Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleHub
提交
9c1fb388
P
PaddleHub
项目概览
PaddlePaddle
/
PaddleHub
大约 2 年 前同步成功
通知
285
Star
12117
Fork
2091
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
200
列表
看板
标记
里程碑
合并请求
4
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleHub
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
200
Issue
200
列表
看板
标记
里程碑
合并请求
4
合并请求
4
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
9c1fb388
编写于
6月 15, 2021
作者:
K
KP
提交者:
GitHub
6月 15, 2021
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Update requirements and README.md of lstm_tacotron2
上级
50dd5bf5
变更
10
隐藏空白更改
内联
并排
Showing
10 changed file
with
111 addition
and
93 deletion
+111
-93
modules/audio/audio_classification/PANNs/cnn10/module.py
modules/audio/audio_classification/PANNs/cnn10/module.py
+1
-1
modules/audio/audio_classification/PANNs/cnn14/module.py
modules/audio/audio_classification/PANNs/cnn14/module.py
+1
-1
modules/audio/audio_classification/PANNs/cnn6/module.py
modules/audio/audio_classification/PANNs/cnn6/module.py
+1
-1
modules/audio/voice_cloning/lstm_tacotron2/README.md
modules/audio/voice_cloning/lstm_tacotron2/README.md
+102
-0
modules/audio/voice_cloning/lstm_tacotron2/module.py
modules/audio/voice_cloning/lstm_tacotron2/module.py
+2
-7
modules/audio/voice_cloning/lstm_tacotron2/preprocess_transcription.py
.../voice_cloning/lstm_tacotron2/preprocess_transcription.py
+0
-73
modules/audio/voice_cloning/lstm_tacotron2/requirements.txt
modules/audio/voice_cloning/lstm_tacotron2/requirements.txt
+1
-7
modules/text/text_generation/plato-mini/module.py
modules/text/text_generation/plato-mini/module.py
+1
-1
modules/text/text_generation/unified_transformer-12L-cn-luge/module.py
...text_generation/unified_transformer-12L-cn-luge/module.py
+1
-1
modules/text/text_generation/unified_transformer-12L-cn/module.py
...text/text_generation/unified_transformer-12L-cn/module.py
+1
-1
未找到文件。
modules/audio/audio_classification/PANNs/cnn10/module.py
浏览文件 @
9c1fb388
...
@@ -31,7 +31,7 @@ from paddlehub.utils.log import logger
...
@@ -31,7 +31,7 @@ from paddlehub.utils.log import logger
name
=
"panns_cnn10"
,
name
=
"panns_cnn10"
,
version
=
"1.0.0"
,
version
=
"1.0.0"
,
summary
=
""
,
summary
=
""
,
author
=
"
Baidu
"
,
author
=
"
paddlepaddle
"
,
author_email
=
""
,
author_email
=
""
,
type
=
"audio/sound_classification"
,
type
=
"audio/sound_classification"
,
meta
=
AudioClassifierModule
)
meta
=
AudioClassifierModule
)
...
...
modules/audio/audio_classification/PANNs/cnn14/module.py
浏览文件 @
9c1fb388
...
@@ -31,7 +31,7 @@ from paddlehub.utils.log import logger
...
@@ -31,7 +31,7 @@ from paddlehub.utils.log import logger
name
=
"panns_cnn14"
,
name
=
"panns_cnn14"
,
version
=
"1.0.0"
,
version
=
"1.0.0"
,
summary
=
""
,
summary
=
""
,
author
=
"
Baidu
"
,
author
=
"
paddlepaddle
"
,
author_email
=
""
,
author_email
=
""
,
type
=
"audio/sound_classification"
,
type
=
"audio/sound_classification"
,
meta
=
AudioClassifierModule
)
meta
=
AudioClassifierModule
)
...
...
modules/audio/audio_classification/PANNs/cnn6/module.py
浏览文件 @
9c1fb388
...
@@ -31,7 +31,7 @@ from paddlehub.utils.log import logger
...
@@ -31,7 +31,7 @@ from paddlehub.utils.log import logger
name
=
"panns_cnn6"
,
name
=
"panns_cnn6"
,
version
=
"1.0.0"
,
version
=
"1.0.0"
,
summary
=
""
,
summary
=
""
,
author
=
"
Baidu
"
,
author
=
"
paddlepaddle
"
,
author_email
=
""
,
author_email
=
""
,
type
=
"audio/sound_classification"
,
type
=
"audio/sound_classification"
,
meta
=
AudioClassifierModule
)
meta
=
AudioClassifierModule
)
...
