Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleHub
提交
49c7a9f3
P
PaddleHub
项目概览
PaddlePaddle
/
PaddleHub
大约 2 年 前同步成功
通知
285
Star
12117
Fork
2091
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
200
列表
看板
标记
里程碑
合并请求
4
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleHub
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
200
Issue
200
列表
看板
标记
里程碑
合并请求
4
合并请求
4
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
49c7a9f3
编写于
9月 11, 2019
作者:
Z
zhangxuefei
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'develop' of
https://github.com/Steffy-zxf/PaddleHub
into develop
上级
b6373991
d297971e
变更
6
隐藏空白更改
内联
并排
Showing
6 changed file
with
57 addition
and
30 deletion
+57
-30
demo/README.md
demo/README.md
+12
-1
demo/elmo/README.md
demo/elmo/README.md
+3
-3
demo/multi-label-classification/README.md
demo/multi-label-classification/README.md
+3
-3
demo/qa_classification/README.md
demo/qa_classification/README.md
+3
-3
demo/sequence-labeling/README.md
demo/sequence-labeling/README.md
+7
-11
demo/text-classification/README.md
demo/text-classification/README.md
+29
-9
未找到文件。
demo/README.md
浏览文件 @
49c7a9f3
...
...
@@ -16,6 +16,10 @@
>* 多标签分类
>* 回归任务
>* 阅读理解
>* 检索式问答任务
## 图像分类
...
...
@@ -50,10 +54,17 @@
该样例展示了PaddleHub如何将BERT作为预训练模型在Toxic数据集上完成多标签分类的FineTune和预测。
## 回归任务
该样例展示了PaddleHub如何将BERT作为预训练模型在GLUE-STSB数据集上完成回归任务的FineTune和预测。
## 阅读理解
该样例展示了PaddleHub如何将BERT作为预训练模型在SQAD数据集上完成阅读理解的FineTune和预测。
## 检索式问答任务
该样例展示了PaddleHub如何将ERNIE和BERT作为预训练模型在NLPCC-DBQA等数据集上完成检索式问答任务的FineTune和预测。
**NOTE**
以上任务示例均是利用PaddleHub提供的数据集,若您想在自定义数据集上完成相应任务,请查看
[
PaddleHub适配自定义数据完成FineTune
](
https://github.com/PaddlePaddle/PaddleHub/wiki/PaddleHub%E9%80%82%E9%85%8D%E8%87%AA%E5%AE%9A%E4%B9%89%E6%95%B0%E6%8D%AE%E5%AE%8C%E6%88%90FineTune
)
demo/elmo/README.md
浏览文件 @
49c7a9f3
...
...
@@ -128,13 +128,13 @@ elmo_task.finetune_and_eval()
1.
`outputs["elmo_embed"]`
返回了ELMo模型预训练的word embedding。
2.
`hub.TextClassifierTask`
通过输入特征,label与迁移的类别数,可以生成适用于文本分类的迁移任务
`TextClassifierTask`
##
VisualDL
可视化
## 可视化
Finetune API训练过程中会自动对关键训练指标进行打点,启动程序后执行下面命令
```
bash
$
visualdl
--logdir
$CKPT_DIR
/vdllog
-t
${
HOST_IP
}
$
tensorboard
--logdir
$CKPT_DIR
/visualization
--host
${
HOST_IP
}
--port
${
PORT_NUM
}
```
其中${HOST_IP}为本机IP地址,
如本机IP地址为192.168.0.1,用浏览器打开192.168.0.1:8040,其中8040为端口号
,即可看到训练过程中指标的变化情况
其中${HOST_IP}为本机IP地址,
${PORT_NUM}为可用端口号,如本机IP地址为192.168.0.1,端口号8040,用浏览器打开192.168.0.1:8040
,即可看到训练过程中指标的变化情况
## 模型预测
...
...
demo/multi-label-classification/README.md
浏览文件 @
49c7a9f3
...
...
@@ -116,13 +116,13 @@ cls_task.finetune_and_eval()
2.
`feed_list`
中的inputs参数指名了ERNIE/BERT中的输入tensor的顺序,与MultiLabelClassifierTask返回的结果一致。
3.
