Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleGAN
提交
eebf94d9
P
PaddleGAN
项目概览
PaddlePaddle
/
PaddleGAN
大约 2 年 前同步成功
通知
100
Star
7254
Fork
1210
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
4
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleGAN
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
4
Issue
4
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
eebf94d9
编写于
8月 19, 2022
作者:
B
Birdylx
提交者:
GitHub
8月 19, 2022
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
[TIPC] add tipc benchmark for msvsr (#672)
* add tipc benchmark for msvsr * update tipc readme img
上级
91dcc906
变更
12
隐藏空白更改
内联
并排
Showing
12 changed file
with
211 addition
and
66 deletion
+211
-66
ppgan/engine/trainer.py
ppgan/engine/trainer.py
+24
-1
ppgan/models/msvsr_model.py
ppgan/models/msvsr_model.py
+43
-0
ppgan/utils/options.py
ppgan/utils/options.py
+23
-11
ppgan/utils/setup.py
ppgan/utils/setup.py
+7
-3
test_tipc/README.md
test_tipc/README.md
+3
-4
test_tipc/benchmark_train.sh
test_tipc/benchmark_train.sh
+9
-8
test_tipc/configs/msvsr/train_amp_infer_python.txt
test_tipc/configs/msvsr/train_amp_infer_python.txt
+53
-0
test_tipc/configs/msvsr/train_infer_python.txt
test_tipc/configs/msvsr/train_infer_python.txt
+10
-4
test_tipc/docs/benchmark_train.md
test_tipc/docs/benchmark_train.md
+8
-8
test_tipc/docs/test.png
test_tipc/docs/test.png
+0
-0
test_tipc/prepare.sh
test_tipc/prepare.sh
+6
-1
test_tipc/test_train_inference_python.sh
test_tipc/test_train_inference_python.sh
+25
-26
未找到文件。
ppgan/engine/trainer.py
浏览文件 @
eebf94d9
...
@@ -32,6 +32,7 @@ from ..utils.profiler import add_profiler_step
...
@@ -32,6 +32,7 @@ from ..utils.profiler import add_profiler_step
class
IterLoader
:
class
IterLoader
:
def
__init__
(
self
,
dataloader
):
def
__init__
(
self
,
dataloader
):
self
.
_dataloader
=
dataloader
self
.
_dataloader
=
dataloader
self
.
iter_loader
=
iter
(
self
.
_dataloader
)
self
.
iter_loader
=
iter
(
self
.
_dataloader
)
...
@@ -79,6 +80,7 @@ class Trainer:
...
@@ -79,6 +80,7 @@ class Trainer:
# | ||
# | ||
# save checkpoint (model.nets) \/
# save checkpoint (model.nets) \/
"""
"""
def
__init__
(
self
,
cfg
):
def
__init__
(
self
,
cfg
):
# base config
# base config
self
.
logger
=
logging
.
getLogger
(
__name__
)
self
.
logger
=
logging
.
getLogger
(
__name__
)
...
@@ -181,6 +183,22 @@ class Trainer:
...
@@ -181,6 +183,22 @@ class Trainer:
iter_loader
=
IterLoader
(
self
.
train_dataloader
)
iter_loader
=
IterLoader
(
self
.
train_dataloader
)
# use amp
if
self
.
cfg
.
amp
:
self
.
logger
.
info
(
'use AMP to train. AMP level = {}'
.
format
(
self
.
cfg
.
amp_level
))
assert
self
.
cfg
.
model
.
name
==
'MultiStageVSRModel'
,
"AMP only support msvsr model"
scaler
=
paddle
.
amp
.
