参数**
-
```shell
*
images (list
\[
dict
\]
): ndarray 格式的图片数据。每一个元素都为一个 dict,有关键字 content, styles, weights(可选),相应取值为:
$ hub install stylepro_artistic
*
content (numpy.ndarray): 待转换的图片,shape 为
\[
H, W, C
\]
,BGR格式;
```
*
styles (list
\[
numpy.ndarray
\]
) : 作为底色的风格图片组成的列表,各个图片数组的shape 都是
\[
H, W, C
\]
,BGR格式;
-
如您安装时遇到问题,可参考:
[
零基础windows安装
](
../../../../docs/docs_ch/get_start/windows_quickstart.md
)
*
weights (list
\[
float
\]
, optioal) : 各个 style 对应的权重。当不设置 weights 时,默认各个 style 有着相同的权重;
|
[
零基础Linux安装
](
../../../../docs/docs_ch/get_start/linux_quickstart.md
)
|
[
零基础MacOS安装
](
../../../../docs/docs_ch/get_start/mac_quickstart.md
)
*
paths (list
\[
str
\]
): 图片的路径。每一个元素都为一个 dict,有关键字 content, styles, weights(可选),相应取值为:
*
content (str): 待转换的图片的路径;
## 三、模型API预测
*
styles (list
\[
str
\]
) : 作为底色的风格图片的路径;
*
weights (list
\[
float
\]
, optioal) : 各个 style 对应的权重。当不设置 weights 时,各个 style 的权重相同;
-
### 1、命令行预测
*
alpha (float) : 转换的强度,
\[
0, 1
\]
之间,默认值为1;
*
use
\_
gpu (bool): 是否使用 GPU;
-
```shell
*
visualization (bool): 是否将结果保存为图片,默认为 False;
$ hub run stylepro_artistic --input_path "/PATH/TO/IMAGE"
*
output
\_
dir (str): 图片的保存路径,默认设为 transfer
\_
result 。
```
-
通过命令行方式实现风格转换模型的调用,更多请见
[
PaddleHub命令行指令
](
../../../../docs/docs_ch/tutorial/cmd_usage.rst
)
**返回**
-
### 2、代码示例
*
res (list
\[
dict
\]
): 识别结果的列表,列表中每一个元素为 OrderedDict,关键字有 date, save
\_
path,相应取值为:
-
```python
*
save
\_
path (str): 保存图片的路径;
import paddlehub as hub
*
data (numpy.ndarray): 风格转换的图片数据。
import cv2
```
python
stylepro_artistic = hub.Module(name="stylepro_artistic")
def
save_inference_model
(
dirname
,
result = stylepro_artistic.style_transfer(
model_filename
=
None
,
params_filename
=
None
,
combined
=
True
)
```
将模型保存到指定路径。
**参数**
*
dirname: 存在模型的目录名称
*
model
\_
filename: 模型文件名称,默认为
\_\_
model
\_\_
*
params
\_
filename: 参数文件名称,默认为
\_\_
params
\_\_
(仅当
`combined`
为True时生效)
*
combined: 是否将参数保存到统一的一个文件中
## 代码示例
```
python
import
paddlehub
as
hub
import
cv2
stylepro_artistic
=
hub
.
Module
(
name
=
"stylepro_artistic"
)
result
=
stylepro_artistic
.
style_transfer
(
images=[{
images=[{
'content': cv2.imread('/PATH/TO/CONTENT_IMAGE'),
'content': cv2.imread('/PATH/TO/CONTENT_IMAGE'),
'styles': [cv2.imread('/PATH/TO/STYLE_IMAGE')]
'styles': [cv2.imread('/PATH/TO/STYLE_IMAGE')]
}])
}])
# or
# or
# result = stylepro_artistic.style_transfer(
# result = stylepro_artistic.style_transfer(
# paths=[{
# paths=[{
# 'content': '/PATH/TO/CONTENT_IMAGE',
# 'content': '/PATH/TO/CONTENT_IMAGE',
# 'styles': ['/PATH/TO/STYLE_IMAGE']
# 'styles': ['/PATH/TO/STYLE_IMAGE']
# }])
# }])
```
```
-
### 3、API
-
```python
def style_transfer(images=None,
paths=None,
alpha=1,
use_gpu=False,
visualization=False,
output_dir='transfer_result')
```
- 对图片进行风格转换。
- **参数**
- images (list\[dict\]): ndarray 格式的图片数据。每一个元素都为一个 dict,有关键字 content, styles, weights(可选),相应取值为:
- content (numpy.ndarray): 待转换的图片,shape 为 \[H, W, C\],BGR格式;<br/>
- styles (list\[numpy.ndarray\]) : 作为底色的风格图片组成的列表,各个图片数组的shape 都是 \[H, W, C\],BGR格式;<br/>
- weights (list\[float\], optioal) : 各个 style 对应的权重。当不设置 weights 时,默认各个 style 有着相同的权重;<br/>
- paths (list\[str\]): 图片的路径。每一个元素都为一个 dict,有关键字 content, styles, weights(可选),相应取值为:
- content (str): 待转换的图片的路径;<br/>
- styles (list\[str\]) : 作为底色的风格图片的路径;<br/>
- weights (list\[float\], optioal) : 各个 style 对应的权重。当不设置 weights 时,各个 style 的权重相同;<br/>
- alpha (float) : 转换的强度,\[0, 1\] 之间,默认值为1;<br/>
- use\_gpu (bool): 是否使用 GPU;<br/>
- visualization (bool): 是否将结果保存为图片,默认为 False; <br/>
- output\_dir (str): 图片的保存路径,默认设为 transfer\_result。
**NOTE:** paths和images两个参数选择其一进行提供数据
## 服务部署
- **返回**
PaddleHub Serving可以部署一个在线风格转换服务。
- res (list\[dict\]): 识别结果的列表,列表中每一个元素为 OrderedDict,关键字有 date, save\_path,相应取值为:
- save\_path (str): 保存图片的路径
- data (numpy.ndarray): 风格转换的图片数据
## 第一步:启动PaddleHub Serving
运行启动命令:
-
```python
```
shell
def save_inference_model(dirname,
$
hub serving start
-m
stylepro_artistic
model_filename=None,
```
params_filename=None,
combined=True)
```
-
将模型保存到指定路径。
这样就完成了一个风格转换服务化API的部署,默认端口号为8866。
- **参数**
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置环境变量 CUDA
\_
VISIBLE
\_
DEVICES ,否则不用设置。
- dirname: 存在模型的目录名称; <br/>
- model\_filename: 模型文件名称,默认为\_\_model\_\_; <br/>
- params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效);<br/>
- combined: 是否将参数保存到统一的一个文件中。
## 第二步:发送预测请求
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
## 四、服务部署
```
python
-
PaddleHub Serving可以部署一个在线风格转换服务。
import
requests
import
json
import
cv2
import
base64
import
numpy
as
np
-
### 第一步:启动PaddleHub Serving
def
cv2_to_base64
(
image
):
-
运行启动命令:
data
=
cv2
.
imencode
(
'.jpg'
,
image
)[
1
]
-
```shell
return
base64
.
b64encode
(
data
.
tostring
()).
decode
(
'utf8'
)
$ hub serving start -m stylepro_artistic
```
-
这样就完成了一个风格转换服务化API的部署,默认端口号为8866。
def
base64_to_cv2
(
b64str
):
-
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
data
=
base64
.
b64decode
(
b64str
.
encode
(
'utf8'
))
data
=
np
.
fromstring
(
data
,
np
.
uint8
)
data
=
cv2
.
imdecode
(
data
,
cv2
.
IMREAD_COLOR
)
return
data
-
### 第二步:发送预测请求
data
=
{
'images'
:[
-
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
```python
import requests
import json
import cv2
import base64
import numpy as np
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')
def base64_to_cv2(b64str):
data = base64.b64decode(b64str.encode('utf8'))
data = np.fromstring(data, np.uint8)
data = cv2.imdecode(data, cv2.IMREAD_COLOR)
return data
# 发送HTTP请求
data = {'images':[
{
{
'content':cv2_to_base64(cv2.imread('/PATH/TO/CONTENT_IMAGE')),
'content':cv2_to_base64(cv2.imread('/PATH/TO/CONTENT_IMAGE')),
'styles':[cv2_to_base64(cv2.imread('/PATH/TO/STYLE_IMAGE'))]
'styles':[cv2_to_base64(cv2.imread('/PATH/TO/STYLE_IMAGE'))]
}
}
]}
]}
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/stylepro_artistic"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
print(base64_to_cv2(r.json()["results"][0]['data']))
```
headers
=
{
"Content-type"
:
"application/json"
}
## 五、更新历史
url
=
"http://127.0.0.1:8866/predict/stylepro_artistic"
r
=
requests
.
post
(
url
=
url
,
headers
=
headers
,
data
=
json
.
dumps
(
data
))
print
(
base64_to_cv2
(
r
.
json
()[
"results"
][
0
][
'data'
]))
*
1.0.0
```
### 依赖
初始发布
paddlepaddle >= 1.6.2
*
1.0.1
paddlehub >= 1.6.0
-
```shell
$ hub install stylepro_artistic==1.0.1
```
modules/thirdparty/image/Image_gan/gan/stgan_bald/README.md
浏览文件 @
e80dbf15
# stgan_bald
# stgan_bald
基于PaddleHub的秃头生成器
# 模型概述
秃头生成器(stgan_bald),该模型可自动根据图像生成1年、3年、5年的秃头效果。
# 模型效果:
详情请查看此链接:https://aistudio.baidu.com/aistudio/projectdetail/1145381
|模型名称|stgan_bald|
| :--- | :---: |
|类别|图像 - 图像生成|
|网络|STGAN|
|数据集|CelebA|
|是否支持Fine-tuning|否|
|模型大小|287MB|
|最新更新日期|2021-02-26|
|数据指标|-|
本模型为大家提供了小程序,欢迎大家体验

