Merge branch 'release/v1.2' into develop
Showing
{kind=link}
因为 它太大了无法显示 image diff 。你可以改为 查看blob。
docs/imgs/pbt_optimization.gif
0 → 100644
{kind=link}
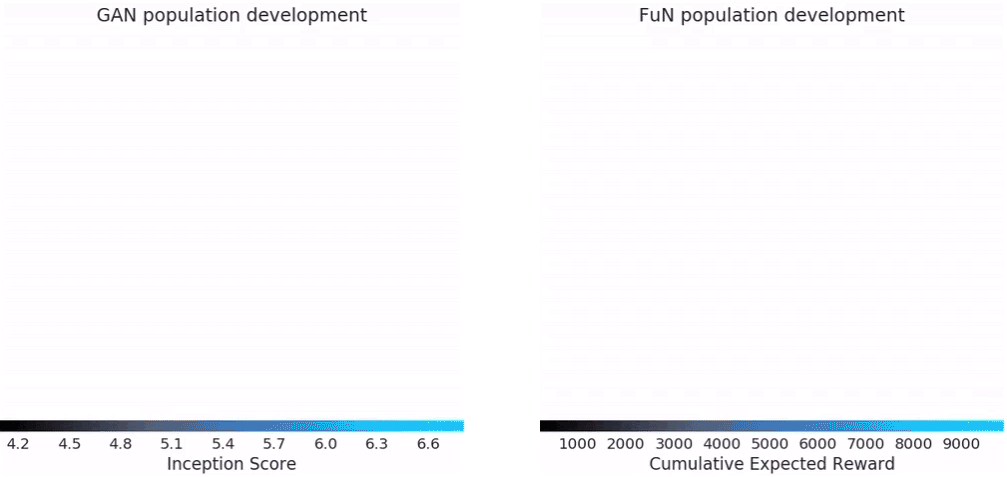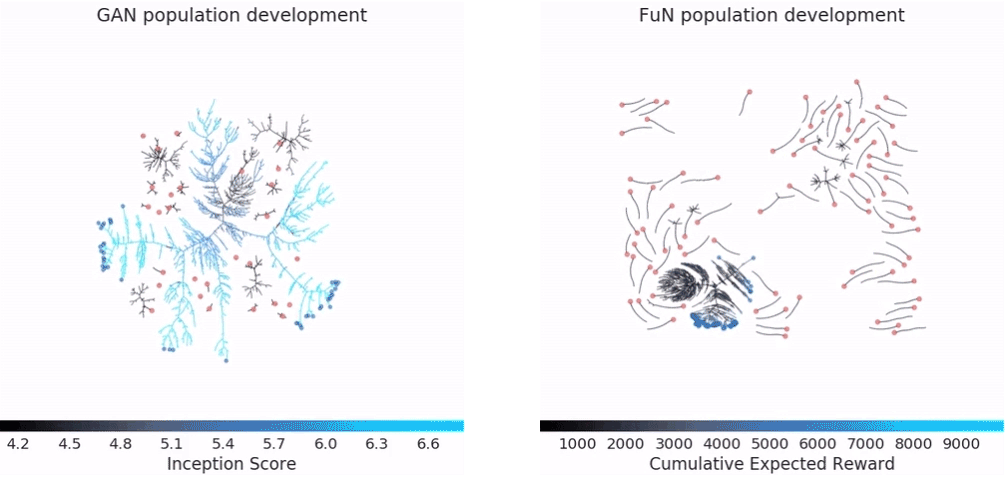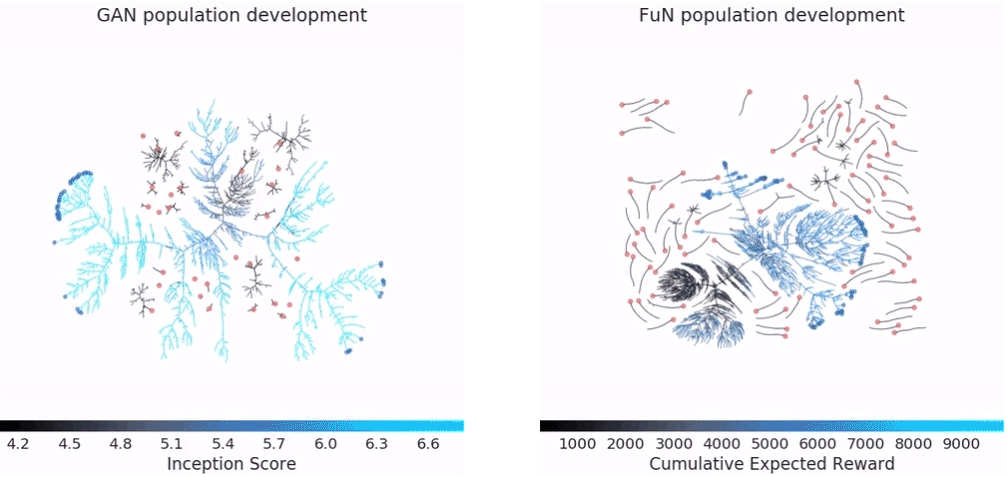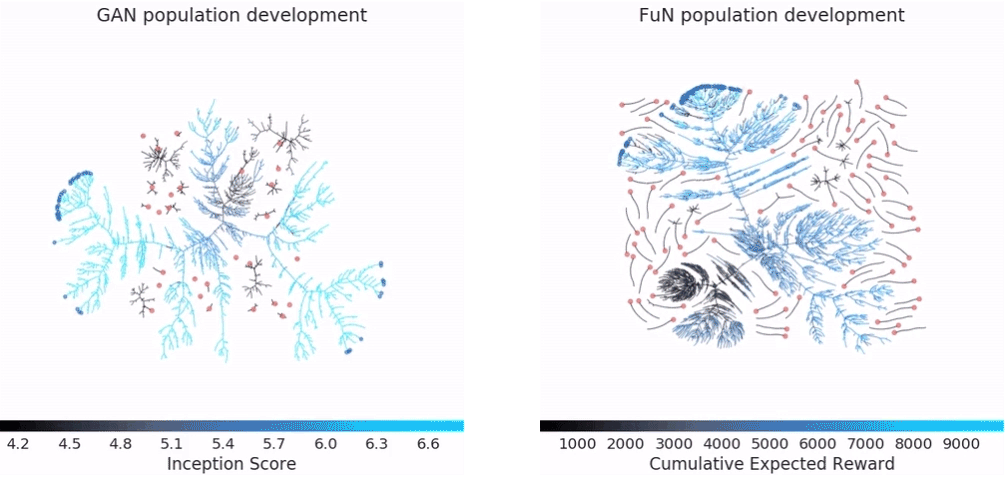
2.0 MB
docs/imgs/thermodynamics.gif
0 → 100644
{kind=link}
873.4 KB
tutorial/sentence_sim.ipynb
已删除
100644 → 0
tutorial/sentence_sim.md
0 → 100644