GradScaler
(
init_loss_scaling
=
1024
)
# need to decorate model and optim if amp_level == 'O2'
if
self
.
cfg
.
amp_level
==
'O2'
:
# msvsr has only one generator and one optimizer
self
.
model
.
nets
[
'generator'
],
self
.
optimizers
[
'optim'
]
=
paddle
.
amp
.
decorate
(
models
=
self
.
model
.
nets
[
'generator'
],
optimizers
=
self
.
optimizers
[
'optim'
],
level
=
'O2'
,
save_dtype
=
'float32'
)
# set model.is_train = True
# set model.is_train = True
self
.
model
.
setup_train_mode
(
is_train
=
True
)
self
.
model
.
setup_train_mode
(
is_train
=
True
)
while
self
.
current_iter
<
(
self
.
total_iters
+
1
):
while
self
.
current_iter
<
(
self
.
total_iters
+
1
):
...
@@ -195,7 +213,12 @@ class Trainer:
...
@@ -195,7 +213,12 @@ class Trainer:
# unpack data from dataset and apply preprocessing
# unpack data from dataset and apply preprocessing
# data input should be dict
# data input should be dict
self
.
model
.
setup_input
(
data
)
self
.
model
.
setup_input
(
data
)
self
.
model
.
train_iter
(
self
.
optimizers
)
if
self
.
cfg
.
amp
:
self
.
model
.
train_iter_amp
(
self
.
optimizers
,
scaler
,
self
.
cfg
.
amp_level
)
# amp train
else
:
self
.
model
.
train_iter
(
self
.
optimizers
)
# norm train
batch_cost_averager
.
record
(
batch_cost_averager
.
record
(
time
.
time
()
-
step_start_time
,
time
.
time
()
-
step_start_time
,
...
...
ppgan/models/msvsr_model.py
浏览文件 @
eebf94d9
...
@@ -30,6 +30,7 @@ class MultiStageVSRModel(BaseSRModel):
...
@@ -30,6 +30,7 @@ class MultiStageVSRModel(BaseSRModel):
Paper:
Paper:
PP-MSVSR: Multi-Stage Video Super-Resolution, 2021
PP-MSVSR: Multi-Stage Video Super-Resolution, 2021
"""
"""
def
__init__
(
self
,
generator
,
fix_iter
,
pixel_criterion
=
None
):
def
__init__
(
self
,
generator
,
fix_iter
,
pixel_criterion
=
None
):
"""Initialize the PP-MSVSR class.
"""Initialize the PP-MSVSR class.
...
@@ -96,6 +97,48 @@ class MultiStageVSRModel(BaseSRModel):
...
@@ -96,6 +97,48 @@ class MultiStageVSRModel(BaseSRModel):
self
.
current_iter
+=
1
self
.
current_iter
+=
1
# amp train with brute force implementation, maybe decorator can simplify this
def
train_iter_amp
(
self
,
optims
=
None
,
scaler
=
None
,
amp_level
=
'O1'
):
optims
[
'optim'
].
clear_grad
()
if
self
.
fix_iter
:
if
self
.
current_iter
==
1
:
print
(
'Train MSVSR with fixed spynet for'
,
self
.
fix_iter
,
'iters.'
)
for
name
,
param
in
self
.
nets
[
'generator'
].
named_parameters
():
if
'spynet'
in
name
:
param
.
trainable
=
False
elif
self
.
current_iter
>=
self
.
fix_iter
+
1
and
self
.
flag
:
print
(
'Train all the parameters.'
)
for
name
,
param
in
self
.
nets
[
'generator'
].
named_parameters
():
param
.
trainable
=
True
if
'spynet'
in
name
:
param
.
optimize_attr
[
'learning_rate'
]
=
0.25
self
.
flag
=
False
for
net
in
self
.
nets
.
values
():
net
.
find_unused_parameters
=
False
# put loss computation in amp context
with
paddle
.
amp
.
auto_cast
(
enable
=
True
,
level
=
amp_level
):
output
=
self
.
nets
[
'generator'
](
self
.
lq
)
if
isinstance
(
output
,
(
list
,
tuple
)):
out_stage2
,
output
=
output
loss_pix_stage2
=
self
.
pixel_criterion
(
out_stage2
,
self
.
gt
)
self
.
losses
[
'loss_pix_stage2'
]
=
loss_pix_stage2
self
.