`hub.MultiLabelClassifierTask`
通过输入特征,label与迁移的类别数,可以生成适用于多标签分类的迁移任务
`MultiLabelClassifierTask`
##
VisualDL
可视化
## 可视化
Finetune API训练过程中会自动对关键训练指标进行打点,启动程序后执行下面命令
```
bash
$
visualdl
--logdir
$CKPT_DIR
/vdllog
-t
${
HOST_IP
}
$
tensorboard
--logdir
$CKPT_DIR
/visualization
--host
${
HOST_IP
}
--port
${
PORT_NUM
}
```
其中${HOST_IP}为本机IP地址,
如本机IP地址为192.168.0.1,用浏览器打开192.168.0.1:8040,其中8040为端口号
,即可看到训练过程中指标的变化情况
其中${HOST_IP}为本机IP地址,
${PORT_NUM}为可用端口号,如本机IP地址为192.168.0.1,端口号8040,用浏览器打开192.168.0.1:8040
,即可看到训练过程中指标的变化情况
## 模型预测
...
...
demo/qa_classification/README.md
浏览文件 @
49c7a9f3
...
...
@@ -135,13 +135,13 @@ cls_task.finetune_and_eval()
2.
`feed_list`
中的inputs参数指名了ERNIE/BERT中的输入tensor的顺序,与ClassifyReader返回的结果一致。
3.
`hub.TextClassifierTask`
通过输入特征,label与迁移的类别数,可以生成适用于文本分类的迁移任务
`TextClassifierTask`
##
VisualDL
可视化
## 可视化
Finetune API训练过程中会自动对关键训练指标进行打点,启动程序后执行下面命令
```
bash
$
visualdl
--logdir
$CKPT_DIR
/vdllog
-t
${
HOST_IP
}
$
tensorboard
--logdir
$CKPT_DIR
/visualization
--host
${
HOST_IP
}
--port
${
PORT_NUM
}
```
其中${HOST_IP}为本机IP地址,
如本机IP地址为192.168.0.1,用浏览器打开192.168.0.1:8040,其中8040为端口号
,即可看到训练过程中指标的变化情况
其中${HOST_IP}为本机IP地址,
${PORT_NUM}为可用端口号,如本机IP地址为192.168.0.1,端口号8040,用浏览器打开192.168.0.1:8040
,即可看到训练过程中指标的变化情况
## 模型预测
...
...
demo/sequence-labeling/README.md
浏览文件 @
49c7a9f3
...
...
@@ -14,7 +14,9 @@
--weight_decay
: 控制正则项力度的参数,用于防止过拟合,默认为0.01
--warmup_proportion
: 学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0
--num_epoch
: Finetune迭代的轮数
--max_seq_len
: ERNIE/BERT模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数
--max_seq_len
: ERNIE/BERT模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数。
--use_data_parallel
: 是否使用并行计算,默认False。打开该功能依赖nccl库。
--use_pyreader
: 是否使用pyreader,默认False。
# 任务相关
--checkpoint_dir
: 模型保存路径,PaddleHub会自动保存验证集上表现最好的模型
...
...
@@ -38,11 +40,6 @@ PaddleHub还提供BERT模型可供选择, 所有模型对应的加载示例如
模型名 | PaddleHub Module
---------------------------------- | :------:
ERNIE, Chinese |
`hub.Module(name='ernie')`
BERT-Base, Uncased |
`hub.Module(name='bert_uncased_L-12_H-768_A-12')`
BERT-Large, Uncased |
`hub.Module(name='bert_uncased_L-24_H-1024_A-16')`
BERT-Base, Cased |
`hub.Module(name='bert_cased_L-12_H-768_A-12')`
BERT-Large, Cased |
`hub.Module(name='bert_cased_L-24_H-1024_A-16')`
BERT-Base, Multilingual Cased |
`hub.Module(nane='bert_multi_cased_L-12_H-768_A-12')`
BERT-Base, Chinese |
`hub.Module(name='bert_chinese_L-12_H-768_A-12')`
...
...
@@ -132,21 +129,20 @@ seq_label_task.finetune_and_eval()
2.
`feed_list`
中的inputs参数指名了ERNIE/BERT中的输入tensor的顺序,与SequenceLabelReader返回的结果一致。
3.