## 一、模型基本信息
# 选择模型版本进行安装
-
### 应用效果展示
$ hub install stgan_bald==1.0.0
-
详情请查看此链接:https://aistudio.baidu.com/aistudio/projectdetail/1145381
# Module API说明
def bald(self,
-
### 模型介绍
images=None,
paths=None,
-
stgan_bald 以STGAN 为模型,使用 CelebA 数据集训练完成,该模型可自动根据图像生成1年、3年、5年的秃头效果。
use_gpu=False,
visualization=False):
秃头生成器API预测接口,预测输入一张人像,输出三张秃头效果(1年、3年、5年)
## 二、安装
## 参数
images (list(numpy.ndarray)): 图像数据,每个图像的形状为[H,W,C],颜色空间为BGR。
-
### 1、环境依赖
paths (list[str]): 图像的路径。
use_gpu (bool): 是否使用gpu。
-
paddlepaddle >= 1.8.2
visualization (bool): 是否保存图像。
## 返回
-
paddlehub >= 1.8.0 |
[
如何安装paddlehub
](
../../../../docs/docs_ch/get_start/installation.rst
)
data_0 ([numpy.ndarray]):秃头一年的预测结果图。
data_1 ([numpy.ndarray]):秃头三年的预测结果图。
-
### 2、安装
data_2 ([numpy.ndarray]):秃头五年的预测结果图。
# API预测代码示例
-
```shell
$ hub install stgan_bald
```
-
如您安装时遇到问题,可参考:
[
零基础windows安装
](
../../../../docs/docs_ch/get_start/windows_quickstart.md
)
|
[
零基础Linux安装
](
../../../../docs/docs_ch/get_start/linux_quickstart.md
)
|
[
零基础MacOS安装
](
../../../../docs/docs_ch/get_start/mac_quickstart.md
)
## 三、模型API预测
-
### 1、代码示例
-
```python
import paddlehub as hub
import paddlehub as hub
import cv2
import cv2
stgan_bald = hub.Module(name='stgan_bald')
stgan_bald = hub.Module(name="stgan_bald")
im = cv2.imread('/PATH/TO/IMAGE')
result = stgan_bald.bald(images=[cv2.imread('/PATH/TO/IMAGE')])
res = stgan_bald.bald(images=[im],visualization=True)
# or
# 服务部署
# result = stgan_bald.bald(paths=['/PATH/TO/IMAGE'])
## 第一步:启动PaddleHub Serving
```
$ hub serving start -m stgan_bald
## 第二步:发送预测请求
-
### 2、API
-
```python
def bald(images=None,
paths=None,
use_gpu=False,
visualization=False,
output_dir="bald_output")
```
- 秃头生成器API预测接口, 预测输入一张人像,输出三张秃头效果(1年、3年、5年)。
- **参数**
- images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\];<br/>
- paths (list\[str\]): 图片的路径;<br/>
- use\_gpu (bool): 是否使用 GPU;<br/>
- visualization (bool): 是否将结果保存为图片,默认为 False; <br/>
- output\_dir (str): 图片的保存路径,默认设为bald\_output。
**NOTE:** paths和images两个参数选择其一进行提供数据
- **返回**
- res (list\[numpy.ndarray\]): 输出图像数据,ndarray.shape 为 \[H, W, C\]
## 四、服务部署
-
PaddleHub Serving可以部署一个秃头生成器服务。
-
### 第一步:启动PaddleHub Serving
-
运行启动命令:
-
```shell
$ hub serving start -m stgan_bald
```
-
这样就完成了一个秃头生成器API的部署,默认端口号为8866。
-
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
-
### 第二步:发送预测请求
-
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
```python
import requests
import requests
import json
import json
import base64
import cv2
import cv2
import base64
import numpy as np
import numpy as np
def cv2_to_base64(image):
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')
return base64.b64encode(data.tostring()).decode('utf8')
def base64_to_cv2(b64str):
def base64_to_cv2(b64str):
data = base64.b64decode(b64str.encode('utf8'))
data = base64.b64decode(b64str.encode('utf8'))
data = np.fromstring(data, np.uint8)
data = np.fromstring(data, np.uint8)
data = cv2.imdecode(data, cv2.IMREAD_COLOR)
data = cv2.imdecode(data, cv2.IMREAD_COLOR)
return data
return data
# 发送HTTP请求
# 发送HTTP请求
org_im = cv2.imread('/PATH/TO/IMAGE')
data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
data = {'images':[cv2_to_base64(org_im)]}
headers = {"Content-type": "application/json"}
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/stgan_bald"
url = "http://127.0.0.1:8866/predict/stgan_bald"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
r = requests.post(url=url, headers=headers, data=json.dumps(data))
...
@@ -67,14 +123,14 @@ $ hub serving start -m stgan_bald
...
@@ -67,14 +123,14 @@ $ hub serving start -m stgan_bald
three_year =cv2.cvtColor(base64_to_cv2(r.json()["results"]['data_1']), cv2.COLOR_RGB2BGR)
three_year =cv2.cvtColor(base64_to_cv2(r.json()["results"]['data_1']), cv2.COLOR_RGB2BGR)
five_year =cv2.cvtColor(base64_to_cv2(r.json()["results"]['data_2']), cv2.COLOR_RGB2BGR)
five_year =cv2.cvtColor(base64_to_cv2(r.json()["results"]['data_2']), cv2.COLOR_RGB2BGR)
cv2.imwrite("stgan_bald_server.png", one_year)
cv2.imwrite("stgan_bald_server.png", one_year)
```
# 贡献者
刘炫、彭兆帅、郑博培
# 依赖
paddlepaddle >= 1.8.2
paddlehub >= 1.8.0
## 五、更新历史
# 查看代码
*
1.0.0
[
基于PaddleHub的秃头生成器
](
https://github.com/PaddlePaddle/PaddleHub/tree/release/v1.8/hub_module/modules/image/gan/stgan_bald
)
初始发布
-
```shell
$ hub install stgan_bald==1.0.0
```
modules/thirdparty/image/Image_gan/style_transfer/Photo2Cartoon/README.md
浏览文件 @
e80dbf15
## 概述
# Photo2Cartoon
*
本模型封装自
[
小视科技photo2cartoon项目的paddlepaddle版本
](
https://github.com/minivision-ai/photo2cartoon-paddle
)
*
人像卡通风格渲染的目标是,在保持原图像ID信息和纹理细节的同时,将真实照片转换为卡通风格的非真实感图像。我们的思路是,从大量照片/卡通数据中习得照片到卡通画的映射。一般而言,基于成对数据的pix2pix方法能达到较好的图像转换效果,但本任务的输入输出轮廓并非一一对应。例如卡通风格的眼睛更大、下巴更瘦;且成对的数据绘制难度大、成本较高,因此我们采用unpaired image translation方法来实现。模型结构方面,在U-GAT-IT的基础上,我们在编码器之前和解码器之后各增加了2个hourglass模块,渐进地提升模型特征抽象和重建能力。由于实验数据较为匮乏,为了降低训练难度,我们将数据处理成固定的模式。首先检测图像中的人脸及关键点,根据人脸关键点旋转校正图像,并按统一标准裁剪,再将裁剪后的头像输入人像分割模型(基于PaddleSeg框架训练)去除背景
|模型名称|Photo2Cartoon|
| :--- | :---: |
## 效果展示
|类别|图像 - 图像生成|
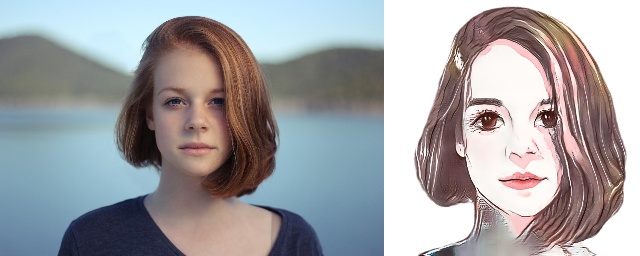
|网络|U-GAT-IT|
|数据集|cartoon_data|
## API
|是否支持Fine-tuning|否|
```
python
|模型大小|205MB|
def
Cartoon_GEN
(
|最新更新日期|2021-02-26|
images
=
None
,
|数据指标|-|
paths
=
None
,
batch_size
=
1
,
output_dir
=
'output'
,
## 一、模型基本信息
visualization
=
False
,
use_gpu
=
False
):
-
### 应用效果展示
```
-
样例结果示例:
人像卡通化图像生成 API
<p
align=
"center"
>
<img
src=
"https://img-blog.csdnimg.cn/20201224164040624.jpg"
hspace=
'10'
/>
<br
/>
**参数**
</p>
*
images (list[np.ndarray]) : 输入图像数据列表(BGR)
*
paths (list[str]) : 输入图像路径列表
*
batch_size (int) : 数据批大小
*
output_dir (str) : 可视化图像输出目录
-
### 模型介绍
*
visualization (bool) : 是否可视化
*
use_gpu (bool) : 是否使用 GPU 进行推理
-
本模型封装自
[
小视科技photo2cartoon项目的paddlepaddle版本
](
https://github.com/minivision-ai/photo2cartoon-paddle
)
。
**返回**
*
results (list[np.ndarray]): 输出图像数据列表
## 二、安装
**代码示例**
-
### 1、环境依赖
```
python
import
cv2
-
paddlepaddle >= 2.0.0
import
paddlehub
as
hub
-
paddlehub >= 2.0.0 |
[
如何安装paddlehub
](
../../../../docs/docs_ch/get_start/installation.rst
)
model
=
hub
.
Module
(
name
=
'Photo2Cartoon'
)
-
### 2、安装
result
=
model
.
Cartoon_GEN
(
images
=
[
cv2
.
imread
(
'/PATH/TO/IMAGE'
)],
-
```shell
paths
=
None
,
$ hub install Photo2Cartoon
batch_size
=
1
,
```
output_dir
=
'output'
,
-
如您安装时遇到问题,可参考:
[
零基础windows安装
](
../../../../docs/docs_ch/get_start/windows_quickstart.md
)
visualization
=
True
,
|
[
零基础Linux安装
](
../../../../docs/docs_ch/get_start/linux_quickstart.md
)
|
[
零基础MacOS安装
](
../../../../docs/docs_ch/get_start/mac_quickstart.md
)
use_gpu
=
False
)
```
## 三、模型API预测
## 查看代码
-
### 1、代码示例
https://github.com/PaddlePaddle/PaddleSeg
https://github.com/minivision-ai/photo2cartoon-paddle
-
```python
import paddlehub as hub
## 依赖
import cv2
paddlepaddle >= 2.0.0rc0
paddlehub >= 2.0.0b1
model = hub.Module(name="Photo2Cartoon")
result = model.Cartoon_GEN(images=[cv2.imread('/PATH/TO/IMAGE')])
# or
# result = model.Cartoon_GEN(paths=['/PATH/TO/IMAGE'])
```
-
### 2、API
-
```python
def Cartoon_GEN(images=None,
paths=None,
batch_size=1,
output_dir='output',
visualization=False,
use_gpu=False):
```
-
人像卡通化图像生成API。
-
**参数**
-
images (list
\[
numpy.ndarray
\]
): 图片数据,ndarray.shape 为
\[
H, W, C
\]
;
<br/>
-
paths (list
\[
str
\]
): 输入图像路径;
<br/>
-
output
\_
dir (str): 图片的保存路径,默认设为 output;
<br/>
-
batch_size (int) : batch大小;
<br/>
-
visualization (bool) : 是否将结果保存为图片文件;;
<br/>
-
use_gpu (bool) : 是否使用 GPU 进行推理。
**NOTE:**
paths和images两个参数选择其一进行提供数据
-
**返回**
-
res (list
\[
numpy.ndarray
\]
): 输出图像数据,ndarray.shape 为
\[
H, W, C
\]
## 四、更新历史
*
1.0.0
初始发布
-
```shell
$ hub install Photo2Cartoon==1.0.0
```
modules/thirdparty/image/Image_gan/style_transfer/U2Net_Portrait/README.md
浏览文件 @
e80dbf15
## 概述
# U2Net_Portrait
*
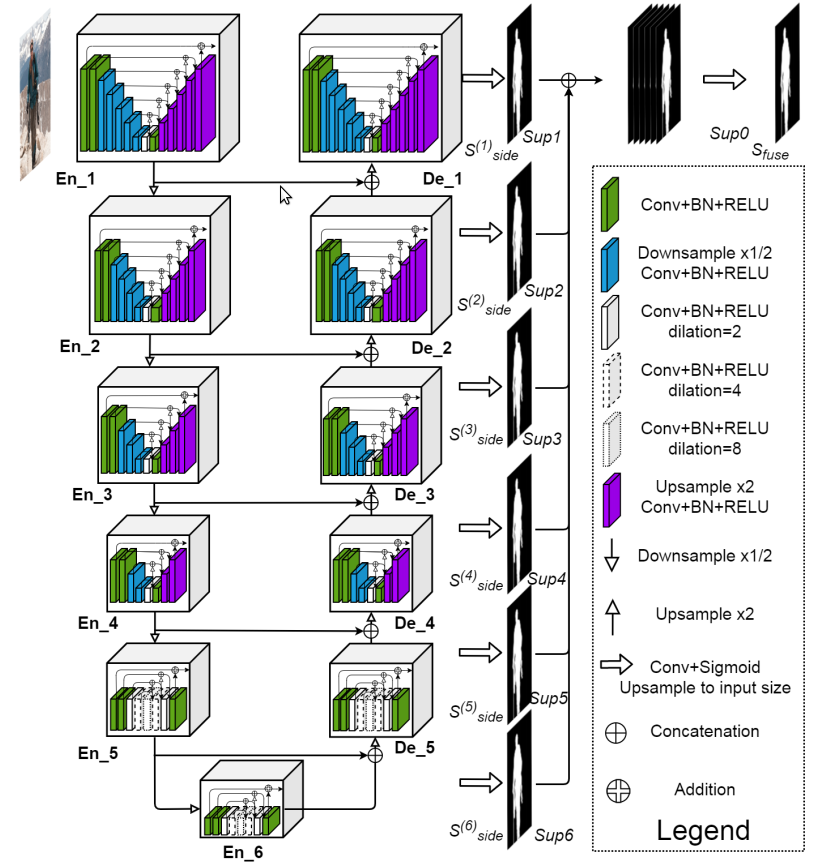
!
[](
http://latex.codecogs.com/svg.latex?U^2Net
)
的网络结构如下图,其类似于编码-解码(Encoder-Decoder)结构的 U-Net
*
每个 stage 由新提出的 RSU模块(residual U-block) 组成. 例如,En_1 即为基于 RSU 构建的
|模型名称|U2Net_Portrait|
*
!
[](
https://latex.codecogs.com/svg.latex?U^2Net_{Portrait}
)
是基于!
[](
http://latex.codecogs.com/svg.latex?U^2Net
)
的人脸画像生成模型
| :--- | :---: |
|类别|图像 - 图像生成|
|网络|U^2Net|
|数据集|-|
## 效果展示
|是否支持Fine-tuning|否|