visual_items
[
'output'
]
=
output
[:,
0
,
:,
:,
:]
# pixel loss
loss_pix
=
self
.
pixel_criterion
(
output
,
self
.
gt
)
self
.
losses
[
'loss_pix'
]
=
loss_pix
self
.
loss
=
sum
(
_value
for
_key
,
_value
in
self
.
losses
.
items
()
if
'loss_pix'
in
_key
)
scaled_loss
=
scaler
.
scale
(
self
.
loss
)
self
.
losses
[
'loss'
]
=
scaled_loss
scaled_loss
.
backward
()
scaler
.
minimize
(
optims
[
'optim'
],
scaled_loss
)
self
.
current_iter
+=
1
def
test_iter
(
self
,
metrics
=
None
):
def
test_iter
(
self
,
metrics
=
None
):
self
.
gt
=
self
.
gt
.
cpu
()
self
.
gt
=
self
.
gt
.
cpu
()
self
.
nets
[
'generator'
].
eval
()
self
.
nets
[
'generator'
].
eval
()
...
...
ppgan/utils/options.py
浏览文件 @
eebf94d9
...
@@ -45,9 +45,9 @@ def parse_args():
...
@@ -45,9 +45,9 @@ def parse_args():
default
=
False
,
default
=
False
,
help
=
'skip validation during training'
)
help
=
'skip validation during training'
)
# config options
# config options
parser
.
add_argument
(
"-o"
,
parser
.
add_argument
(
"-o"
,
"--opt"
,
"--opt"
,
nargs
=
'+'
,
nargs
=
'+'
,
help
=
"set configuration options"
)
help
=
"set configuration options"
)
#for inference
#for inference
...
@@ -60,19 +60,31 @@ def parse_args():
...
@@ -60,19 +60,31 @@ def parse_args():
help
=
"path to reference images"
)
help
=
"path to reference images"
)
parser
.
add_argument
(
"--model_path"
,
default
=
None
,
help
=
"model for loading"
)
parser
.
add_argument
(
"--model_path"
,
default
=
None
,
help
=
"model for loading"
)
# for profiler
# for profiler
parser
.
add_argument
(
'-p'
,
parser
.
add_argument
(
'--profiler_options'
,
'-p'
,
type
=
str
,
'--profiler_options'
,
default
=
None
,
type
=
str
,
help
=
'The option of profiler, which should be in format
\"
key1=value1;key2=value2;key3=value3
\"
.'
default
=
None
,
help
=
'The option of profiler, which should be in format
\"
key1=value1;key2=value2;key3=value3
\"
.'
)
)
# fix random numbers by setting seed
# fix random numbers by setting seed
parser
.
add_argument
(
'--seed'
,
parser
.
add_argument
(
'--seed'
,
type
=
int
,
type
=
int
,
default
=
None
,
default
=
None
,
help
=
'fix random numbers by setting seed
\"
.'
help
=
'fix random numbers by setting seed
\"
.'
)
)
# add for amp training
parser
.
add_argument
(
'--amp'
,
action
=
'store_true'
,
default
=
False
,
help
=
'whether to enable amp training'
)
parser
.
add_argument
(
'--amp_level'
,
type
=
str
,
default
=
'O1'
,
choices
=
[
'O1'
,
'O2'
],
help
=
'level of amp training; O2 represent pure fp16'
)
args
=
parser
.
parse_args
()
args
=
parser
.
parse_args
()
return
args
return
args
ppgan/utils/setup.py
浏览文件 @
eebf94d9
...
@@ -19,6 +19,7 @@ import numpy as np
...
@@ -19,6 +19,7 @@ import numpy as np
import
random
import
random
from
.logger
import
setup_logger
from
.logger
import
setup_logger
def
setup
(
args
,
cfg
):
def
setup
(
args
,
cfg
):
if
args
.
evaluate_only
:
if
args
.
evaluate_only
:
cfg
.
is_train
=
False
cfg
.
is_train
=
False
...
@@ -44,10 +45,13 @@ def setup(args, cfg):
...