`hub.SequenceLabelTask`
通过输入特征,迁移的类别数,可以生成适用于序列标注的迁移任务
`SequenceLabelTask`
##
VisualDL
可视化
## 可视化
Finetune API训练过程中会自动对关键训练指标进行打点,启动程序后执行下面命令
```
bash
$
visualdl
--logdir
$CKPT_DIR
/vdllog
-t
${
HOST_IP
}
$
tensorboard
--logdir
$CKPT_DIR
/visualization
--host
${
HOST_IP
}
--port
${
PORT_NUM
}
```
其中${HOST_IP}为本机IP地址,如本机IP地址为192.168.0.1,用浏览器打开192.168.0.1:8040,其中8040为端口号,即可看到训练过程中指标的变化情况
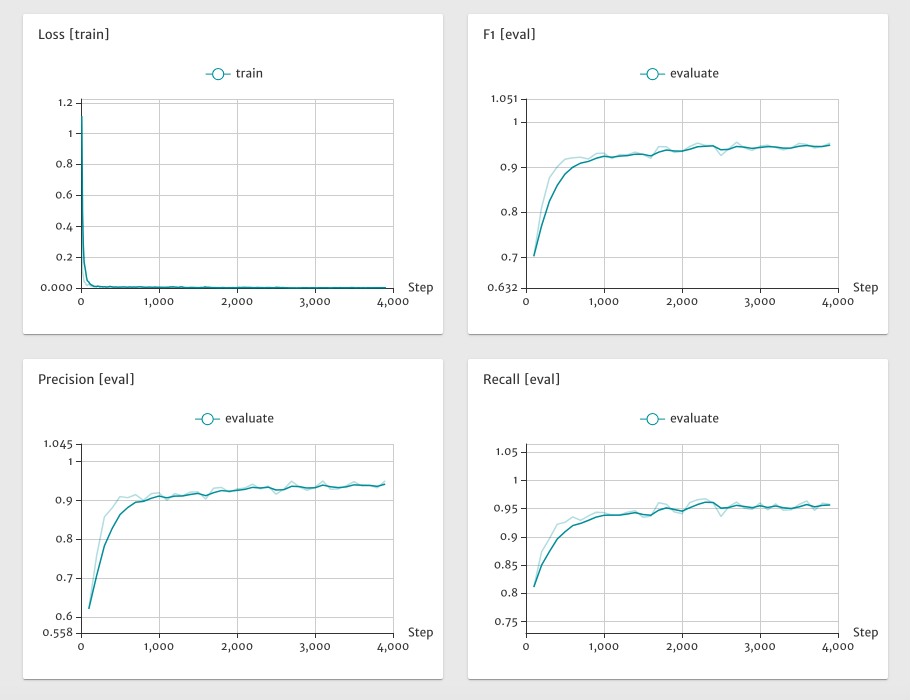
其中${HOST_IP}为本机IP地址,${PORT_NUM}为可用端口号,如本机IP地址为192.168.0.1,端口号8040,用浏览器打开192.168.0.1:8040,即可看到训练过程中指标的变化情况
## 模型预测
通过Finetune完成模型训练后,在对应的ckpt目录下,会自动保存验证集上效果最好的模型。
配置脚本参数
```
CKPT_DIR="
.ckpt_sequence_label/best_model
"
CKPT_DIR="
ckpt_sequence_label/
"
python predict.py --checkpoint_dir $CKPT_DIR --max_seq_len 128
```
其中CKPT_DIR为Finetune API保存最佳模型的路径, max_seq_len是ERNIE模型的最大序列长度,
*请与训练时配置的参数保持一致*
...
...
demo/text-classification/README.md
浏览文件 @
49c7a9f3
...
...
@@ -4,11 +4,20 @@
其中分类任务可以分为两大类:
*
**单句分类**
-
中文情感分析任务 ChnSentiCorp
-
ChnSentiCorp
-
GLUE-Cola
-
GLUE-SST2
*
**句对分类**
-
语义相似度 LCQMC
-
检索式问答任务 NLPCC-DBQA
-
LCQMC
-
NLPCC-DBQA
-
GLUE-MNLI
-
GLUE-QQP
-
GLUE-QNLI
-
GLUE-STS-B
-
GLUE-MRPC
-
GLUE-RTE
-
XNLI
## 如何开始Finetune
...
...
@@ -24,10 +33,13 @@
--warmup_proportion
: 学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0
--num_epoch
: Finetune迭代的轮数
--max_seq_len
: ERNIE/BERT模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数
--use_data_parallel
: 是否使用并行计算,默认False。打开该功能依赖nccl库。
--use_pyreader
: 是否使用pyreader,默认False。
--use_taskid
: 是否使用taskid,taskid是ERNIE 2.0特有的,use_taskid
=
True表示使用ERNIE 2.0;如果想使用ERNIE 1.0 或者BERT等module,use_taskid应该设置为False。
# 任务相关
--checkpoint_dir
: 模型保存路径,PaddleHub会自动保存验证集上表现最好的模型
--dataset
: 有
三个参数可选,分别代表3个不同的分类任务
;
分别是 chnsenticorp, lcqmc, nlpcc_dbqa
--dataset
: 有
以下数据集可选: chnsenticorp, lcqmc, nlpcc_dbqa, GLUE, XNLI
```
## 代码步骤
...