|模型大小|254MB|

|最新更新日期|2021-02-26|
|数据指标|-|
## API
```
python
def
Portrait_GEN
(
## 一、模型基本信息
images
=
None
,
paths
=
None
,
-
### 应用效果展示
scale
=
1
,
-
样例结果示例:
batch_size
=
1
,
<p
align=
"center"
>
output_dir
=
'output'
,
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/07f73466f3294373965e06c141c4781992f447104a94471dadfabc1c3d920861"
height=
'50%'
hspace=
'10'
/>
face_detection
=
True
,
<br
/>
visualization
=
False
):
输入图像
```
<br
/>
人脸画像生成 API
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/c6ab02cf27414a5ba5921d9e6b079b487f6cda6026dc4d6dbca8f0167ad7cae3"
height=
'50%'
hspace=
'10'
/>
<br
/>
**参数**
输出图像
*
images (list[np.ndarray]) : 输入图像数据列表(BGR)
<br
/>
*
paths (list[str]) : 输入图像路径列表
</p>
*
scale (float) : 缩放因子(与face_detection相关联)
*
batch_size (int) : 数据批大小
*
output_dir (str) : 可视化图像输出目录
-
### 模型介绍
*
face_detection (bool) : 是否开启人脸检测,开启后会检测人脸并使用人脸中心点进行图像缩放裁切
*
visualization (bool) : 是否可视化
-
U2Net_Portrait 可以用于提取人脸的素描结果。
**返回**
*
results (list[np.ndarray]): 输出图像数据列表
## 二、安装
**代码示例**
-
### 1、环境依赖
```
python
import
cv2
-
paddlepaddle >= 2.0.0
import
paddlehub
as
hub
-
paddlehub >= 2.0.0 |
[
如何安装paddlehub
](
../../../../docs/docs_ch/get_start/installation.rst
)
model
=
hub
.
Module
(
name
=
'U2Net_Portrait'
)
-
### 2、安装
result
=
model
.
Portrait_GEN
(
images
=
[
cv2
.
imread
(
'/PATH/TO/IMAGE'
)],
-
```shell
paths
=
None
,
$ hub install U2Net_Portrait
scale
=
1
,
```
batch_size
=
1
,
-
如您安装时遇到问题,可参考:
[
零基础windows安装
](
../../../../docs/docs_ch/get_start/windows_quickstart.md
)
output_dir
=
'output'
,
|
[
零基础Linux安装
](
../../../../docs/docs_ch/get_start/linux_quickstart.md
)
|
[
零基础MacOS安装
](
../../../../docs/docs_ch/get_start/mac_quickstart.md
)
face_detection
=
True
,
visualization
=
True
)
## 三、模型API预测
```
-
### 1、代码示例
## 查看代码
https://github.com/NathanUA/U-2-Net
-
```python
import paddlehub as hub
## 依赖
import cv2
paddlepaddle >= 2.0.0rc0
paddlehub >= 2.0.0b1
model = hub.Module(name="U2Net_Portrait")
result = model.Cartoon_GEN(images=[cv2.imread('/PATH/TO/IMAGE')])
# or
# result = model.Cartoon_GEN(paths=['/PATH/TO/IMAGE'])
```
-
### 2、API
-
```python
def Portrait_GEN(images=None,
paths=None,
scale=1,
batch_size=1,
output_dir='output',
face_detection=True,
visualization=False):
```
-
人脸画像生成API。
-
**参数**
-
images (list
\[
numpy.ndarray
\]
): 图片数据,ndarray.shape 为
\[
H, W, C
\]
;
<br/>
-
paths (list
\[
str
\]
): 输入图像路径;
<br/>
-
scale (float) : 缩放因子(与face_detection相关联);
<br/>
-
batch_size (int) : batch大小;
<br/>
-
output
\_
dir (str): 图片的保存路径,默认设为 output;
<br/>
-
visualization (bool) : 是否将结果保存为图片文件;;
<br/>
**NOTE:**
paths和images两个参数选择其一进行提供数据
-
**返回**
-
res (list
\[
numpy.ndarray
\]
): 输出图像数据,ndarray.shape 为
\[
H, W, C
\]
## 四、更新历史
*
1.0.0
初始发布
-
```shell
$ hub install U2Net_Portrait==1.0.0
```
modules/thirdparty/image/Image_gan/style_transfer/UGATIT_100w/README.md
浏览文件 @
e80dbf15
## 模型概述
# UGATIT_100w
UGATIT 图像风格转换模型
模型可将输入的人脸图像转换成动漫风格
|模型名称|UGATIT_100w|
| :--- | :---: |
|类别|图像 - 图像生成|
|网络|U-GAT-IT|
|数据集|selfie2anime|
|是否支持Fine-tuning|否|
|模型大小|41MB|
|最新更新日期|2021-02-26|
|数据指标|-|
模型权重来自UGATIT-Paddle开源项目
模型所使用的权重为genA2B_1000000
## 一、模型基本信息
模型详情请参考
[
UGATIT-Paddle开源项目
](
https://github.com/miraiwk/UGATIT-paddle
)
-
### 应用效果展示
-
样例结果示例:
<p
align=
"center"
>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/d130fabd8bd34e53b2f942b3766eb6bbd3c19c0676d04abfbd5cc4b83b66f8b6"
height=
'80%'
hspace=
'10'
/>
<br
/>
输入图像
<br
/>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/8538af03b3f14b1884fcf4eec48965baf939e35a783d40129085102057438c77"
height=
'80%'
hspace=
'10'
/>
<br
/>
输出图像
<br
/>
</p>
## 模型安装
```
shell
-
### 模型介绍
$hub
install
UGATIT_100w
```
-
UGATIT图像风格转换模型, 模型可将输入的人脸图像转换成动漫风格, 模型详情请参考
[
UGATIT-Paddle开源项目
](
https://github.com/miraiwk/UGATIT-paddle
)
。
## API 说明
```
python
## 二、安装
def
style_transfer
(
self
,
images
=
None
,
paths
=
None
,
batch_size
=
1
,
output_dir
=
'output'
,
visualization
=
False
)
```
风格转换API,将输入的人脸图像转换成动漫风格。
-
### 1、环境依赖
转换效果图如下:
-
paddlepaddle >= 1.8.0

-
paddlehub >= 1.8.0 |
[
如何安装paddlehub
](
../../../../docs/docs_ch/get_start/installation.rst
)