@@ -44,10 +45,13 @@ def setup(args, cfg):
paddle
.
set_device
(
'gpu'
)
paddle
.
set_device
(
'gpu'
)
else
:
else
:
paddle
.
set_device
(
'cpu'
)
paddle
.
set_device
(
'cpu'
)
if
args
.
seed
:
if
args
.
seed
:
paddle
.
seed
(
args
.
seed
)
paddle
.
seed
(
args
.
seed
)
random
.
seed
(
args
.
seed
)
random
.
seed
(
args
.
seed
)
np
.
random
.
seed
(
args
.
seed
)
np
.
random
.
seed
(
args
.
seed
)
paddle
.
framework
.
random
.
_manual_program_seed
(
args
.
seed
)
paddle
.
framework
.
random
.
_manual_program_seed
(
args
.
seed
)
# add amp and amp_level args into cfg
cfg
[
'amp'
]
=
args
.
amp
cfg
[
'amp_level'
]
=
args
.
amp_level
test_tipc/
readme
.md
→
test_tipc/
README
.md
浏览文件 @
eebf94d9
...
@@ -57,9 +57,8 @@ test_tipc/
...
@@ -57,9 +57,8 @@ test_tipc/
### 测试流程
### 测试流程
使用本工具,可以测试不同功能的支持情况,以及预测结果是否对齐,测试流程如下:
使用本工具,可以测试不同功能的支持情况,以及预测结果是否对齐,测试流程如下:
<div
align=
"center"
>
<img
src=
"docs/test.png"
width=
"800"
>
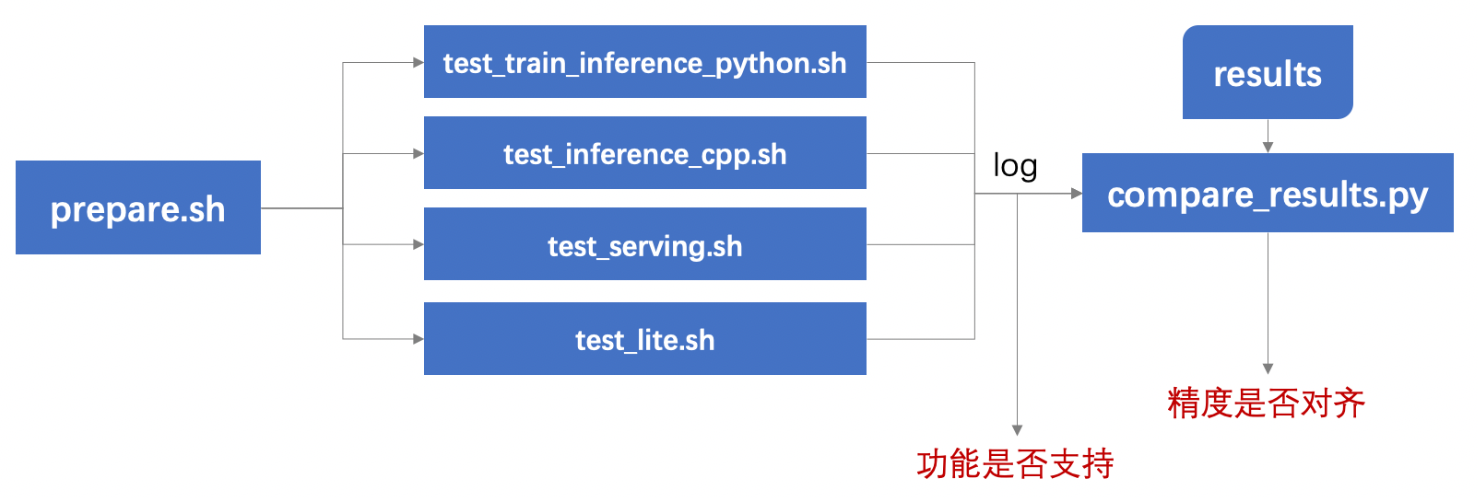
</div>
1.
运行prepare.sh准备测试所需数据和模型;
1.
