update serving demo
Showing
{kind=link}

28.5 KB
demo/serving/serving/README.md
0 → 100644
文件已移动
文件已移动
{kind=link}
{kind=link}
{kind=link}
{kind=link}
demo/serving/serving/img/man.png
0 → 100644
{kind=link}

88.0 KB
{kind=link}
39.6 KB
{kind=link}
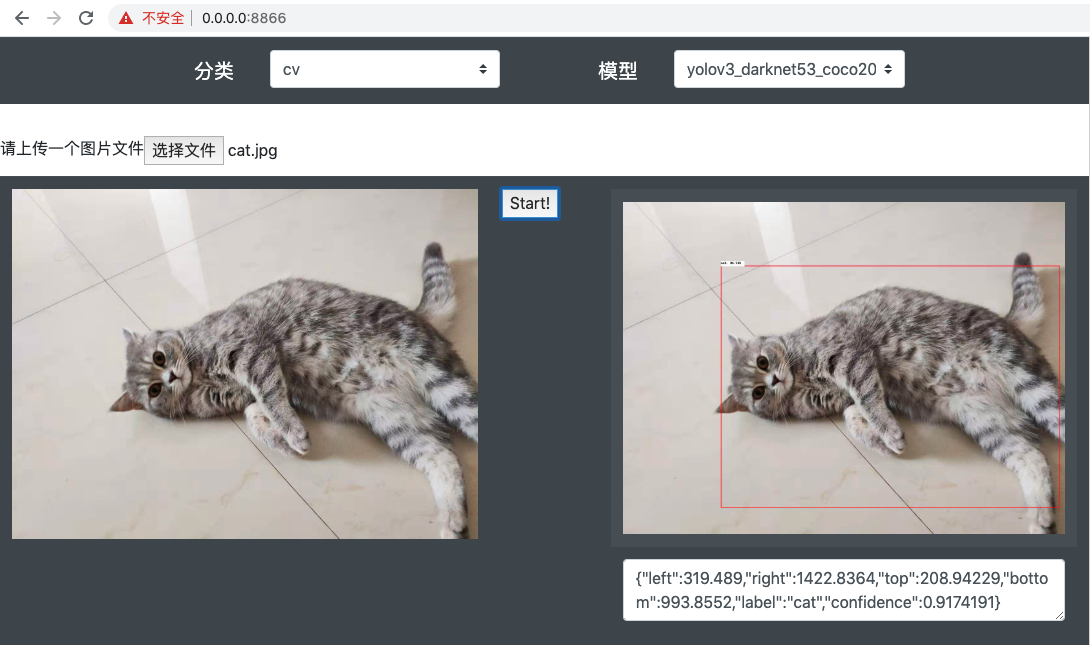
366.7 KB
{kind=link}
文件已移动
文件已移动
文件已移动
{kind=link}

125.2 KB
{kind=link}

58.9 KB
文件已移动
文件已移动
{kind=link}

304.2 KB