**参数**
-
### 2、安装
*
images (list
\[
numpy.ndarray
\]
): 图片数据,ndarray.shape 为
\[
H, W, C
\]
,默认为 None;
-
```shell
*
paths (list
\[
str
\]
): 图片的路径,默认为 None;
$ hub install UGATIT_100w
*
batch
\_
size (int): batch 的大小,默认设为 1;
```
*
visualization (bool): 是否将识别结果保存为图片文件,默认设为 False;
-
如您安装时遇到问题,可参考:
[
零基础windows安装
](
../../../../docs/docs_ch/get_start/windows_quickstart.md
)
*
output
\_
dir (str): 图片的保存路径,默认设为 output。
|
[
零基础Linux安装
](
../../../../docs/docs_ch/get_start/linux_quickstart.md
)
|
[
零基础MacOS安装
](
../../../../docs/docs_ch/get_start/mac_quickstart.md
)
## 三、模型API预测
**返回**
-
### 1、代码示例
*
res (list
\[
numpy.ndarray
\]
): 输出图像数据,ndarray.shape 为
\[
H, W, C
\]
。
-
```python
import paddlehub as hub
import cv2
model = hub.Module(name="UGATIT_100w")
result = model.style_transfer(images=[cv2.imread('/PATH/TO/IMAGE')])
# or
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
```
## 预测代码示例
-
### 2、API
```
python
-
```python
import
cv2
def style_transfer(images=None,
import
paddlehub
as
hub
paths=None,
batch_size=1,
output_dir='output',
visualization=False)
```
# 模型加载
- 风格转换API,将输入的人脸图像转换成动漫风格。
# use_gpu:是否使用GPU进行预测
model
=
hub
.
Module
(
name
=
'UGATIT_100w'
,
use_gpu
=
False
)
# 模型预测
- **参数**
result
=
model
.
style_transfer
(
images
=
[
cv2
.
imread
(
'/PATH/TO/IMAGE'
)])
# or
- images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\];<br/>
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
- paths (list\[str\]): 图片的路径;<br/>
```
- batch\_size (int): batch的大小;<br/>
- visualization (bool): 是否将识别结果保存为图片文件;<br/>
- output\_dir (str): 图片的保存路径,默认设为 output;<br/>
## 服务部署
**NOTE:** paths和images两个参数选择其一进行提供数据
PaddleHub Serving可以部署一个在线图像风格转换服务。
- **返回**
- res (list\[numpy.ndarray\]): 输出图像数据,ndarray.shape 为 \[H, W, C\]
## 第一步:启动PaddleHub Serving
运行启动命令:
## 四、服务部署
```
shell
$
hub serving start
-m
UGATIT_100w
```
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866
。
-
PaddleHub Serving可以部署一个在线图像风格转换服务
。
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
-
### 第一步:启动PaddleHub Serving
## 第二步:发送预测请求
-
运行启动命令:
-
```shell
$ hub serving start -m UGATIT_100w
```
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866。
```
python
-
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
import
requests
import
json
import
cv2
import
base64
-
### 第二步:发送预测请求
def
cv2_to_base64
(
image
):
-
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
data
=
cv2
.
imencode
(
'.jpg'
,
image
)[
1
]
return
base64
.
b64encode
(
data
.
tostring
()).
decode
(
'utf8'
)
-
```python
import requests
import json
import cv2
import base64
# 发送HTTP请求
data
=
{
'images'
:[
cv2_to_base64
(
cv2
.
imread
(
"/PATH/TO/IMAGE"
))]}
headers
=
{
"Content-type"
:
"application/json"
}
url
=
"http://127.0.0.1:8866/predict/UGATIT_100w"
r
=
requests
.
post
(
url
=
url
,
headers
=
headers
,
data
=
json
.
dumps
(
data
))
# 打印预测结果
def cv2_to_base64(image):
print
(
r
.
json
()[
"results"
])
data = cv2.imencode('.jpg', image)[1]
```
return base64.b64encode(data.tostring()).decode('utf8')
# 发送HTTP请求
data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/UGATIT_100w"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
## 模型相关信息
# 打印预测结果
print(r.json()["results"])
```
### 模型代码
https://github.com/miraiwk/UGATIT-paddle
## 五、更新历史
### 依赖
*
1.0.0
paddlepaddle >= 1.8.0
初始发布
paddlehub >= 1.8.0
-
```shell
$ hub install UGATIT_100w==1.0.0
```
modules/thirdparty/image/Image_gan/style_transfer/animegan_v1_hayao_60/README.md
浏览文件 @
e80dbf15
## 模型概述
# animegan_v1_hayao_60
AnimeGAN V1 图像风格转换模型
模型可将输入的图像转换成Hayao风格
|模型名称|animegan_v1_hayao_60|
| :--- | :---: |
|类别|图像 - 图像生成|
|网络|AnimeGAN|
|数据集|The Wind Rises|
|是否支持Fine-tuning|否|
|模型大小|18MB|
|最新更新日期|2021-07-30|
|数据指标|-|
模型权重转换自AnimeGAN V1官方开源项目
模型所使用的权重为Hayao-60.ckpt
## 一、模型基本信息
模型详情请参考
[
AnimeGAN V1 开源项目
](
https://github.com/TachibanaYoshino/AnimeGAN
)
-
### 应用效果展示
-
样例结果示例:
<p
align=
"center"
>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/bd002c4bb6a7427daf26988770bb18648b7d8d2bfd6746bfb9a429db4867727f"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输入图像
<br
/>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/10175bb964e94ce18608a84b0ab6ebfe154b523df42f44a3a851b2d91dd17a63"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输出图像
<br
/>
</p>
## 模型安装
```
shell
$hub
install
animegan_v1_hayao_60
```
-
### 模型介绍
## API 说明
-
AnimeGAN V1 图像风格转换模型, 模型可将输入的图像转换成宫崎骏动漫风格,模型权重转换自
[
AnimeGAN V1官方开源项目
](
https://github.com/TachibanaYoshino/AnimeGAN
)
。
```
python
def
style_transfer
(
self
,
images
=
None
,
paths
=
None
,
output_dir
=
'output'
,
visualization
=
False
,
min_size
=
32
,
max_size
=
1024
)
```
风格转换API,将输入的图片转换为漫画风格。
## 二、安装
转换效果图如下:
-
### 1、环境依赖

-
paddlepaddle >= 1.8.0

-
paddlehub >= 1.8.0 |
[
如何安装paddlehub
](
../../../../docs/docs_ch/get_start/installation.rst
)
**参数**
-
### 2、安装
*
images (list
\[
numpy.ndarray
\]
): 图片数据,ndarray.shape 为
\[
H, W, C
\]
,默认为 None;
-
```shell
*
paths (list
\[
str
\]
): 图片的路径,默认为 None;
$ hub install animegan_v1_hayao_60
*
visualization (bool): 是否将识别结果保存为图片文件,默认设为 False;
```
*
output
\_
dir (str): 图片的保存路径,默认设为 output;
-
如您安装时遇到问题,可参考:
[
零基础windows安装
](
../../../../docs/docs_ch/get_start/windows_quickstart.md
)
*
min
\_
size (int): 输入图片的短边最小尺寸,默认设为 32;
|
[
零基础Linux安装
](
../../../../docs/docs_ch/get_start/linux_quickstart.md
)
|
[
零基础MacOS安装
](
../../../../docs/docs_ch/get_start/mac_quickstart.md
)
*
max
\_
size (int): 输入图片的短边最大尺寸,默认设为 1024。
## 三、模型API预测
**返回**
-
### 1、代码示例
*
res (list
\[
numpy.ndarray
\]
): 输出图像数据,ndarray.shape 为
\[
H, W, C
\]
。
-
```python
import paddlehub as hub
import cv2
model = hub.Module(name="animegan_v1_hayao_60")
result = model.style_transfer(images=[cv2.imread('/PATH/TO/IMAGE')])
# or
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
```
## 预测代码示例
-
### 2、API
```
python
-
```python
import
cv2
def style_transfer(images=None,
import
paddlehub
as
hub
paths=None,
output_dir='output',
visualization=False,
min_size=32,
max_size=1024)
```
# 模型加载
- 风格转换API,将输入的图片转换为漫画风格。
# use_gpu:是否使用GPU进行预测
model
=
hub
.
Module
(
name
=
'animegan_v1_hayao_60'
,
use_gpu
=
False
)
# 模型预测
- **参数**
result
=
model
.
style_transfer
(
images
=
[
cv2
.
imread
(
'/PATH/TO/IMAGE'
)])
# or
- images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\];<br/>
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
- paths (list\[str\]): 图片的路径;<br/>
```
- output\_dir (str): 图片的保存路径,默认设为 output;<br/>
- visualization (bool): 是否将识别结果保存为图片文件;<br/>
- min\_size (int): 输入图片的短边最小尺寸,默认设为 32;<br/>
- max\_size (int): 输入图片的短边最大尺寸,默认设为 1024。
## 服务部署
**NOTE:** paths和images两个参数选择其一进行提供数据
PaddleHub Serving可以部署一个在线图像风格转换服务。
- **返回**
- res (list\[numpy.ndarray\]): 输出图像数据,ndarray.shape 为 \[H, W, C\]
## 第一步:启动PaddleHub Serving
运行启动命令:
## 四、服务部署
```
shell
$
hub serving start
-m
animegan_v1_hayao_60
```
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866
。
-
PaddleHub Serving可以部署一个在线图像风格转换服务
。
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
-
### 第一步:启动PaddleHub Serving
## 第二步:发送预测请求
-
运行启动命令:
-
```shell
$ hub serving start -m animegan_v1_hayao_60
```
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866。
```
python
-
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
import
requests
import
json
import
cv2
import
base64
-
### 第二步:发送预测请求
def
cv2_to_base64
(
image
):
-
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
data
=
cv2
.
imencode
(
'.jpg'
,
image
)[
1
]
return
base64
.
b64encode
(
data
.
tostring
()).
decode
(
'utf8'
)
-
```python
import requests
import json
import cv2
import base64
# 发送HTTP请求
data
=
{
'images'
:[
cv2_to_base64
(
cv2
.
imread
(
"/PATH/TO/IMAGE"
))]}
headers
=
{
"Content-type"
:
"application/json"
}
url
=
"http://127.0.0.1:8866/predict/animegan_v1_hayao_60"
r
=
requests
.
post
(
url
=
url
,
headers
=
headers
,
data
=
json
.
dumps
(
data
))
# 打印预测结果
def cv2_to_base64(image):
print
(
r
.
json
()[
"results"
])
data = cv2.imencode('.jpg', image)[1]
```
return base64.b64encode(data.tostring()).decode('utf8')
# 发送HTTP请求
data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/animegan_v1_hayao_60"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
## 模型相关信息
# 打印预测结果
print(r.json()["results"])
```
### 模型代码
https://github.com/TachibanaYoshino/AnimeGAN
## 五、更新历史
### 依赖
*
1.0.0
paddlepaddle >= 1.8.0
初始发布
paddlehub >= 1.8.0
*
1.0.1
适配paddlehub2.0
*
1.0.2
删除batch_size选项
-
```shell
$ hub install animegan_v1_hayao_60==1.0.2
```
modules/thirdparty/image/Image_gan/style_transfer/animegan_v2_hayao_64/README.md
浏览文件 @
e80dbf15
## 模型概述
# animegan_v2_hayao_64
AnimeGAN V2 图像风格转换模型
模型可将输入的图像转换成Hayao风格
|模型名称|animegan_v2_hayao_64|
| :--- | :---: |
|类别|图像 - 图像生成|
|网络|AnimeGAN|
|数据集|The Wind Rises|
|是否支持Fine-tuning|否|
|模型大小|9.4MB|
|最新更新日期|2021-07-30|
|数据指标|-|
模型权重转换自AnimeGAN V2官方开源项目
模型所使用的权重为Hayao-64.ckpt
## 一、模型基本信息
模型详情请参考
[
AnimeGAN V2 开源项目
](
https://github.com/TachibanaYoshino/AnimeGANv2
)
-
### 应用效果展示
-
样例结果示例:
<p
align=
"center"
>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/bd002c4bb6a7427daf26988770bb18648b7d8d2bfd6746bfb9a429db4867727f"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输入图像
<br
/>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/49620341f1fe4f00af4d93c22694897a1ae578a235844a1db1bbb4bd37bf750b"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输出图像
<br
/>
</p>
## 模型安装
-
### 模型介绍
```
shell
-
AnimeGAN V2 图像风格转换模型, 模型可将输入的图像转换成宫崎骏动漫风格,模型权重转换自
[
AnimeGAN V2官方开源项目
](
https://github.com/TachibanaYoshino/AnimeGANv2
)
。
$hub
install
animegan_v2_hayao_64
```
##
API 说明
##
二、安装
```
python
-
### 1、环境依赖
def
style_transfer
(
self
,
images
=
None
,
paths
=
None
,
output_dir
=
'output'
,
visualization
=
False
,
min_size
=
32
,
max_size
=
1024
)
```
风格转换API,将输入的图片转换为漫画风格。
-
paddlepaddle >= 1.8.0
转换效果图如下:
-
paddlehub >= 1.8.0 |
[
如何安装paddlehub
](
../../../../docs/docs_ch/get_start/installation.rst
)

