Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleHub
提交
04355438
P
PaddleHub
项目概览
PaddlePaddle
/
PaddleHub
大约 2 年 前同步成功
通知
285
Star
12117
Fork
2091
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
200
列表
看板
标记
里程碑
合并请求
4
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleHub
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
200
Issue
200
列表
看板
标记
里程碑
合并请求
4
合并请求
4
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
04355438
编写于
4月 18, 2019
作者:
W
wuzewu
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update cv turtorial, add predict code
上级
49e664c4
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
84 addition
and
23 deletion
+84
-23
docs/turtorial/cv_finetune_turtorial.md
docs/turtorial/cv_finetune_turtorial.md
+84
-23
未找到文件。
docs/turtorial/cv_finetune_turtorial.md
浏览文件 @
04355438
...
@@ -47,14 +47,20 @@ import paddlehub as hub
...
@@ -47,14 +47,20 @@ import paddlehub as hub
import
paddle.fluid
as
fluid
import
paddle.fluid
as
fluid
```
```
接下来我们要在PaddleHub中选择合适的预训练模型来Finetune,由于猫狗分类是一个图像分类任务,因此我们使用resnet50作为预训练模型(PaddleHub提供了丰富的预训练模型,我们建议您尝试不同的预训练模型来获得更好的性能)
接下来我们要在PaddleHub中选择合适的预训练模型来Finetune,由于猫狗分类是一个图像分类任务,因此我们使用
经典的
resnet50作为预训练模型(PaddleHub提供了丰富的预训练模型,我们建议您尝试不同的预训练模型来获得更好的性能)
```
python
```
python
cv_classifer_module
=
hub
.
Module
(
name
=
"resnet_v2_50_imagenet"
)
module_map
=
{
# cv_classifer_module = hub.Module(name = "resnet_v2_101_imagenet")
"resnet50"
:
"resnet_v2_50_imagenet"
,
# cv_classifer_module = hub.Module(name = "resnet_v2_152_imagenet")
"resnet101"
:
"resnet_v2_101_imagenet"
,
# cv_classifer_module = hub.Module(name = "nasnet_imagenet")
"resnet152"
:
"resnet_v2_152_imagenet"
,
# cv_classifer_module = hub.Module(name = "mobilenet_v2_imagenet")
"mobilenet"
:
"mobilenet_v2_imagenet"
,
"nasnet"
:
"nasnet_imagenet"
,
"pnasnet"
:
"pnasnet_imagenet"
}
module_name
=
module_map
[
"resnet50"
]
cv_classifer_module
=
hub
.
Module
(
name
=
module_name
)
```
```
## 三、数据准备
## 三、数据准备
...
@@ -62,15 +68,15 @@ cv_classifer_module = hub.Module(name = "resnet_v2_50_imagenet")
...
@@ -62,15 +68,15 @@ cv_classifer_module = hub.Module(name = "resnet_v2_50_imagenet")
接着需要加载图片数据集。我们需要自己切分数据集,将数据集且分为训练集、验证集和测试集。
接着需要加载图片数据集。我们需要自己切分数据集,将数据集且分为训练集、验证集和测试集。
同时使用三个文本文件来记录对应的图片路径和标签
同时使用三个文本文件来记录对应的图片路径和标签
```
├─data: 数据目录
├─data: 数据目录
├─train_list.txt:训练集数据列表
├─train_list.txt:训练集数据列表
├─test_list.txt:测试集数据列表
├─test_list.txt:测试集数据列表
├─validate_list:验证集数据列表
├─validate_list:验证集数据列表
└─……
└─……
```
每个文件的格式如下
每个文件的格式如下
```
text
```
图片1路径 图片1标签
图片1路径 图片1标签
图片2路径 图片2标签
图片2路径 图片2标签
……
……
...
@@ -80,7 +86,7 @@ cv_classifer_module = hub.Module(name = "resnet_v2_50_imagenet")
...
@@ -80,7 +86,7 @@ cv_classifer_module = hub.Module(name = "resnet_v2_50_imagenet")
```
python
```
python
# 使用本地数据集
# 使用本地数据集
class
mydataset
(
paddle
hub
.
ImageClassificationDataset
):
class
mydataset
(
hub
.
ImageClassificationDataset
):
self
.
base_path
=
"data"
self
.
base_path
=
"data"
self
.
train_list_file
=
"train_list.txt"
self
.
train_list_file
=
"train_list.txt"
self
.
test_list_file
=
"test_list.txt"
self
.
test_list_file
=
"test_list.txt"
...
@@ -94,7 +100,7 @@ dataset = mydataset()
...
@@ -94,7 +100,7 @@ dataset = mydataset()
```
python
```
python
# 直接用PaddleHub提供的数据集
# 直接用PaddleHub提供的数据集
dataset
=
paddlehub
.
dataset
.
dogc
at
()
dataset
=
hub
.
dataset
.