...
modules/audio/voice_cloning/lstm_tacotron2/README.md
0 → 100644
浏览文件 @
9c1fb388
```
shell
$
hub
install
lstm_tacotron2
==
1.0.0
```
## 概述
声音克隆是指使用特定的音色,结合文字的读音合成音频,使得合成后的音频具有目标说话人的特征,从而达到克隆的目的。
在训练语音克隆模型时,目标音色作为Speaker Encoder的输入,模型会提取这段语音的说话人特征(音色)作为Speaker Embedding。接着,在训练模型重新合成此类音色的语音时,除了输入的目标文本外,说话人的特征也将成为额外条件加入模型的训练。
在预测时,选取一段新的目标音色作为Speaker Encoder的输入,并提取其说话人特征,最终实现输入为一段文本和一段目标音色,模型生成目标音色说出此段文本的语音片段。
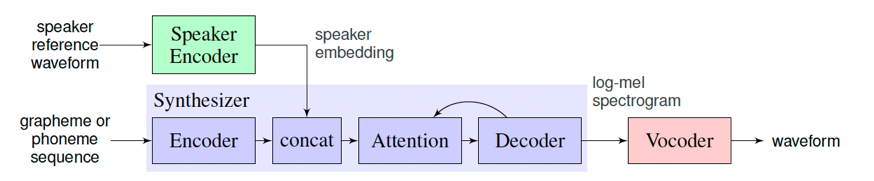
`lstm_tacotron2`
是一个支持中文的语音克隆模型,分别使用了LSTMSpeakerEncoder、Tacotron2和WaveFlow模型分别用于语音特征提取、目标音频特征合成和语音波形转换。
关于模型的详请可参考
[
Parakeet
](
https://github.com/PaddlePaddle/Parakeet/tree/release/v0.3/parakeet/models
)
。
## API
```
python
def
__init__
(
speaker_audio
:
str
=
None
,
output_dir
:
str
=
'./'
)
```
初始化module,可配置模型的目标音色的音频文件和输出的路径。
**参数**
-
`speaker_audio`
(str): 目标说话人语音音频文件(
*
.wav)的路径,默认为None(使用默认的女声作为目标音色)。
-
`output_dir`
(str): 合成音频的输出文件,默认为当前目录。
```
python
def
get_speaker_embedding
()
```
获取模型的目标说话人特征。
**返回**
*
`results`
(numpy.ndarray): 长度为256的numpy数组,代表目标说话人的特征。
```
python
def
set_speaker_embedding
(
speaker_audio
:
str
)
```
设置模型的目标说话人特征。
**参数**
-
`speaker_audio`
(str): 必填,目标说话人语音音频文件(
*
.wav)的路径。
```
python
def
generate
(
data
:
List
[
str
],
batch_size
:
int
=
1
,
use_gpu
:
bool
=
False
):
```
根据输入文字,合成目标说话人的语音音频文件。
**参数**
-
`data`
(List[str]): 必填,目标音频的内容文本列表,目前只支持中文,不支持添加标点符号。
-
`batch_size`
(int): 可选,模型合成语音时的batch_size,默认为1。
-
`use_gpu`
(bool): 是否使用gpu执行计算,默认为False。
**代码示例**
```
python
import
paddlehub
as
hub
model
=
hub
.
Module
(
name
=
'lstm_tacotron2'
,
output_dir
=
'./'
,
speaker_audio
=
'/data/man.wav'
)
# 指定目标音色音频文件
texts
=
[
'语音的表现形式在未来将变得越来越重要$'
,
'今天的天气怎么样$'
,
]
wavs
=
model
.
generate
(
texts
,
use_gpu
=
True
)
for
text
,
wav
in
zip
(
texts
,
wavs
):
print
(
'='
*
30
)
print
(
f
'Text:
{
text
}
'
)
print
(
f
'Wav:
{
wav
}
'
)
```
输出
```
==============================
Text: 语音的表现形式在未来将变得越来越重要$
Wav: /data/1.wav
==============================
Text: 今天的天气怎么样$
Wav: /data/2.wav
```
## 查看代码
https://github.com/PaddlePaddle/Parakeet
## 依赖
paddlepaddle >= 2.0.0
paddlehub >= 2.1.0
## 更新历史
* 1.0.0
初始发布
modules/audio/voice_cloning/lstm_tacotron2/module.py
浏览文件 @
9c1fb388
...