-
### 2、安装

-
```shell
$ hub install animegan_v2_hayao_64
```
-
如您安装时遇到问题,可参考:
[
零基础windows安装
](
../../../../docs/docs_ch/get_start/windows_quickstart.md
)
|
[
零基础Linux安装
](
../../../../docs/docs_ch/get_start/linux_quickstart.md
)
|
[
零基础MacOS安装
](
../../../../docs/docs_ch/get_start/mac_quickstart.md
)
**参数**
## 三、模型API预测
*
images (list
\[
numpy.ndarray
\]
): 图片数据,ndarray.shape 为
\[
H, W, C
\]
,默认为 None;
-
### 1、代码示例
*
paths (list
\[
str
\]
): 图片的路径,默认为 None;
*
visualization (bool): 是否将识别结果保存为图片文件,默认设为 False;
*
output
\_
dir (str): 图片的保存路径,默认设为 output;
*
min
\_
size (int): 输入图片的短边最小尺寸,默认设为 32;
*
max
\_
size (int): 输入图片的短边最大尺寸,默认设为 1024。
-
```python
import paddlehub as hub
import cv2
**返回**
model = hub.Module(name="animegan_v2_hayao_64")
result = model.style_transfer(images=[cv2.imread('/PATH/TO/IMAGE')])
# or
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
```
*
res (list
\[
numpy.ndarray
\]
): 输出图像数据,ndarray.shape 为
\[
H, W, C
\]
。
-
### 3、API
-
```python
def style_transfer(images=None,
paths=None,
output_dir='output',
visualization=False,
min_size=32,
max_size=1024)
```
## 预测代码示例
- 风格转换API,将输入的图片转换为漫画风格。
```
python
- **参数**
import
cv2
import
paddlehub
as
hub
# 模型加载
- images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\];<br/>
# use_gpu:是否使用GPU进行预测
- paths (list\[str\]): 图片的路径;<br/>
model
=
hub
.
Module
(
name
=
'animegan_v2_hayao_64'
,
use_gpu
=
False
)
- output\_dir (str): 图片的保存路径,默认设为 output;<br/>
- visualization (bool): 是否将识别结果保存为图片文件;<br/>
- min\_size (int): 输入图片的短边最小尺寸,默认设为 32;<br/>
- max\_size (int): 输入图片的短边最大尺寸,默认设为 1024。
# 模型预测
**NOTE:** paths和images两个参数选择其一进行提供数据
result
=
model
.
style_transfer
(
images
=
[
cv2
.
imread
(
'/PATH/TO/IMAGE'
)])
# or
- **返回**
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
- res (list\[numpy.ndarray\]): 输出图像数据,ndarray.shape 为 \[H, W, C\]
```
## 服务部署
PaddleHub Serving可以部署一个在线图像风格转换服务。
## 四、服务部署
## 第一步:启动PaddleHub Serving
-
PaddleHub Serving可以部署一个在线图像风格转换服务。
运行启动命令:
-
### 第一步:启动PaddleHub Serving
```
shell
$
hub serving start
-m
animegan_v2_hayao_64
```
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866。
-
运行启动命令:
-
```shell
$ hub serving start -m animegan_v2_hayao_64
```
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置
。
-
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866
。
## 第二步:发送预测请求
-
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
### 第二步:发送预测请求
```
python
-
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
import
requests
import
json
import
cv2
import
base64
-
```python
import requests
import json
import cv2
import base64
def
cv2_to_base64
(
image
):
data
=
cv2
.
imencode
(
'.jpg'
,
image
)[
1
]
return
base64
.
b64encode
(
data
.
tostring
()).
decode
(
'utf8'
)
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')
# 发送HTTP请求
# 发送HTTP请求
data
=
{
'images'
:[
cv2_to_base64
(
cv2
.
imread
(
"/PATH/TO/IMAGE"
))]}
data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
headers
=
{
"Content-type"
:
"application/json"
}
headers = {"Content-type": "application/json"}
url
=
"http://127.0.0.1:8866/predict/animegan_v2_hayao_64"
url = "http://127.0.0.1:8866/predict/animegan_v2_hayao_64"
r
=
requests
.
post
(
url
=
url
,
headers
=
headers
,
data
=
json
.
dumps
(
data
))
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
# 打印预测结果
print
(
r
.
json
()[
"results"
])
print(r.json()["results"])
```
```
##
模型相关信息
##
五、更新历史
### 模型代码
*
1.0.0
https://github.com/TachibanaYoshino/AnimeGANv2
初始发布
### 依赖
*
1.0.1
paddlepaddle >= 1.8
.0
适配paddlehub2
.0
paddlehub >= 1.8.0
*
1.0.2
删除batch_size选项
-
```shell
$ hub install animegan_v2_hayao_64==1.0.2
```
modules/thirdparty/image/Image_gan/style_transfer/animegan_v2_hayao_99/README.md
浏览文件 @
e80dbf15
## 模型概述
# animegan_v2_hayao_99
AnimeGAN V2 图像风格转换模型
模型可将输入的图像转换成Hayao风格
|模型名称|animegan_v2_hayao_99|
| :--- | :---: |
|类别|图像 - 图像生成|
|网络|AnimeGAN|
|数据集|The Wind Rises|
|是否支持Fine-tuning|否|
|模型大小|9.4MB|
|最新更新日期|2021-07-30|
|数据指标|-|
模型权重转换自AnimeGAN V2官方开源项目
模型所使用的权重为Hayao-99.ckpt
## 一、模型基本信息
模型详情请参考
[
AnimeGAN V2 开源项目
](
https://github.com/TachibanaYoshino/AnimeGANv2
)
-
### 应用效果展示
-
样例结果示例:
<p
align=
"center"
>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/bd002c4bb6a7427daf26988770bb18648b7d8d2bfd6746bfb9a429db4867727f"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输入图像
<br
/>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/16195e03d7e0412d990349587c587a26d9ae9e2ed1ec4fa1b4dc994e948d1f7d"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输出图像
<br
/>
</p>
## 模型安装
```
shell
-
### 模型介绍
$hub
install
animegan_v2_hayao_99
```
-
AnimeGAN V2 图像风格转换模型, 模型可将输入的图像转换成宫崎骏动漫风格,模型权重转换自
[
AnimeGAN V2官方开源项目
](
https://github.com/TachibanaYoshino/AnimeGANv2
)
。
## API 说明
```
python
## 二、安装
def
style_transfer
(
self
,
images
=
None
,
paths
=
None
,
output_dir
=
'output'
,
visualization
=
False
,
min_size
=
32
,
max_size
=
1024
)
```
风格转换API,将输入的图片转换为漫画风格。
-
### 1、环境依赖
转换效果图如下:
-
paddlepaddle >= 1.8.0

-
paddlehub >= 1.8.0 |
[
如何安装paddlehub
](
../../../../docs/docs_ch/get_start/installation.rst
)

-
### 2、安装
**参数**
-
```shell
$ hub install animegan_v2_hayao_99
```
-
如您安装时遇到问题,可参考:
[
零基础windows安装
](
../../../../docs/docs_ch/get_start/windows_quickstart.md
)
|
[
零基础Linux安装
](
../../../../docs/docs_ch/get_start/linux_quickstart.md
)
|
[
零基础MacOS安装
](
../../../../docs/docs_ch/get_start/mac_quickstart.md
)
w
*
images (list
\[
numpy.ndarray
\]
): 图片数据,ndarray.shape 为
\[
H, W, C
\]
,默认为 None;
## 三、模型API预测
*
paths (list
\[
str
\]
): 图片的路径,默认为 None;
*
visualization (bool): 是否将识别结果保存为图片文件,默认设为 False;
*
output
\_
dir (str): 图片的保存路径,默认设为 output;
*
min
\_
size (int): 输入图片的短边最小尺寸,默认设为 32;
*
max
\_
size (int): 输入图片的短边最大尺寸,默认设为 1024。
**返回**
-
### 1、代码示例
*
res (list
\[
numpy.ndarray
\]
): 输出图像数据,ndarray.shape 为
\[
H, W, C
\]
。
-
```python
import paddlehub as hub
import cv2
model = hub.Module(name="animegan_v2_hayao_99")
result = model.style_transfer(images=[cv2.imread('/PATH/TO/IMAGE')])
# or
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
```
## 预测代码示例
-
### 2、API
```
python
-
```python
import
cv2
def style_transfer(images=None,
import
paddlehub
as
hub
paths=None,
output_dir='output',
visualization=False,
min_size=32,
max_size=1024)
```
# 模型加载
- 风格转换API,将输入的图片转换为漫画风格。
# use_gpu:是否使用GPU进行预测
model
=
hub
.
Module
(
name
=
'animegan_v2_hayao_99'
,
use_gpu
=
False
)
# 模型预测
- **参数**
result
=
model
.
style_transfer
(
images
=
[
cv2
.
imread
(
'/PATH/TO/IMAGE'
)])
# or
- images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\];<br/>
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
- paths (list\[str\]): 图片的路径;<br/>
```
- output\_dir (str): 图片的保存路径,默认设为 output;<br/>
- visualization (bool): 是否将识别结果保存为图片文件;<br/>
- min\_size (int): 输入图片的短边最小尺寸,默认设为 32;<br/>
- max\_size (int): 输入图片的短边最大尺寸,默认设为 1024。
## 服务部署
**NOTE:** paths和images两个参数选择其一进行提供数据
PaddleHub Serving可以部署一个在线图像风格转换服务。
- **返回**
- res (list\[numpy.ndarray\]): 输出图像数据,ndarray.shape 为 \[H, W, C\]
## 第一步:启动PaddleHub Serving
运行启动命令:
## 四、服务部署
```
shell
$
hub serving start
-m
animegan_v2_hayao_99
```
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866
。
-
PaddleHub Serving可以部署一个在线图像风格转换服务
。
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
-
### 第一步:启动PaddleHub Serving
## 第二步:发送预测请求
-
运行启动命令:
-
```shell
$ hub serving start -m animegan_v2_hayao_99
```
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866。
```
python
-
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
import
requests
import
json
import
cv2
import
base64
-
### 第二步:发送预测请求
def
cv2_to_base64
(
image
):
-
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
data
=
cv2
.
imencode
(
'.jpg'
,
image
)[
1
]
return
base64
.
b64encode
(
data
.
tostring
()).
decode
(
'utf8'
)
-
```python
import requests
import json
import cv2
import base64
# 发送HTTP请求
data
=
{
'images'
:[
cv2_to_base64
(
cv2
.
imread
(
"/PATH/TO/IMAGE"
))]}
headers
=
{
"Content-type"
:
"application/json"
}
url
=
"http://127.0.0.1:8866/predict/animegan_v2_hayao_99"
r
=
requests
.
post
(
url
=
url
,
headers
=
headers
,
data
=
json
.
dumps
(
data
))
# 打印预测结果
def cv2_to_base64(image):
print
(
r
.
json
()[
"results"
])
data = cv2.imencode('.jpg', image)[1]
```
return base64.b64encode(data.tostring()).decode('utf8')
# 发送HTTP请求
data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/animegan_v2_hayao_99"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
## 模型相关信息
# 打印预测结果
print(r.json()["results"])
```
### 模型代码
https://github.com/TachibanaYoshino/AnimeGANv2
## 五、更新历史
### 依赖
*
1.0.0
paddlepaddle >= 1.8.0
初始发布
paddlehub >= 1.8.0
*
1.0.1
适配paddlehub2.0
*
1.0.2
删除batch_size选项
-
```shell
$ hub install animegan_v2_hayao_99==1.0.2
```
modules/thirdparty/image/Image_gan/style_transfer/animegan_v2_paprika_74/README.md
浏览文件 @
e80dbf15
## 模型概述
# animegan_v2_paprika_74
AnimeGAN V2 图像风格转换模型
模型可将输入的图像转换成Paprika风格
|模型名称|animegan_v2_paprika_74|
| :--- | :---: |
|类别|图像 - 图像生成|
|网络|AnimeGAN|
|数据集|Paprika|
|是否支持Fine-tuning|否|
|模型大小|9.4MB|
|最新更新日期|2021-02-26|
|数据指标|-|
模型权重转换自AnimeGAN V2官方开源项目
模型所使用的权重为Paprika-74.ckpt
## 一、模型基本信息
模型详情请参考
[
AnimeGAN V2 开源项目
](
https://github.com/TachibanaYoshino/AnimeGANv2
)
-
### 应用效果展示
-
样例结果示例:
<p
align=
"center"
>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/bd002c4bb6a7427daf26988770bb18648b7d8d2bfd6746bfb9a429db4867727f"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输入图像
<br
/>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/6574669d87b24bab9627c6e33896528b4a0bf5af1cd84ca29655d68719f2d551"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输出图像
<br
/>
</p>
## 模型安装
```
shell
-
### 模型介绍
$hub
install
animegan_v2_paprika_74
```
-
AnimeGAN V2 图像风格转换模型, 模型可将输入的图像转换成今敏红辣椒动漫风格,模型权重转换自
[
AnimeGAN V2官方开源项目
](
https://github.com/TachibanaYoshino/AnimeGANv2
)
。
## API 说明
```
python
## 二、安装
def
style_transfer
(
self
,
images
=
None
,
paths
=
None
,
output_dir
=
'output'
,
visualization
=
False
,
min_size
=
32
,
max_size
=
1024
)
```
风格转换API,将输入的图片转换为漫画风格。
-
### 1、环境依赖
转换效果图如下:
-
paddlepaddle >= 1.8.0