DogC
at
()
```
```
接着生成一个图像分类的reader,reader负责将dataset的数据进行预处理,接着以特定格式组织并输入给模型进行训练。
接着生成一个图像分类的reader,reader负责将dataset的数据进行预处理,接着以特定格式组织并输入给模型进行训练。
...
@@ -123,13 +129,13 @@ data_reader = hub.reader.ImageClassificationReader(
...
@@ -123,13 +129,13 @@ data_reader = hub.reader.ImageClassificationReader(
```
python
```
python
input_dict
,
output_dict
,
program
=
cv_classifer_module
.
context
(
trainable
=
True
)
input_dict
,
output_dict
,
program
=
cv_classifer_module
.
context
(
trainable
=
True
)
with
fluid
.
program_guard
(
program
):
img
=
input_dict
[
"image"
]
label
=
fluid
.
layers
.
data
(
name
=
"label"
,
dtype
=
"int64"
,
shape
=
[
1
])
feature_map
=
output_dict
[
"feature_map"
]
img
=
input_dict
[
"image"
]
feature_map
=
output_dict
[
"feature_map"
]
task
=
hub
.
create_img_cls_task
(
fe
ed_list
=
[
img
.
name
,
label
.
name
]
fe
ature
=
feature_map
,
num_classes
=
dataset
.
num_labels
)
task
=
hub
.
create_img_classification_task
(
feature
=
feature_map
,
label
=
label
,
num_classes
=
dataset
.
num_labels
)
feed_list
=
[
img
.
name
,
task
.
variable
(
"label"
).
name
]
```
```
## 五、选择运行时配置
## 五、选择运行时配置
...
@@ -146,7 +152,7 @@ with fluid.program_guard(program):
...
@@ -146,7 +152,7 @@ with fluid.program_guard(program):
`checkpoint_dir`
:将训练的参数和数据保存到cv_finetune_turtorial_demo目录中
`checkpoint_dir`
:将训练的参数和数据保存到cv_finetune_turtorial_demo目录中
更多运行配置,请查看
[
RunConfig
](
https://github.com/PaddlePaddle/PaddleHub/tree/develop/docs/API.md
)
更多运行配置,请查看
[
RunConfig
](
https://github.com/PaddlePaddle/PaddleHub/tree/develop/docs/API
/RunConfig
.md
)
```
python
```
python
config
=
hub
.
RunConfig
(
config
=
hub
.
RunConfig
(
...
@@ -170,14 +176,69 @@ hub.finetune_and_eval(
...
@@ -170,14 +176,69 @@ hub.finetune_and_eval(
训练过程中的性能数据会被记录到本地,我们可以通过visualdl来可视化这些数据
训练过程中的性能数据会被记录到本地,我们可以通过visualdl来可视化这些数据
我们在shell中输入以下命令来启动visualdl
我们在shell中输入以下命令来启动visualdl
,其中
`${HOST_IP}`
为本机IP,需要用户自行指定
```
shell
```
shell
$
visualdl
--logdir
./cv_finetune_turtorial_demo
--host
${
HOST_IP
}
$
visualdl
--logdir
./cv_finetune_turtorial_demo
--host
${
HOST_IP
}
--port
8989