运行prepare.sh准备测试所需数据和模型;
2.
运行要测试的功能对应的测试脚本
`test_*.sh`
,产出log,由log可以看到不同配置是否运行成功;
2.
运行要测试的功能对应的测试脚本
`test_*.sh`
,产出log,由log可以看到不同配置是否运行成功;
...
@@ -72,4 +71,4 @@ test_tipc/
...
@@ -72,4 +71,4 @@ test_tipc/
<a
name=
"more"
></a>
<a
name=
"more"
></a>
#### 更多教程
#### 更多教程
各功能测试中涉及混合精度、裁剪、量化等训练相关,及mkldnn、Tensorrt等多种预测相关参数配置,请点击下方相应链接了解更多细节和使用教程:
各功能测试中涉及混合精度、裁剪、量化等训练相关,及mkldnn、Tensorrt等多种预测相关参数配置,请点击下方相应链接了解更多细节和使用教程:
[
test_train_inference_python 使用
](
docs/test_train_inference_python.md
)
-
[
test_train_inference_python 使用
](
docs/test_train_inference_python.md
)
: 测试基于Python的模型训练、评估、推理等基本功能
test_tipc/benchmark_train.sh
浏览文件 @
eebf94d9
...
@@ -4,15 +4,15 @@ source test_tipc/common_func.sh
...
@@ -4,15 +4,15 @@ source test_tipc/common_func.sh
# set env
# set env
python
=
python
python
=
python
export
model_branch
=
`
git symbolic-ref HEAD 2>/dev/null |
cut
-d
"/"
-f
3
`
export
model_branch
=
`
git symbolic-ref HEAD 2>/dev/null |
cut
-d
"/"
-f
3
`
export
model_commit
=
$(
git log|head
-n1
|awk
'{print $2}'
)
export
model_commit
=
$(
git log|head
-n1
|awk
'{print $2}'
)
export
str_tmp
=
$(
echo
`
pip list|grep paddlepaddle-gpu|awk
-F
' '
'{print $2}'
`
)
export
str_tmp
=
$(
echo
`
pip list|grep paddlepaddle-gpu|awk
-F
' '
'{print $2}'
`
)
export
frame_version
=
${
str_tmp
%%.post*
}
export
frame_version
=
${
str_tmp
%%.post*
}
export
frame_commit
=
$(
echo
`
${
python
}
-c
"import paddle;print(paddle.version.commit)"
`
)
export
frame_commit
=
$(
echo
`
${
python
}
-c
"import paddle;print(paddle.version.commit)"
`
)
# run benchmark sh
# run benchmark sh
# Usage:
# Usage:
# bash run_benchmark_train.sh config.txt params
# bash run_benchmark_train.sh config.txt params
# or
# or
# bash run_benchmark_train.sh config.txt
# bash run_benchmark_train.sh config.txt
function
func_parser_params
(){
function
func_parser_params
(){
...
@@ -100,6 +100,7 @@ for _flag in ${flags_list[*]}; do
...
@@ -100,6 +100,7 @@ for _flag in ${flags_list[*]}; do
done
done
# set log_name
# set log_name
BENCHMARK_ROOT
=
./
# self-test only
repo_name
=
$(
get_repo_name
)
repo_name
=
$(
get_repo_name
)
SAVE_LOG
=
${
BENCHMARK_LOG_DIR
:-
$(
pwd
)
}
# */benchmark_log
SAVE_LOG
=
${
BENCHMARK_LOG_DIR
:-
$(
pwd
)
}
# */benchmark_log
mkdir
-p
"
${
SAVE_LOG
}
/benchmark_log/"
mkdir
-p
"
${
SAVE_LOG
}
/benchmark_log/"
...
@@ -149,11 +150,11 @@ else
...