...
@@ -48,6 +60,8 @@ PaddleHub还提供BERT模型可供选择, 所有模型对应的加载示例如
模型名 | PaddleHub Module
---------------------------------- | :------:
ERNIE, Chinese |
`hub.Module(name='ernie')`
ERNIE 2.0 Base, English |
`hub.Module(name='ernie_v2_eng_base')`
ERNIE 2.0 Large, English |
`hub.Module(name='ernie_v2_eng_large')`
BERT-Base, Uncased |
`hub.Module(name='bert_uncased_L-12_H-768_A-12')`
BERT-Large, Uncased |
`hub.Module(name='bert_uncased_L-24_H-1024_A-16')`
BERT-Base, Cased |
`hub.Module(name='bert_cased_L-12_H-768_A-12')`
...
...
@@ -67,7 +81,9 @@ dataset = hub.dataset.ChnSentiCorp()
reader
=
hub
.
reader
.
ClassifyReader
(
dataset
=
dataset
,
vocab_path
=
module
.
get_vocab_path
(),
max_seq_len
=
128
)
max_seq_len
=
128
,
use_task_id
=
False
)
metrics_choices
=
[
"acc"
]
```
其中数据集的准备代码可以参考
[
chnsenticorp.py
](
https://github.com/PaddlePaddle/PaddleHub/blob/develop/paddlehub/dataset/chnsenticorp.py
)
...
...
@@ -78,10 +94,14 @@ reader = hub.reader.ClassifyReader(
`max_seq_len`
需要与Step1中context接口传入的序列长度保持一致
`use_task_id`
表示是否使用ERNIR 2.0 module
ClassifyReader中的
`data_generator`
会自动按照模型对应词表对数据进行切词,以迭代器的方式返回ERNIE/BERT所需要的Tensor格式,包括
`input_ids`
,
`position_ids`
,
`segment_id`
与序列对应的mask
`input_mask`
.
**NOTE**
: Reader返回tensor的顺序是固定的,默认按照input_ids, position_ids, segment_id, input_mask这一顺序返回。
同时,利用Accuracy作为评价指标。
### Step3:选择优化策略和运行配置
```
python
...
...
@@ -142,20 +162,20 @@ cls_task.finetune_and_eval()
2.
`feed_list`
中的inputs参数指名了ERNIE/BERT中的输入tensor的顺序,与ClassifyReader返回的结果一致。
3.
`hub.TextClassifierTask`
通过输入特征,label与迁移的类别数,可以生成适用于文本分类的迁移任务
`TextClassifierTask`
##
VisualDL
可视化
## 可视化
Finetune API训练过程中会自动对关键训练指标进行打点,启动程序后执行下面命令
```
bash
$
visualdl
--logdir
$CKPT_DIR
/vdllog
-t
${
HOST_IP
}
$
tensorboard
--logdir
$CKPT_DIR
/visualization
--host
${
HOST_IP
}
--port
${
PORT_NUM
}
```
其中${HOST_IP}为本机IP地址,
如本机IP地址为192.168.0.1,用浏览器打开192.168.0.1:8040,其中8040为端口号
,即可看到训练过程中指标的变化情况
其中${HOST_IP}为本机IP地址,
${PORT_NUM}为可用端口号,如本机IP地址为192.168.0.1,端口号8040,用浏览器打开192.168.0.1:8040
,即可看到训练过程中指标的变化情况
## 模型预测
通过Finetune完成模型训练后,在对应的ckpt目录下,会自动保存验证集上效果最好的模型。
配置脚本参数
```
CKPT_DIR="
.ckpt_chnsentiment/best_model
"
CKPT_DIR="
ckpt_chnsentiment/
"
python predict.py --checkpoint_dir $CKPT_DIR --max_seq_len 128
```
其中CKPT_DIR为Finetune API保存最佳模型的路径, max_seq_len是ERNIE模型的最大序列长度,
*请与训练时配置的参数保持一致*
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录