```
```
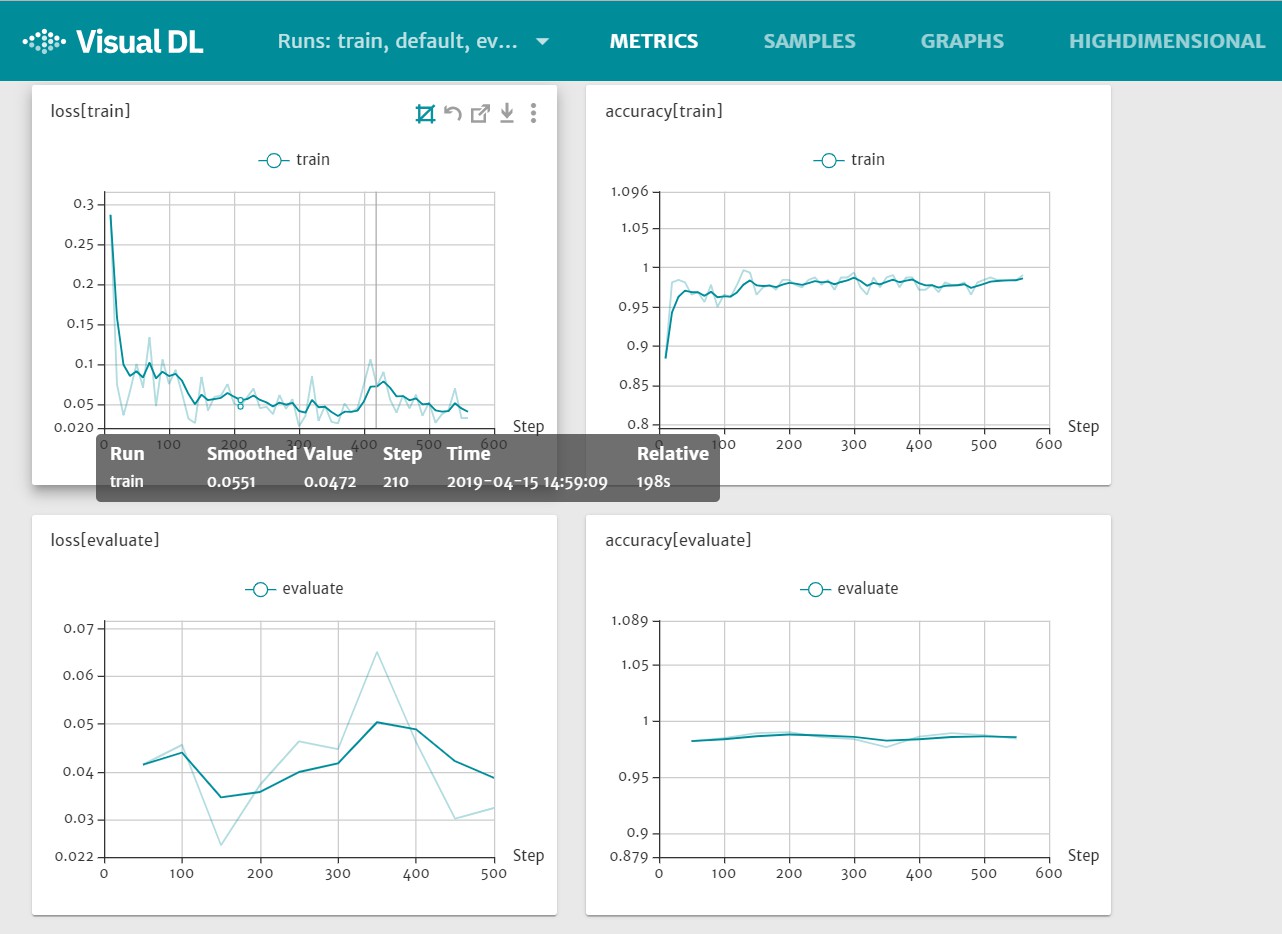
启动服务后,我们使用浏览器访问
指定的url
,可以看到训练以及预测的loss曲线和accuracy曲线
启动服务后,我们使用浏览器访问
`${HOST_IP}:8989`
,可以看到训练以及预测的loss曲线和accuracy曲线

## 八、使用模型进行预测
## 八、使用模型进行预测
当Finetune完成后,我们使用模型来进行预测,首先我们需要加载下训练好的参数
当Finetune完成后,我们使用模型来进行预测,整个预测流程大致可以分为以下几步:
1.
构建网络
2.
生成预测数据的Reader
3.
切换到预测的Program
4.
加载预训练好的参数
5.
运行Program进行预测
`注意`
:预测所用的测试图片请自行准备
完整代码如下:
```
python
import
os
import
numpy
as
np
def
predict
():
# Step 1: build Program
input_dict
,
output_dict
,
program
=
cv_classifer_module
.
context
(
trainable
=
True
)
img
=
input_dict
[
"image"
]
feature_map
=
output_dict
[
"feature_map"
]
task
=
hub
.
create_img_cls_task
(
feature
=
feature_map
,
num_classes
=
dataset
.
num_labels
)
feed_list
=
[
img
.
name
]
# Step 2: create data reader
data
=
[
"test_img_dog.jpg"
,
"test_img_cat.jpg"
]
data_reader
=
hub
.
reader
.
ImageClassificationReader
(
image_width
=
cv_classifer_module
.
get_expected_image_width
(),
image_height
=
cv_classifer_module
.
get_expected_image_height
(),
images_mean
=
cv_classifer_module
.
get_pretrained_images_mean
(),
images_std
=
cv_classifer_module
.
get_pretrained_images_std
(),
dataset
=
None
)
predict_reader
=
data_reader
.
data_generator
(
phase
=
"predict"
,
batch_size
=
1
,
data
=
data
)
# Step 3: switch to inference program
with
fluid
.
program_guard
(
task
.
inference_program
()):
# Step 4: load pretrained parameters
place
=
fluid
.
CPUPlace
()
exe
=
fluid
.
Executor
(
place
)
pretrained_model_dir
=
os
.
path
.
join
(
"cv_finetune_turtorial_demo"
,
"best_model"
)
fluid
.
io
.
load_persistables
(
exe
,
pretrained_model_dir
)
feeder
=
fluid
.
DataFeeder
(
feed_list
=
feed_list
,
place
=
place
)
# Step 5: predict
for
index
,
batch
in
enumerate
(
predict_reader
()):
result
,
=
exe
.
run
(
feed
=
feeder
.
feed
(
batch
),
fetch_list
=
[
task
.
variable
(
'probs'
)])
predict_result
=
np
.
argsort
(
result
[
0
])[::
-
1
][
0
]
print
(
"input %i is %s, and the predict result is %s"
%
(
index
+
1
,
data
[
index
],
predict_result
))
predict
()
```
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录