@@ -149,11 +150,11 @@ else
fi
fi
IFS
=
"|"
IFS
=
"|"
for
batch_size
in
${
batch_size_list
[*]
}
;
do
for
batch_size
in
${
batch_size_list
[*]
}
;
do
for
precision
in
${
fp_items_list
[*]
}
;
do
for
precision
in
${
fp_items_list
[*]
}
;
do
for
device_num
in
${
device_num_list
[*]
}
;
do
for
device_num
in
${
device_num_list
[*]
}
;
do
# sed batchsize and precision
# sed batchsize and precision
#
func_sed_params "$FILENAME" "${line_precision}" "$precision"
func_sed_params
"
$FILENAME
"
"
${
line_precision
}
"
"
$precision
"
func_sed_params
"
$FILENAME
"
"
${
line_batchsize
}
"
"
$MODE
=
$batch_size
"
func_sed_params
"
$FILENAME
"
"
${
line_batchsize
}
"
"
$MODE
=
$batch_size
"
func_sed_params
"
$FILENAME
"
"
${
line_epoch
}
"
"
$MODE
=
$epoch
"
func_sed_params
"
$FILENAME
"
"
${
line_epoch
}
"
"
$MODE
=
$epoch
"
gpu_id
=
$(
set_gpu_id
$device_num
)
gpu_id
=
$(
set_gpu_id
$device_num
)
...
@@ -162,7 +163,7 @@ for batch_size in ${batch_size_list[*]}; do
...
@@ -162,7 +163,7 @@ for batch_size in ${batch_size_list[*]}; do
log_path
=
"
$SAVE_LOG
/profiling_log"
log_path
=
"
$SAVE_LOG
/profiling_log"
mkdir
-p
$log_path
mkdir
-p
$log_path
log_name
=
"
${
repo_name
}
_
${
model_name
}
_bs
${
batch_size
}
_
${
precision
}
_
${
run_mode
}
_
${
device_num
}
_profiling"
log_name
=
"
${
repo_name
}
_
${
model_name
}
_bs
${
batch_size
}
_
${
precision
}
_
${
run_mode
}
_
${
device_num
}
_profiling"
func_sed_params
"
$FILENAME
"
"
${
line_gpuid
}
"
"0"
# sed used gpu_id
func_sed_params
"
$FILENAME
"
"
${
line_gpuid
}
"
"0"
# sed used gpu_id
# set profile_option params
# set profile_option params
tmp
=
`
sed
-i
"
${
line_profile
}
s/.*/
${
profile_option
}
/"
"
${
FILENAME
}
"
`
tmp
=
`
sed
-i
"
${
line_profile
}
s/.*/
${
profile_option
}
/"
"
${
FILENAME
}
"
`
...
@@ -214,7 +215,7 @@ for batch_size in ${batch_size_list[*]}; do
...
@@ -214,7 +215,7 @@ for batch_size in ${batch_size_list[*]}; do
mkdir
-p
$speed_log_path
mkdir
-p
$speed_log_path
log_name
=
"
${
repo_name
}
_
${
model_name
}
_bs
${
batch_size
}
_
${
precision
}
_
${
run_mode
}
_
${
device_num
}
_log"
log_name
=
"
${
repo_name
}
_
${
model_name
}
_bs
${
batch_size
}
_
${
precision
}
_
${
run_mode
}
_
${
device_num
}
_log"
speed_log_name
=
"
${
repo_name
}
_
${
model_name
}
_bs
${
batch_size
}
_
${
precision
}
_
${
run_mode
}
_
${
device_num
}
_speed"
speed_log_name
=
"
${
repo_name
}
_
${
model_name
}
_bs
${
batch_size
}
_
${
precision
}
_
${
run_mode
}
_
${
device_num
}
_speed"
func_sed_params
"
$FILENAME
"
"
${
line_gpuid
}
"
"
$gpu_id
"
# sed used gpu_id
func_sed_params
"
$FILENAME
"
"
${
line_gpuid
}
"
"
$gpu_id
"
# sed used gpu_id
func_sed_params
"
$FILENAME
"
"
${
line_profile
}
"
"null"
# sed --profile_option as null
func_sed_params
"
$FILENAME
"
"
${
line_profile
}
"
"null"
# sed --profile_option as null
cmd
=
"bash test_tipc/test_train_inference_python.sh
${
FILENAME
}
benchmark_train >
${
log_path
}
/
${
log_name
}
2>&1 "
cmd
=
"bash test_tipc/test_train_inference_python.sh
${
FILENAME
}
benchmark_train >
${
log_path
}
/
${
log_name
}
2>&1 "
echo
$cmd
echo
$cmd
...