-
paddlehub >= 1.8.0 |
[
如何安装paddlehub
](
../../../../docs/docs_ch/get_start/installation.rst
)

-
### 2、安装
**参数**
-
```shell
$ hub install animegan_v2_paprika_74
```
-
如您安装时遇到问题,可参考:
[
零基础windows安装
](
../../../../docs/docs_ch/get_start/windows_quickstart.md
)
|
[
零基础Linux安装
](
../../../../docs/docs_ch/get_start/linux_quickstart.md
)
|
[
零基础MacOS安装
](
../../../../docs/docs_ch/get_start/mac_quickstart.md
)
*
images (list
\[
numpy.ndarray
\]
): 图片数据,ndarray.shape 为
\[
H, W, C
\]
,默认为 None;
## 三、模型API预测
*
paths (list
\[
str
\]
): 图片的路径,默认为 None;
*
visualization (bool): 是否将识别结果保存为图片文件,默认设为 False;
*
output
\_
dir (str): 图片的保存路径,默认设为 output;
*
min
\_
size (int): 输入图片的短边最小尺寸,默认设为 32;
*
max
\_
size (int): 输入图片的短边最大尺寸,默认设为 1024。
-
### 1、代码示例
**返回**
-
```python
import paddlehub as hub
import cv2
*
res (list
\[
numpy.ndarray
\]
): 输出图像数据,ndarray.shape 为
\[
H, W, C
\]
。
model = hub.Module(name="animegan_v2_paprika_74")
result = model.style_transfer(images=[cv2.imread('/PATH/TO/IMAGE')])
# or
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
```
-
### 2、API
## 预测代码示例
-
```python
def style_transfer(images=None,
paths=None,
output_dir='output',
visualization=False,
min_size=32,
max_size=1024)
```
```
python
- 风格转换API,将输入的图片转换为漫画风格。
import
cv2
import
paddlehub
as
hub
# 模型加载
- **参数**
# use_gpu:是否使用GPU进行预测
model
=
hub
.
Module
(
name
=
'animegan_v2_paprika_74'
,
use_gpu
=
False
)
# 模型预测
- images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\];<br/>
result
=
model
.
style_transfer
(
images
=
[
cv2
.
imread
(
'/PATH/TO/IMAGE'
)])
- paths (list\[str\]): 图片的路径;<br/>
- output\_dir (str): 图片的保存路径,默认设为 output;<br/>
- visualization (bool): 是否将结果保存为图片文件;<br/>
- min\_size (int): 输入图片的短边最小尺寸,默认设为 32;<br/>
- max\_size (int): 输入图片的短边最大尺寸,默认设为 1024。
# or
- **返回**
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
- res (list\[numpy.ndarray\]): 输出图像数据,ndarray.shape 为 \[H, W, C\]
```
## 服务部署
PaddleHub Serving可以部署一个在线图像风格转换服务。
## 四、服务部署
## 第一步:启动PaddleHub Serving
-
PaddleHub Serving可以部署一个在线图像风格转换服务。
运行启动命令:
-
### 第一步:启动PaddleHub Serving
```
shell
$
hub serving start
-m
animegan_v2_paprika_74
```
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866。
-
运行启动命令:
-
```shell
$ hub serving start -m animegan_v2_paprika_74
```
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置
。
-
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866
。
## 第二步:发送预测请求
-
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
### 第二步:发送预测请求
```
python
-
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
import
requests
import
json
import
cv2
import
base64
-
```python
import requests
import json
import cv2
import base64
def
cv2_to_base64
(
image
):
data
=
cv2
.
imencode
(
'.jpg'
,
image
)[
1
]
return
base64
.
b64encode
(
data
.
tostring
()).
decode
(
'utf8'
)
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')
# 发送HTTP请求
# 发送HTTP请求
data
=
{
'images'
:[
cv2_to_base64
(
cv2
.
imread
(
"/PATH/TO/IMAGE"
))]}
data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
headers
=
{
"Content-type"
:
"application/json"
}
headers = {"Content-type": "application/json"}
url
=
"http://127.0.0.1:8866/predict/animegan_v2_paprika_74"
url = "http://127.0.0.1:8866/predict/animegan_v2_paprika_74"
r
=
requests
.
post
(
url
=
url
,
headers
=
headers
,
data
=
json
.
dumps
(
data
))
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
# 打印预测结果
print
(
r
.
json
()[
"results"
])
print(r.json()["results"])
```
```
##
模型相关信息
##
五、更新历史
### 模型代码
*
1.0.0
https://github.com/TachibanaYoshino/AnimeGANv2
初始发布
### 依赖
*
1.0.1
paddlepaddle >= 1.8
.0
适配paddlehub2
.0
paddlehub >= 1.8.0
*
1.0.2
删除batch_size选项
-
```shell
$ hub install animegan_v2_paprika_74==1.0.2
```
modules/thirdparty/image/Image_gan/style_transfer/animegan_v2_paprika_98/README.md
浏览文件 @
e80dbf15
## 模型概述
# animegan_v2_paprika_98
AnimeGAN V2 图像风格转换模型
模型可将输入的图像转换成Paprika风格
|模型名称|animegan_v2_paprika_98|
| :--- | :---: |
|类别|图像 - 图像生成|
|网络|AnimeGAN|
|数据集|Paprika|
|是否支持Fine-tuning|否|
|模型大小|9.4MB|
|最新更新日期|2021-07-30|
|数据指标|-|
模型权重转换自AnimeGAN V2官方开源项目
模型所使用的权重为Paprika-98.ckpt
## 一、模型基本信息
模型详情请参考
[
AnimeGAN V2 开源项目
](
https://github.com/TachibanaYoshino/AnimeGANv2
)
-
### 应用效果展示
-
样例结果示例:
<p
align=
"center"
>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/bd002c4bb6a7427daf26988770bb18648b7d8d2bfd6746bfb9a429db4867727f"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输入图像
<br
/>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/495436a627ef423ab572536c5f2ba6d0eb99b1ce098947a5ac02af36e7eb85f7"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输出图像
<br
/>
</p>
## 模型安装
```
shell
-
### 模型介绍
$hub
install
animegan_v2_paprika_98
```
-
AnimeGAN V2 图像风格转换模型, 模型可将输入的图像转换成今敏红辣椒动漫风格,模型权重转换自
[
AnimeGAN V2官方开源项目
](
https://github.com/TachibanaYoshino/AnimeGANv2
)
。
## API 说明
```
python
## 二、安装
def
style_transfer
(
self
,
images
=
None
,
paths
=
None
,
output_dir
=
'output'
,
visualization
=
False
,
min_size
=
32
,
max_size
=
1024
)
```
风格转换API,将输入的图片转换为漫画风格。
-
### 1、环境依赖
转换效果图如下:
-
paddlepaddle >= 1.8.0

-
paddlehub >= 1.8.0 |
[
如何安装paddlehub
](
../../../../docs/docs_ch/get_start/installation.rst
)