@@ -23,14 +23,9 @@ from paddlehub.env import MODULE_HOME
...
@@ -23,14 +23,9 @@ from paddlehub.env import MODULE_HOME
from
paddlehub.module.module
import
moduleinfo
from
paddlehub.module.module
import
moduleinfo
from
paddlehub.utils.log
import
logger
from
paddlehub.utils.log
import
logger
from
paddlenlp.data
import
Pad
from
paddlenlp.data
import
Pad
import
soundfile
as
sf
if
not
importlib
.
util
.
find_spec
(
'parakeet'
):
raise
ImportError
(
'The module requires additional dependencies: "parakeet".
\n
'
'You can install parakeet via "git clone https://github.com'
'/PaddlePaddle/Parakeet -b release/v0.3 && pip install -e Parakeet"'
)
from
parakeet.models
import
ConditionalWaveFlow
,
Tacotron2
from
parakeet.models
import
ConditionalWaveFlow
,
Tacotron2
from
parakeet.models.lstm_speaker_encoder
import
LSTMSpeakerEncoder
from
parakeet.models.lstm_speaker_encoder
import
LSTMSpeakerEncoder
import
soundfile
as
sf
from
.audio_processor
import
SpeakerVerificationPreprocessor
from
.audio_processor
import
SpeakerVerificationPreprocessor
from
.chinese_g2p
import
convert_sentence
from
.chinese_g2p
import
convert_sentence
...
@@ -41,7 +36,7 @@ from .preprocess_transcription import voc_phones, voc_tones, phone_pad_token, to
...
@@ -41,7 +36,7 @@ from .preprocess_transcription import voc_phones, voc_tones, phone_pad_token, to
name
=
"lstm_tacotron2"
,
name
=
"lstm_tacotron2"
,
version
=
"1.0.0"
,
version
=
"1.0.0"
,
summary
=
""
,
summary
=
""
,
author
=
"
Baidu
"
,
author
=
"
paddlepaddle
"
,
author_email
=
""
,
author_email
=
""
,
type
=
"audio/voice_cloning"
,
type
=
"audio/voice_cloning"
,
)
)
...
...
modules/audio/voice_cloning/lstm_tacotron2/preprocess_transcription.py
浏览文件 @
9c1fb388
...
@@ -19,7 +19,6 @@ import re
...
@@ -19,7 +19,6 @@ import re
from
parakeet.frontend
import
Vocab
from
parakeet.frontend
import
Vocab
import
tqdm
import
tqdm
import
yaml
zh_pattern
=
re
.
compile
(
"[
\u4e00
-
\u9fa5
]"
)
zh_pattern
=
re
.
compile
(
"[
\u4e00
-
\u9fa5
]"
)
...
@@ -180,75 +179,3 @@ def split_syllable(syllable: str):
...
@@ -180,75 +179,3 @@ def split_syllable(syllable: str):
phones
.
append
(
syllable
)
phones
.
append
(
syllable
)
tones
.
append
(
tone
)
tones
.
append
(
tone
)
return
phones
,
tones
return
phones
,
tones
def
load_aishell3_transcription
(
line
:
str
):
sentence_id
,
pinyin
,
text
=
line
.
strip
().
split
(
"|"
)
syllables
=
pinyin
.
strip
().
split
()
results
=
[]
for
syllable
in
syllables
:
if
syllable
in
_pauses
:
results
.
append
(
syllable
)
elif
not
ernized
(
syllable
):
results
.
append
(
syllable
)
else
:
results
.
append
(
syllable
[:
-
2
]
+
syllable
[
-
1
])
results
.
append
(
'&r5'
)
phones
=
[]
tones
=
[]
for
syllable
in
results
:
p
,
t
=
split_syllable
(
syllable
)
phones
.
extend
(
p
)
tones
.
extend
(
t
)
for
p
in
phones
:
assert
p
in
_phones
,
p
return
{
"sentence_id"
:
sentence_id
,
"text"
:
text
,
"syllables"
:
results
,
"phones"
:
phones
,
"tones"
:
tones
}
def
process_aishell3
(
dataset_root
,
output_dir
):
dataset_root
=
Path
(
dataset_root
).
