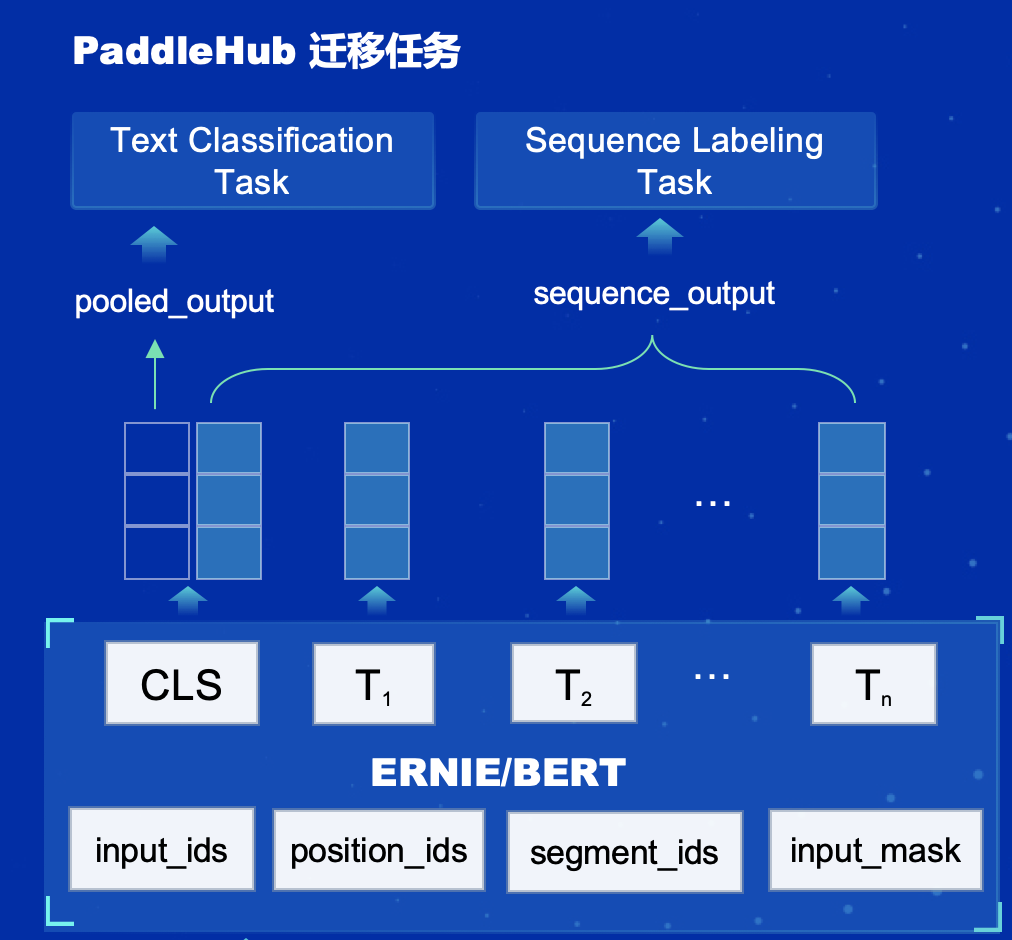
ERNIE是百度开放的基于Transformer知识增强的语义表示模型(Enhanced Representation from kNowledge IntEgration)ERNIE预训练模型结合Fine-tuning,可以在中文情感分析任务上可以得到非常不错的效果。更多的介绍可以参考[ERNIE](https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE)
前三个输入与BERT模型的论文输入对应,第四个输入为padding所需的标识信息。更多细节信息可参考论文[BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805)
{kind=link}