-
### 2、安装
**参数**
-
```shell
$ hub install animegan_v2_paprika_98
```
-
如您安装时遇到问题,可参考:
[
零基础windows安装
](
../../../../docs/docs_ch/get_start/windows_quickstart.md
)
|
[
零基础Linux安装
](
../../../../docs/docs_ch/get_start/linux_quickstart.md
)
|
[
零基础MacOS安装
](
../../../../docs/docs_ch/get_start/mac_quickstart.md
)
*
images (list
\[
numpy.ndarray
\]
): 图片数据,ndarray.shape 为
\[
H, W, C
\]
,默认为 None;
## 三、模型API预测
*
paths (list
\[
str
\]
): 图片的路径,默认为 None;
*
visualization (bool): 是否将识别结果保存为图片文件,默认设为 False;
*
output
\_
dir (str): 图片的保存路径,默认设为 output;
*
min
\_
size (int): 输入图片的短边最小尺寸,默认设为 32;
*
max
\_
size (int): 输入图片的短边最大尺寸,默认设为 1024。
-
### 1、代码示例
**返回**
-
```python
import paddlehub as hub
import cv2
*
res (list
\[
numpy.ndarray
\]
): 输出图像数据,ndarray.shape 为
\[
H, W, C
\]
。
model = hub.Module(name="animegan_v2_paprika_98")
result = model.style_transfer(images=[cv2.imread('/PATH/TO/IMAGE')])
# or
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
```
-
### 2、API
## 预测代码示例
-
```python
def style_transfer(images=None,
paths=None,
output_dir='output',
visualization=False,
min_size=32,
max_size=1024)
```
```
python
- 风格转换API,将输入的图片转换为漫画风格。
import
cv2
import
paddlehub
as
hub
# 模型加载
- **参数**
# use_gpu:是否使用GPU进行预测
model
=
hub
.
Module
(
name
=
'animegan_v2_paprika_98'
,
use_gpu
=
False
)
# 模型预测
- images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\];<br/>
result
=
model
.
style_transfer
(
images
=
[
cv2
.
imread
(
'/PATH/TO/IMAGE'
)])
- paths (list\[str\]): 图片的路径;<br/>
- output\_dir (str): 图片的保存路径,默认设为 output;<br/>
- visualization (bool): 是否将识别结果保存为图片文件;<br/>
- min\_size (int): 输入图片的短边最小尺寸,默认设为 32;<br/>
- max\_size (int): 输入图片的短边最大尺寸,默认设为 1024。
# or
**NOTE:** paths和images两个参数选择其一进行提供数据
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
```
## 服务部署
- **返回**
- res (list\[numpy.ndarray\]): 输出图像数据,ndarray.shape 为 \[H, W, C\]
PaddleHub Serving可以部署一个在线图像风格转换服务。
##
第一步:启动PaddleHub Serving
##
四、服务部署
运行启动命令:
-
PaddleHub Serving可以部署一个在线图像风格转换服务。
```
shell
$
hub serving start
-m
animegan_v2_paprika_98
```
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866。
-
### 第一步:启动PaddleHub Serving
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
-
运行启动命令:
-
```shell
$ hub serving start -m animegan_v2_paprika_98
```
## 第二步:发送预测请求
-
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866。
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
```
python
-
### 第二步:发送预测请求
import
requests
import
json
import
cv2
import
base64
-
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
def
cv2_to_base64
(
image
):
-
```python
data
=
cv2
.
imencode
(
'.jpg'
,
image
)[
1
]
import requests
return
base64
.
b64encode
(
data
.
tostring
()).
decode
(
'utf8'
)
import json
import cv2
import base64
# 发送HTTP请求
def cv2_to_base64(image):
data
=
{
'images'
:[
cv2_to_base64
(
cv2
.
imread
(
"/PATH/TO/IMAGE"
))]}
data = cv2.imencode('.jpg', image)[1]
headers
=
{
"Content-type"
:
"application/json"
}
return base64.b64encode(data.tostring()).decode('utf8')
url
=
"http://127.0.0.1:8866/predict/animegan_v2_paprika_98"
r
=
requests
.
post
(
url
=
url
,
headers
=
headers
,
data
=
json
.
dumps
(
data
))
# 打印预测结果
# 发送HTTP请求
print
(
r
.
json
()[
"results"
])
data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
```
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/animegan_v2_paprika_98"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
print(r.json()["results"])
```
## 模型相关信息
##
# 模型代码
##
五、更新历史
https://github.com/TachibanaYoshino/AnimeGANv2
*
1.0.0
### 依赖
初始发布
paddlepaddle >= 1.8.0
*
1.0.1
paddlehub >= 1.8.0
适配paddlehub2.0
*
1.0.2
删除batch_size选项
-
```shell
$ hub install animegan_v2_paprika_98==1.0.2
```
modules/thirdparty/image/Image_gan/style_transfer/animegan_v2_shinkai_33/README.md
浏览文件 @
e80dbf15
## 模型概述
# animegan_v2_shinkai_33
AnimeGAN V2 图像风格转换模型
模型可将输入的图像转换成Shinkai风格
|模型名称|animegan_v2_shinkai_33|
| :--- | :---: |
|类别|图像 - 图像生成|
|网络|AnimeGAN|
|数据集|Your Name, Weathering with you|
|是否支持Fine-tuning|否|
|模型大小|9.4MB|
|最新更新日期|2021-07-30|
|数据指标|-|
模型权重转换自AnimeGAN V2官方开源项目
模型所使用的权重为Shinkai-33.ckpt
## 一、模型基本信息
模型详情请参考
[
AnimeGAN V2 开源项目
](
https://github.com/TachibanaYoshino/AnimeGANv2
)
-
### 应用效果展示
-
样例结果示例:
<p
align=
"center"
>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/bd002c4bb6a7427daf26988770bb18648b7d8d2bfd6746bfb9a429db4867727f"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输入图像
<br
/>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/776a84a0d97c452bbbe479592fbb8f5c6fe9c45f3b7e41fd8b7da80bf52ee668"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输出图像
<br
/>
</p>
## 模型安装
```
shell
-
### 模型介绍
$hub
install
animegan_v2_shinkai_33
```
-
AnimeGAN V2 图像风格转换模型, 模型可将输入的图像转换成新海诚动漫风格,模型权重转换自
[
AnimeGAN V2官方开源项目
](
https://github.com/TachibanaYoshino/AnimeGANv2
)
。
## API 说明
```
python
## 二、安装
def
style_transfer
(
self
,
images
=
None
,
paths
=
None
,
output_dir
=
'output'
,
visualization
=
False
,
min_size
=
32
,
max_size
=
1024
)
```
风格转换API,将输入的图片转换为漫画风格。
-
### 1、环境依赖
转换效果图如下:
-
paddlepaddle >= 1.8.0

-
paddlehub >= 1.8.0 |
[
如何安装paddlehub
](
../../../../docs/docs_ch/get_start/installation.rst
)

-
### 2、安装
**参数**
-
```shell
$ hub install animegan_v2_shinkai_33
```
-
如您安装时遇到问题,可参考:
[
零基础windows安装
](
../../../../docs/docs_ch/get_start/windows_quickstart.md
)
|
[
零基础Linux安装
](
../../../../docs/docs_ch/get_start/linux_quickstart.md
)
|
[
零基础MacOS安装
](
../../../../docs/docs_ch/get_start/mac_quickstart.md
)
*
images (list
\[
numpy.ndarray
\]
): 图片数据,ndarray.shape 为
\[
H, W, C
\]
,默认为 None;
## 三、模型API预测
*
paths (list
\[
str
\]
): 图片的路径,默认为 None;
*
visualization (bool): 是否将识别结果保存为图片文件,默认设为 False;
*
output
\_
dir (str): 图片的保存路径,默认设为 output;
*
min
\_
size (int): 输入图片的短边最小尺寸,默认设为 32;
*
max
\_
size (int): 输入图片的短边最大尺寸,默认设为 1024。
-
### 1、代码示例
**返回**
-
```python
import paddlehub as hub
import cv2
*
res (list
\[
numpy.ndarray
\]
): 输出图像数据,ndarray.shape 为
\[
H, W, C
\]
。
model = hub.Module(name="animegan_v2_shinkai_33")
result = model.style_transfer(images=[cv2.imread('/PATH/TO/IMAGE')])
# or
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
```
-
### 2、API
## 预测代码示例
-
```python
def style_transfer(images=None,
paths=None,
output_dir='output',
visualization=False,
min_size=32,
max_size=1024)
```
```
python
- 风格转换API,将输入的图片转换为漫画风格。
import
cv2
import
paddlehub
as
hub
# 模型加载
- **参数**
# use_gpu:是否使用GPU进行预测
model
=
hub
.
Module
(
name
=
'animegan_v2_shinkai_33'
,
use_gpu
=
False
)
# 模型预测
- images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\];<br/>
result
=
model
.
style_transfer
(
images
=
[
cv2
.
imread
(
'/PATH/TO/IMAGE'
)])
- paths (list\[str\]): 图片的路径;<br/>
- output\_dir (str): 图片的保存路径,默认设为 output;<br/>
- visualization (bool): 是否将识别结果保存为图片文件;<br/>
- min\_size (int): 输入图片的短边最小尺寸,默认设为 32;<br/>
- max\_size (int): 输入图片的短边最大尺寸,默认设为 1024。
# or
**NOTE:** paths和images两个参数选择其一进行提供数据
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
```
## 服务部署
- **返回**
- res (list\[numpy.ndarray\]): 输出图像数据,ndarray.shape 为 \[H, W, C\]
PaddleHub Serving可以部署一个在线图像风格转换服务。
##
第一步:启动PaddleHub Serving
##
四、服务部署
运行启动命令:
-
PaddleHub Serving可以部署一个在线图像风格转换服务。
```
shell
$
hub serving start
-m
animegan_v2_shinkai_33
```
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866。
-
### 第一步:启动PaddleHub Serving
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
-
运行启动命令:
-
```shell
$ hub serving start -m animegan_v2_shinkai_33
```
## 第二步:发送预测请求
-
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866。
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
```
python
-
### 第二步:发送预测请求
import
requests
import
json
import
cv2
import
base64
-
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
def
cv2_to_base64
(
image
):
-
```python
data
=
cv2
.
imencode
(
'.jpg'
,
image
)[
1
]
import requests
return
base64
.
b64encode
(
data
.
tostring
()).
decode
(
'utf8'
)
import json
import cv2
import base64
# 发送HTTP请求
def cv2_to_base64(image):
data
=
{
'images'
:[
cv2_to_base64
(
cv2
.
imread
(
"/PATH/TO/IMAGE"
))]}
data = cv2.imencode('.jpg', image)[1]
headers
=
{
"Content-type"
:
"application/json"
}
return base64.b64encode(data.tostring()).decode('utf8')
url
=
"http://127.0.0.1:8866/predict/animegan_v2_shinkai_33"
r
=
requests
.
post
(
url
=
url
,
headers
=
headers
,
data
=
json
.
dumps
(
data
))
# 打印预测结果
# 发送HTTP请求
print
(
r
.
json
()[
"results"
])
data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
```
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/animegan_v2_shinkai_33"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
print(r.json()["results"])
```
## 模型相关信息
##
# 模型代码
##
五、更新历史
https://github.com/TachibanaYoshino/AnimeGANv2
*
1.0.0
### 依赖
初始发布
paddlepaddle >= 1.8.0
*
1.0.1
paddlehub >= 1.8.0
适配paddlehub2.0
*
1.0.2
删除batch_size选项
-
```shell
$ hub install animegan_v2_shinkai_33==1.0.2
```
modules/thirdparty/image/Image_gan/style_transfer/animegan_v2_shinkai_53/README.md
浏览文件 @
e80dbf15
## 模型概述
# animegan_v2_shinkai_53
AnimeGAN V2 图像风格转换模型
模型可将输入的图像转换成Shinkai风格
|模型名称|animegan_v2_shinkai_53|
| :--- | :---: |
|类别|图像 - 图像生成|
|网络|AnimeGAN|
|数据集|Your Name, Weathering with you|
|是否支持Fine-tuning|否|
|模型大小|9.4MB|
|最新更新日期|2021-07-30|
|数据指标|-|
模型权重转换自AnimeGAN V2官方开源项目
模型所使用的权重为Shinkai-53.ckpt
## 一、模型基本信息
模型详情请参考
[
AnimeGAN V2 开源项目
](
https://github.com/TachibanaYoshino/AnimeGANv2
)
-
### 应用效果展示
-
样例结果示例:
<p
align=
"center"
>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/bd002c4bb6a7427daf26988770bb18648b7d8d2bfd6746bfb9a429db4867727f"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输入图像
<br
/>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/fa4ba157e73c48658c4c9c6b8b92f5c99231d1d19556472788b1e5dd58d5d6cc"
width =
"450"
height =
"300"
hspace=
'10'
/>
<br
/>
输出图像
<br
/>
</p>
## 模型安装
```
shell
-
### 模型介绍
$hub
install
animegan_v2_shinkai_53
```
-
AnimeGAN V2 图像风格转换模型, 模型可将输入的图像转换成新海诚动漫风格,模型权重转换自
[
AnimeGAN V2官方开源项目
](
https://github.com/TachibanaYoshino/AnimeGANv2
)
。
## API 说明
```
python
## 二、安装
def
style_transfer
(
self
,
images
=
None
,
paths
=
None
,
output_dir
=
'output'
,
visualization
=
False
,
min_size
=
32
,
max_size
=
1024
)
```
风格转换API,将输入的图片转换为漫画风格。
-
### 1、环境依赖
转换效果图如下:
-
paddlepaddle >= 1.8.0