@@ -244,4 +245,4 @@ for batch_size in ${batch_size_list[*]}; do
...
@@ -244,4 +245,4 @@ for batch_size in ${batch_size_list[*]}; do
fi
fi
done
done
done
done
done
done
\ No newline at end of file
test_tipc/configs/msvsr/train_amp_infer_python.txt
0 → 100644
浏览文件 @
eebf94d9
===========================train_params===========================
model_name:msvsr
python:python3.7
gpu_list:0
##
auto_cast:null
total_iters:lite_train_lite_infer=10|lite_train_whole_infer=10|whole_train_whole_infer=200
output_dir:./output/
dataset.train.batch_size:lite_train_lite_infer=1|whole_train_whole_infer=1
pretrained_model:null
train_model_name:msvsr_reds*/*checkpoint.pdparams
train_infer_img_dir:./data/msvsr_reds/test
null:null
##
trainer:amp_train
amp_train:tools/main.py --amp --amp_level O1 -c configs/msvsr_reds.yaml --seed 123 -o dataset.train.num_workers=0 log_config.interval=1 snapshot_config.interval=5 dataset.train.dataset.num_frames=2
pact_train:null
fpgm_train:null
distill_train:null
null:null
null:null
##
===========================eval_params===========================
eval:null
null:null
##
===========================infer_params===========================
--output_dir:./output/
load:null
norm_export:tools/export_model.py -c configs/msvsr_reds.yaml --inputs_size="1,2,3,180,320" --model_name inference --load
quant_export:null
fpgm_export:null
distill_export:null
export1:null
export2:null
inference_dir:inference
train_model:./inference/msvsr/multistagevsrmodel_generator
infer_export:null
infer_quant:False
inference:tools/inference.py --model_type msvsr -c configs/msvsr_reds.yaml --seed 123 -o dataset.test.num_frames=2 --output_path test_tipc/output/
--device:cpu
null:null
null:null
null:null
null:null
null:null
--model_path:
null:null
null:null
--benchmark:True
null:null
===========================infer_benchmark_params==========================
random_infer_input:[{float32,[2,3,180,320]}]
test_tipc/configs/msvsr/train_infer_python.txt
浏览文件 @
eebf94d9
...
@@ -13,22 +13,22 @@ train_infer_img_dir:./data/msvsr_reds/test
...
@@ -13,22 +13,22 @@ train_infer_img_dir:./data/msvsr_reds/test
null:null
null:null
##
##
trainer:norm_train
trainer:norm_train
norm_train:tools/main.py -c configs/msvsr_reds.yaml --seed 123 -o
dataset.train.num_workers=0 log_config.interval=1 snapshot_config.interval=5 dataset.train.dataset.num_frames=2
norm_train:tools/main.py -c configs/msvsr_reds.yaml --seed 123 -o
log_config.interval=2 snapshot_config.interval=50 dataset.train.dataset.num_frames=15
pact_train:null
pact_train:null
fpgm_train:null
fpgm_train:null
distill_train:null
distill_train:null
null:null
null:null
null:null
null:null
##
##
===========================eval_params===========================
===========================eval_params===========================
eval:null
eval:null
null:null
null:null
##
##
===========================infer_params===========================
===========================infer_params===========================
--output_dir:./output/
--output_dir:./output/
load:null
load:null
norm_export:tools/export_model.py -c configs/msvsr_reds.yaml --inputs_size="1,2,3,180,320" --model_name inference --load
norm_export:tools/export_model.py -c configs/msvsr_reds.yaml --inputs_size="1,2,3,180,320" --model_name inference --load
quant_export:null
quant_export:null
fpgm_export:null
fpgm_export:null
distill_export:null
distill_export:null
export1:null
export1:null
...