expanduser
()
output_dir
=
Path
(
output_dir
).
expanduser
()
output_dir
.
mkdir
(
parents
=
True
,
exist_ok
=
True
)
prosody_label_path
=
dataset_root
/
"label_train-set.txt"
with
open
(
prosody_label_path
,
'rt'
)
as
f
:
lines
=
[
line
.
strip
()
for
line
in
f
]
records
=
lines
[
5
:]
processed_records
=
[]
for
record
in
tqdm
.
tqdm
(
records
):
new_record
=
load_aishell3_transcription
(
record
)
processed_records
.
append
(
new_record
)
print
(
new_record
)
with
open
(
output_dir
/
"metadata.pickle"
,
'wb'
)
as
f
:
pickle
.
dump
(
processed_records
,
f
)
with
open
(
output_dir
/
"metadata.yaml"
,
'wt'
,
encoding
=
"utf-8"
)
as
f
:
yaml
.
safe_dump
(
processed_records
,
f
,
default_flow_style
=
None
,
allow_unicode
=
True
)
print
(
"metadata done!"
)
if
__name__
==
"__main__"
:
parser
=
argparse
.
ArgumentParser
(
description
=
"Preprocess transcription of AiShell3 and save them in a compact file(yaml and pickle)."
)
parser
.
add_argument
(
"--input"
,
type
=
str
,
default
=
"~/datasets/aishell3/train"
,
help
=
"path of the training dataset,(contains a label_train-set.txt)."
)
parser
.
add_argument
(
"--output"
,
type
=
str
,
help
=
"the directory to save the processed transcription."
"If not provided, it would be the same as the input."
)
args
=
parser
.
parse_args
()
if
args
.
output
is
None
:
args
.
output
=
args
.
input
process_aishell3
(
args
.
input
,
args
.
output
)
modules/audio/voice_cloning/lstm_tacotron2/requirements.txt
浏览文件 @
9c1fb388
librosa
paddle-parakeet
nltk
pypinyin
scipy
soundfile
webrtcvad
yaml
modules/text/text_generation/plato-mini/module.py
浏览文件 @
9c1fb388
...
@@ -30,7 +30,7 @@ from plato_mini.utils import select_response
...
@@ -30,7 +30,7 @@ from plato_mini.utils import select_response
name
=
"plato-mini"
,
name
=
"plato-mini"
,
version
=
"1.0.0"
,
version
=
"1.0.0"
,
summary
=
""
,
summary
=
""
,
author
=
"
PaddleP
addle"
,
author
=
"
paddlep
addle"
,
author_email
=
""
,
author_email
=
""
,
type
=
"nlp/text_generation"
,
type
=
"nlp/text_generation"
,
)
)
...
...
modules/text/text_generation/unified_transformer-12L-cn-luge/module.py
浏览文件 @
9c1fb388
...
@@ -30,7 +30,7 @@ from unified_transformer_12L_cn_luge.utils import select_response
...
@@ -30,7 +30,7 @@ from unified_transformer_12L_cn_luge.utils import select_response
name
=
"unified_transformer_12L_cn_luge"
,
name
=
"unified_transformer_12L_cn_luge"
,
version
=
"1.0.0"
,
version
=
"1.0.0"
,
summary
=
""
,
summary
=
""
,
author
=
"
PaddleP
addle"
,
author
=
"
paddlep
addle"
,
author_email
=
""
,
author_email
=
""
,
type
=
"nlp/text_generation"
,
type
=
"nlp/text_generation"
,
)
)
...
...
modules/text/text_generation/unified_transformer-12L-cn/module.py
浏览文件 @
9c1fb388
...
@@ -30,7 +30,7 @@ from unified_transformer_12L_cn.utils import select_response
...
@@ -30,7 +30,7 @@ from unified_transformer_12L_cn.utils import select_response
name
=
"unified_transformer_12L_cn"
,
name
=
"unified_transformer_12L_cn"
,
version
=
"1.0.0"
,
version
=
"1.0.0"
,
summary
=
""
,
summary
=
""
,
author
=
"
PaddleP
addle"
,
author
=
"
paddlep
addle"
,
author_email
=
""
,
author_email
=
""
,
type
=
"nlp/text_generation"
,
type
=
"nlp/text_generation"
,
)
)
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录