Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleHub
提交
4a181c3a
P
PaddleHub
项目概览
PaddlePaddle
/
PaddleHub
大约 2 年 前同步成功
通知
285
Star
12117
Fork
2091
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
200
列表
看板
标记
里程碑
合并请求
4
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleHub
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
200
Issue
200
列表
看板
标记
里程碑
合并请求
4
合并请求
4
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
4a181c3a
编写于
4月 15, 2019
作者:
Z
zhangxuefei
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'develop' of
https://github.com/PaddlePaddle/PaddleHub
into develop
上级
ee97ddf1
7005d9c0
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
197 addition
and
39 deletion
+197
-39
README.md
README.md
+1
-1
demo/text-classification/README.md
demo/text-classification/README.md
+9
-0
demo/text-classification/text_classifier.py
demo/text-classification/text_classifier.py
+2
-1
docs/turtorial/cv_finetune_turtorial.md
docs/turtorial/cv_finetune_turtorial.md
+183
-0
docs/turtorial/transfer_learning_turtorial.md
docs/turtorial/transfer_learning_turtorial.md
+2
-37
未找到文件。
README.md
浏览文件 @
4a181c3a
...
...
@@ -47,7 +47,7 @@ $ hub search
## 深入了解PaddleHub
*
[
命令行功能
](
https://github.com/PaddlePaddle/PaddleHub/tree/develop/docs/command_line_introduction.md
)
*
[
Finetune API与迁移学习
](
https://github.com/PaddlePaddle/PaddleHub/tree/develop/docs/transfer_learning_turtorial.md
)
*
[
Finetune API与迁移学习
](
https://github.com/PaddlePaddle/PaddleHub/tree/develop/docs/t
urtorial/t
ransfer_learning_turtorial.md
)
*
API
## 答疑
...
...
demo/text-classification/README.md
浏览文件 @
4a181c3a
...
...
@@ -139,6 +139,15 @@ hub.finetune_and_eval(task=cls_task, data_reader=reader, feed_list=feed_list, co
*
`enable_memory_optim`
: 是否使用内存优化, 默认为True
*
`strategy`
: Finetune优化策略
## VisualDL 可视化
Finetune API训练过程中会自动对关键训练指标进行打点,启动程序后执行下面命令
```
bash
$
visualdl
--logdir
$CKPT_DIR
/vdllog
-t
0.0.0.0
```
用浏览器打开http://localhost:8040 即可看到训练过程中指标的变化情况
TODO: 新增截图
## 模型预测
通过Finetune完成模型训练后,在对应的ckpt目录下,会自动保存验证集上效果最好的模型。
...
...
demo/text-classification/text_classifier.py
浏览文件 @
4a181c3a
...
...
@@ -22,6 +22,7 @@ import paddlehub as hub
# yapf: disable
parser
=
argparse
.
ArgumentParser
(
__doc__
)
parser
.
add_argument
(
"--num_epoch"
,
type
=
int
,
default
=
3
,
help
=
"Number of epoches for fine-tuning."
)
parser
.
add_argument
(
"--use_gpu"
,
type
=
ast
.
literal_eval
,
default
=
False
,
help
=
"Whether use GPU for finetuning, input should be True or False"
)
parser
.
add_argument
(
"--dataset"
,
type
=
str
,
default
=
"chnsenticorp"
,
help
=
"Directory to model checkpoint"
,
choices
=
[
"chnsenticorp"
,
"nlpcc_dbqa"
,
"lcqmc"
])
parser
.
add_argument
(
"--learning_rate"
,
type
=
float
,
default
=
5e-5
,
help
=
"Learning rate used to train with warmup."
)
parser
.
add_argument
(
"--weight_decay"
,
type
=
float
,
default
=
0.01
,
help
=
"Weight decay rate for L2 regularizer."
)
...
...
@@ -71,7 +72,7 @@ if __name__ == '__main__':
inputs
[
"segment_ids"
].
name
,
inputs
[
"input_mask"
].
name
,
label
.
name
]
# Define a classfication finetune task by PaddleHub's API
cls_task
=
hub
.
create_text_cl
assification
_task
(
cls_task
=
hub
.
create_text_cl
s
_task
(
feature
=
pooled_output
,
label
=
label
,
num_classes
=
dataset
.
num_labels
)
# Step4: Select finetune strategy, setup config and finetune
...