-
paddlehub >= 1.8.0 |
[
如何安装paddlehub
](
../../../../docs/docs_ch/get_start/installation.rst
)

-
### 2、安装
**参数**
-
```shell
$ hub install animegan_v2_shinkai_53
```
-
如您安装时遇到问题,可参考:
[
零基础windows安装
](
../../../../docs/docs_ch/get_start/windows_quickstart.md
)
|
[
零基础Linux安装
](
../../../../docs/docs_ch/get_start/linux_quickstart.md
)
|
[
零基础MacOS安装
](
../../../../docs/docs_ch/get_start/mac_quickstart.md
)
*
images (list
\[
numpy.ndarray
\]
): 图片数据,ndarray.shape 为
\[
H, W, C
\]
,默认为 None;
## 三、模型API预测
*
paths (list
\[
str
\]
): 图片的路径,默认为 None;
*
visualization (bool): 是否将识别结果保存为图片文件,默认设为 False;
*
output
\_
dir (str): 图片的保存路径,默认设为 output;
*
min
\_
size (int): 输入图片的短边最小尺寸,默认设为 32;
*
max
\_
size (int): 输入图片的短边最大尺寸,默认设为 1024。
-
### 1、代码示例
**返回**
-
```python
import paddlehub as hub
import cv2
*
res (list
\[
numpy.ndarray
\]
): 输出图像数据,ndarray.shape 为
\[
H, W, C
\]
。
model = hub.Module(name="animegan_v2_shinkai_53")
result = model.style_transfer(images=[cv2.imread('/PATH/TO/IMAGE')])
# or
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
```
-
### 2、API
## 预测代码示例
-
```python
def style_transfer(images=None,
paths=None,
output_dir='output',
visualization=False,
min_size=32,
max_size=1024)
```
```
python
- 风格转换API,将输入的图片转换为漫画风格。
import
cv2
import
paddlehub
as
hub
# 模型加载
- **参数**
# use_gpu:是否使用GPU进行预测
model
=
hub
.
Module
(
name
=
'animegan_v2_shinkai_53'
,
use_gpu
=
False
)
# 模型预测
- images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\];<br/>
result
=
model
.
style_transfer
(
images
=
[
cv2
.
imread
(
'/PATH/TO/IMAGE'
)])
- paths (list\[str\]): 图片的路径;<br/>
- output\_dir (str): 图片的保存路径,默认设为 output;<br/>
- visualization (bool): 是否将识别结果保存为图片文件;<br/>
- min\_size (int): 输入图片的短边最小尺寸,默认设为 32;<br/>
- max\_size (int): 输入图片的短边最大尺寸,默认设为 1024。
# or
**NOTE:** paths和images两个参数选择其一进行提供数据
# result = model.style_transfer(paths=['/PATH/TO/IMAGE'])
```
## 服务部署
- **返回**
- res (list\[numpy.ndarray\]): 输出图像数据,ndarray.shape 为 \[H, W, C\]
PaddleHub Serving可以部署一个在线图像风格转换服务。
##
第一步:启动PaddleHub Serving
##
四、服务部署
运行启动命令:
-
PaddleHub Serving可以部署一个在线图像风格转换服务。
```
shell
$
hub serving start
-m
animegan_v2_shinkai_53
```
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866。
-
### 第一步:启动PaddleHub Serving
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
-
运行启动命令:
-
```shell
$ hub serving start -m animegan_v2_shinkai_53
```
## 第二步:发送预测请求
-
这样就完成了一个图像风格转换的在线服务API的部署,默认端口号为8866。
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
**NOTE:**
如使用GPU预测,则需要在启动服务之前,请设置CUDA
\_
VISIBLE
\_
DEVICES环境变量,否则不用设置。
```
python
-
### 第二步:发送预测请求
import
requests
import
json
import
cv2
import
base64
-
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
def
cv2_to_base64
(
image
):
-
```python
data
=
cv2
.
imencode
(
'.jpg'
,
image
)[
1
]
import requests
return
base64
.
b64encode
(
data
.
tostring
()).
decode
(
'utf8'
)
import json
import cv2
import base64
# 发送HTTP请求
def cv2_to_base64(image):
data
=
{
'images'
:[
cv2_to_base64
(
cv2
.
imread
(
"/PATH/TO/IMAGE"
))]}
data = cv2.imencode('.jpg', image)[1]
headers
=
{
"Content-type"
:
"application/json"
}
return base64.b64encode(data.tostring()).decode('utf8')
url
=
"http://127.0.0.1:8866/predict/animegan_v2_shinkai_53"
r
=
requests
.
post
(
url
=
url
,
headers
=
headers
,
data
=
json
.
dumps
(
data
))
# 打印预测结果
# 发送HTTP请求
print
(
r
.
json
()[
"results"
])
data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
```
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/animegan_v2_shinkai_53"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
print(r.json()["results"])
```
## 模型相关信息
##
# 模型代码
##
五、更新历史
https://github.com/TachibanaYoshino/AnimeGANv2
*
1.0.0
### 依赖
初始发布
paddlepaddle >= 1.8.0
*
1.0.1
paddlehub >= 1.8.0
适配paddlehub2.0
*
1.0.2
删除batch_size选项
-
```shell
$ hub install animegan_v2_shinkai_53==1.0.2
```
modules/thirdparty/image/semantic_segmentation/FCN_HRNet_W18_Face_Seg/README.md
浏览文件 @
e80dbf15
## 概述
# FCN_HRNet_W18_Face_Seg
*
基于 FCN_HRNet_W18 模型实现的人像分割模型
|模型名称|FCN_HRNet_W18_Face_Seg|
## 效果展示
| :--- | :---: |

|类别|图像 - 图像生成|
|网络|FCN_HRNet_W18|
## API
|数据集|-|
```
python
|是否支持Fine-tuning|否|
def
Segmentation
(
|模型大小|56MB|
images
=
None
,
|最新更新日期|2021-02-26|
paths
=
None
,
|数据指标|-|
batch_size
=
1
,
output_dir
=
'output'
,
visualization
=
False
):
## 一、模型基本信息
```
人像分割 API
-
### 应用效果展示
-
样例结果示例:
**参数**
<p
align=
"center"
>
*
images (list[np.ndarray]) : 输入图像数据列表(BGR)
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/88155299a7534f1084f8467a4d6db7871dc4729627d3471c9129d316dc4ff9bc"
width=
'70%'
hspace=
'10'
/>
<br
/>
*
paths (list[str]) : 输入图像路径列表
</p>
*
batch_size (int) : 数据批大小
*
output_dir (str) : 可视化图像输出目录
*
visualization (bool) : 是否可视化
-
### 模型介绍
**返回**
-
基于 FCN_HRNet_W18模型实现的人像分割模型。
*
results (list[dict{"mask":np.ndarray,"face":np.ndarray}]): 输出图像数据列表
**代码示例**
## 二、安装
```
python
import
cv2
-
### 1、环境依赖
import
paddlehub
as
hub
-
paddlepaddle >= 2.0.0
model
=
hub
.
Module
(
name
=
'FCN_HRNet_W18_Face_Seg'
)
-
paddlehub >= 2.0.0 |
[
如何安装paddlehub
](
../../../../docs/docs_ch/get_start/installation.rst
)
result
=
model
.
Segmentation
(
images
=
[
cv2
.
imread
(
'/PATH/TO/IMAGE'
)],
-
### 2、安装
paths
=
None
,
batch_size
=
1
,
-
```shell
output_dir
=
'output'
,
$ hub install FCN_HRNet_W18_Face_Seg
visualization
=
True
)
```
```
-
如您安装时遇到问题,可参考:
[
零基础windows安装
](
../../../../docs/docs_ch/get_start/windows_quickstart.md
)
|
[
零基础Linux安装
](
../../../../docs/docs_ch/get_start/linux_quickstart.md
)
|
[
零基础MacOS安装
](
../../../../docs/docs_ch/get_start/mac_quickstart.md
)
## 查看代码
https://github.com/PaddlePaddle/PaddleSeg
## 三、模型API预测
https://github.com/minivision-ai/photo2cartoon-paddle
-
### 1、代码示例
## 依赖
paddlepaddle >= 2.0.0rc0
-
```python
paddlehub >= 2.0.0b1
import paddlehub as hub
import cv2
model = hub.Module(name="FCN_HRNet_W18_Face_Seg")
result = model.Segmentation(images=[cv2.imread('/PATH/TO/IMAGE')])
# or
# result = model.Segmentation(paths=['/PATH/TO/IMAGE'])
```
-
### 2、API
-
```python
def Segmentation(images=None,
paths=None,
batch_size=1,
output_dir='output',
visualization=False):
```
-
人像分割API。
-
**参数**
-
images (list
\[
numpy.ndarray
\]
): 图片数据,ndarray.shape 为
\[
H, W, C
\]
;
<br/>
-
paths (list
\[
str
\]
): 输入图像路径;
<br/>
-
batch_size (int) : batch大小;
<br/>
-
output
\_
dir (str): 图片的保存路径,默认设为 output;
<br/>
-
visualization (bool) : 是否将结果保存为图片文件;;
<br/>
**NOTE:**
paths和images两个参数选择其一进行提供数据
-
**返回**
-
res (list
\[
numpy.ndarray
\]
): 输出图像数据,ndarray.shape 为
\[
H, W, C
\]
## 四、更新历史
*
1.0.0
初始发布
-
```shell
$ hub install FCN_HRNet_W18_Face_Seg==1.0.0
```
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录