...
docs/turtorial/cv_finetune_turtorial.md
0 → 100644
浏览文件 @
4a181c3a
# 在PaddleHub中进行Finetune
Finetune是
[
迁移学习
](
https://github.com/PaddlePaddle/PaddleHub/blob/develop/docs/transfer_learning_turtorial.md
)
中使用得最多的技巧。
其主要理念在于,通过对预训练模型进行结构和参数的
`微调`
来实现模型迁移,从而达到迁移学习的目的。
本文以Kaggle的猫狗分类数据集为例子,详细了介绍如何在PaddleHub中进行CV方向的finetune
## 一、准备工作
在开始进行finetune前,我们需要完成以下几个工作准备
### 1. 安装PaddlePaddle
PaddleHub是基于PaddlePaddle的预训练模型管理框架,使用PaddleHub前需要先安装PaddlePaddle,如果您本地已经安装了cpu或者gpu版本的PaddlePaddle,那么可以跳过以下安装步骤。
```
shell
# 安装cpu版本的PaddlePaddle
$
pip
install
paddlepaddle
```
我们推荐您使用大于1.3.0版本的PaddlePaddle,如果您本地版本较低,使用如下命令进行升级
```
shell
$
pip
install
--upgrade
paddlepaddle
```
在安装过程中如果遇到问题,您可以到
[
Paddle官方网站
](
http://www.paddlepaddle.org/
)
上查看解决方案
### 2. 安装PaddleHub
通过以下命令来安装PaddleHub
```
shell
$
pip
install
paddlehub
```
如果在安装过程中遇到问题,您可以查看下
[
FAQ
](
https://github.com/PaddlePaddle/PaddleHub/blob/develop/docs/FAQ.md
)
来查找问题解决方案,如果无法解决,请在issue中反馈问题,我们会尽快分析解决
## 二、挑选合适的模型
首先导入必要的python包
```
python
# -*- coding: utf8 -*-
import
paddlehub
as
hub
import
paddle.fluid
as
fluid
```
接下来我们要在PaddleHub中选择合适的预训练模型来Finetune,由于猫狗分类是一个图像分类任务,因此我们使用resnet50作为预训练模型(PaddleHub提供了丰富的预训练模型,我们建议您尝试不同的预训练模型来获得更好的性能)
```
python
cv_classifer_module
=
hub
.
Module
(
name
=
"resnet_v2_50_imagenet"
)
# cv_classifer_module = hub.Module(name = "resnet_v2_101_imagenet")
# cv_classifer_module = hub.Module(name = "resnet_v2_152_imagenet")
# cv_classifer_module = hub.Module(name = "nasnet_imagenet")
# cv_classifer_module = hub.Module(name = "mobilenet_v2_imagenet")
```
## 三、数据准备
接着需要加载图片数据集。我们需要自己切分数据集,将数据集且分为训练集、验证集和测试集。
同时使用三个文本文件来记录对应的图片路径和标签
├─data: 数据目录
├─train_list.txt:训练集数据列表
├─test_list.txt:测试集数据列表
├─validate_list:验证集数据列表
└─……
每个文件的格式如下
```
text
图片1路径 图片1标签
图片2路径 图片2标签
……
```
使用如下的方式进行加载数据,生成数据集对象
```
python
# 使用本地数据集
class
mydataset
(
paddlehub
.
ImageClassificationDataset
):
self
.
base_path
=
"data"
self
.
train_list_file
=
"train_list.txt"
self
.
test_list_file
=
"test_list.txt"
self
.
validate_list_file
=
"validate_list.txt"
self
.
num_labels
=
2
dataset
=
mydataset
()
```
如果想要快速体验finetune的流程,可以直接加载paddlehub提供的猫狗分类数据集
```
python
# 直接用PaddleHub提供的数据集
dataset
=
paddlehub
.
dataset
.
dogcat
()
```
接着生成一个图像分类的reader,reader负责将dataset的数据进行预处理,接着以特定格式组织并输入给模型进行训练。
当我们生成一个图像分类的reader时,需要指定输入图片的大小
```
python
data_reader
=
hub
.
reader
.
ImageClassificationReader
(
image_width
=
cv_classifer_module
.
get_expected_image_width
(),
image_height
=
cv_classifer_module
.
get_expected_image_height
(),
images_mean
=
cv_classifer_module
.
get_pretrained_images_mean
(),
images_std
=
cv_classifer_module
.
get_pretrained_images_std
(),
dataset
=
dataset
)
```
## 四、组建Finetune Task
有了合适的预训练模型和准备要迁移的数据集后,我们开始组建一个Task。
由于猫狗分类是一个二分类的任务,而我们下载的cv_classifer_module是在ImageNet数据集上训练的千分类模型,所以我们需要对模型进行简单的微调,把模型改造为一个二分类模型:
1.
获取cv_classifer_module的上下文环境,包括输入和输出的变量,以及Paddle Program
2.
从输出变量中找到特征图提取层feature_map
3.
在feature_map后面接入一个全连接层,生成Task
```
python
input_dict
,
output_dict
,
program
=
cv_classifer_module
.
context
(
trainable
=
True
)
with
fluid
.
program_guard
(
program
):
label
=
fluid
.
layers
.
data
(
name
=
"label"
,
dtype
=
"int64"
,
shape
=
[
1
])
img
=
input_dict
[
"image"
]
feature_map
=
output_dict
[
"feature_map"
]
feed_list
=
[
img
.
name
,
label
.
name
]
task
=
hub
.
create_img_classification_task
(
feature
=
feature_map
,
label
=
label
,
num_classes
=
dataset
.
num_labels
)
```
## 五、选择运行时配置
在进行Finetune前,我们可以设置一些运行时的配置,例如如下代码中的配置,表示:
`epoch`
:要求Finetune的任务只遍历10次训练集
`batch_size`
:每次训练的时候,给模型输入的每批数据大小为32,模型训练时能够并行处理批数据,因此batch_size越大,训练的效率越高,但是同时带来了内存的负荷,过大的batch_size可能导致内存不足而无法训练,因此选择一个合适的batch_size是很重要的一步。
`log_interval`
:每隔10 step打印一次训练日志
`eval_interval`
:每隔50 step在验证集上进行一次性能评估。
`checkpoint_dir`
:将训练的参数和数据保存到cv_finetune_turtorial_demo目录中
更多运行配置,请查看
[
RunConfig
](
https://github.com/PaddlePaddle/PaddleHub/tree/develop/docs/API.md
)
```
python
config
=
hub
.
RunConfig
(
num_epoch
=
10
,
checkpoint_dir
=
"cv_finetune_turtorial_demo"
,
batch_size
=
32
,
log_interval
=
10
,
eval_interval
=
50
)
```
## 六、开始Finetune
我们选择
`finetune_and_eval`
接口来进行模型训练,这个接口在finetune的过程中,会周期性的进行模型效果的评估,以便我们了解整个训练过程的性能变化。如果您并不关心中间过程数据,那么可以使用
`finetune`
接口来替代
```
python
hub
.
finetune_and_eval
(
task
,
feed_list
=
feed_list
,
data_reader
=
data_reader
,
config
=
config
)
```
## 七、查看训练过程的效果
训练过程中的性能数据会被记录到本地,我们可以通过visualdl来可视化这些数据
我们在shell中输入以下命令来启动visualdl
```
shell
$
visualdl
--logdir
./cv_finetune_turtorial_demo
--host
${
HOST_IP
}
```
启动服务后,我们使用浏览器访问指定的url,可以看到训练以及预测的loss曲线和accuracy曲线
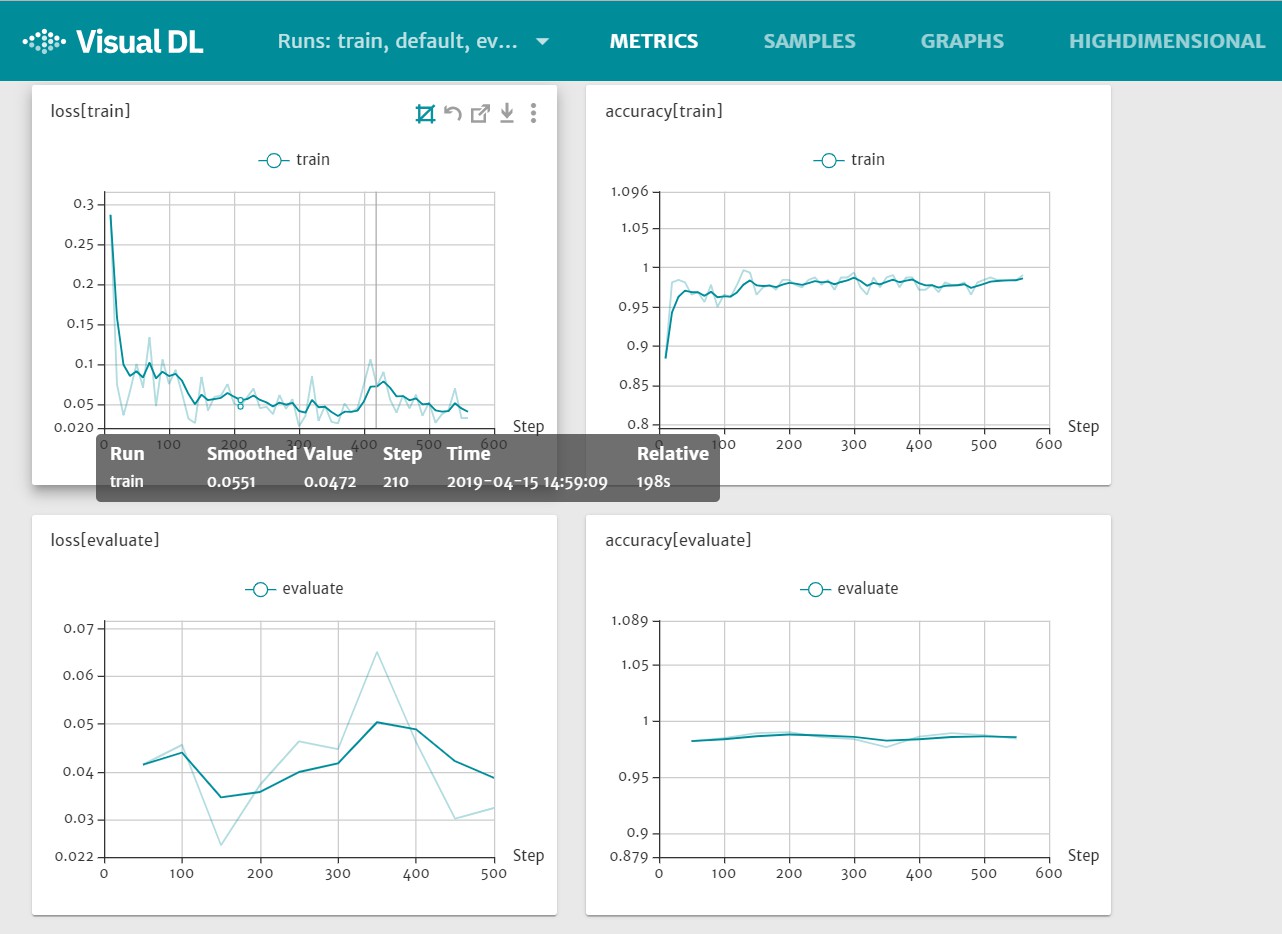
## 八、使用模型进行预测
当Finetune完成后,我们使用模型来进行预测,首先我们需要加载下训练好的参数
docs/transfer_learning_turtorial.md
→
docs/t
urtorial/t
ransfer_learning_turtorial.md
浏览文件 @
4a181c3a
...
...
@@ -22,40 +22,5 @@ http://ftp.cs.wisc.edu/machine-learning/shavlik-group/torrey.handbook09.pdf
PaddleHub提供了基于PaddlePaddle框架的Finetune API, 对常见的预训练模型迁移学习任务进行了抽象,帮助用户使用最少的代码快速完成迁移学习。
教程会包含CV领域的图像分类迁移,和NLP文本分类迁移两种任务。
### CV教程
以猫狗分类为例子,我们可以快速的使用一个通过ImageNet训练过的ResNet进行finetune
```
python
import
paddlehub
as
hub
import
paddle.fluid
as
fluid
if
__name__
==
"__main__"
:
resnet_module
=
hub
.
Module
(
name
=
"resnet50_imagenet"
)
input_dict
,
output_dict
,
program
=
resnet_module
.
context
(
sign_name
=
"feature_map"
,
trainable
=
True
)
dataset
=
hub
.
dataset
.
DogCat
()
data_reader
=
hub
.
ImageClassificationReader
(
image_width
=
224
,
image_height
=
224
,
dataset
=
dataset
)
with
fluid
.
program_guard
(
program
):
label
=
fluid
.
layers
.
data
(
name
=
"label"
,
dtype
=
"int64"
,
shape
=
[
1
])
img
=
input_dict
[
"img"
]
feature_map
=
output_dict
[
"feature_map"
]
# 运行配置
config
=
hub
.
RunConfig
(
use_cuda
=
True
,
num_epoch
=
10
,
batch_size
=
32
,
strategy
=
hub
.
DefaultFinetuneStrategy
())
feed_list
=
[
img
.
name
,
label
.
name
]
# 构造多分类模型任务
task
=
hub
.
create_img_classfiication_task
(
feature
=
feature_map
,
label
=
label
,
num_classes
=
dataset
.
num_labels
)
# finetune
hub
.
finetune_and_eval
(
task
,
feed_list
=
feed_list
,
data_reader
=
data_reader
,
config
=
config
)
```
*
[
CV教程
](
https://github.com/PaddlePaddle/PaddleHub/tree/develop/docs/turtorial/cv_finetune_turtorial.md
)
*
[
NLP教程
](
)
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录