@@ -49,5 +49,11 @@ null:null
...
@@ -49,5 +49,11 @@ null:null
null:null
null:null
--benchmark:True
--benchmark:True
null:null
null:null
===========================train_benchmark_params==========================
batch_size:4
fp_items:fp32
total_iters:60
--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
flags:null
===========================infer_benchmark_params==========================
===========================infer_benchmark_params==========================
random_infer_input:[{float32,[2,3,180,320]}]
random_infer_input:[{float32,[2,3,180,320]}]
test_tipc/docs/benchmark_train.md
浏览文件 @
eebf94d9
...
@@ -9,7 +9,7 @@
...
@@ -9,7 +9,7 @@
```
shell
```
shell
# 运行格式:bash test_tipc/prepare.sh train_benchmark.txt mode
# 运行格式:bash test_tipc/prepare.sh train_benchmark.txt mode
bash test_tipc/prepare.sh test_tipc/configs/
basicvsr/train_benchmark
.txt benchmark_train
bash test_tipc/prepare.sh test_tipc/configs/
msvsr/train_infer_python
.txt benchmark_train
```
```
## 1.2 功能测试
## 1.2 功能测试
...
@@ -17,13 +17,13 @@ bash test_tipc/prepare.sh test_tipc/configs/basicvsr/train_benchmark.txt benchma
...
@@ -17,13 +17,13 @@ bash test_tipc/prepare.sh test_tipc/configs/basicvsr/train_benchmark.txt benchma
```
shell
```
shell
# 运行格式:bash test_tipc/benchmark_train.sh train_benchmark.txt mode
# 运行格式:bash test_tipc/benchmark_train.sh train_benchmark.txt mode
bash test_tipc/benchmark_train.sh test_tipc/configs/
basic
vsr/train_infer_python.txt benchmark_train
bash test_tipc/benchmark_train.sh test_tipc/configs/
ms
vsr/train_infer_python.txt benchmark_train
```
```
`test_tipc/benchmark_train.sh`
支持根据传入的第三个参数实现只运行某一个训练配置,如下:
`test_tipc/benchmark_train.sh`
支持根据传入的第三个参数实现只运行某一个训练配置,如下:
```
shell
```
shell
# 运行格式:bash test_tipc/benchmark_train.sh train_benchmark.txt mode
# 运行格式:bash test_tipc/benchmark_train.sh train_benchmark.txt mode
bash test_tipc/benchmark_train.sh test_tipc/configs/
basic
vsr/train_infer_python.txt benchmark_train dynamic_bs4_fp32_DP_N1C1
bash test_tipc/benchmark_train.sh test_tipc/configs/
ms
vsr/train_infer_python.txt benchmark_train dynamic_bs4_fp32_DP_N1C1
```
```
dynamic_bs4_fp32_DP_N1C1为test_tipc/benchmark_train.sh传入的参数,格式如下:
dynamic_bs4_fp32_DP_N1C1为test_tipc/benchmark_train.sh传入的参数,格式如下:
`${modeltype}_${batch_size}_${fp_item}_${run_mode}_${device_num}`
`${modeltype}_${batch_size}_${fp_item}_${run_mode}_${device_num}`
...
@@ -42,11 +42,11 @@ dynamic_bs4_fp32_DP_N1C1为test_tipc/benchmark_train.sh传入的参数,格式
...
@@ -42,11 +42,11 @@ dynamic_bs4_fp32_DP_N1C1为test_tipc/benchmark_train.sh传入的参数,格式
```
```
train_log/
train_log/
├── index
├── index
│ ├── PaddleGAN_
basic
vsr_bs4_fp32_SingleP_DP_N1C1_speed
│ ├── PaddleGAN_
ms
vsr_bs4_fp32_SingleP_DP_N1C1_speed
│ └── PaddleGAN_
basic
vsr_bs4_fp32_SingleP_DP_N1C4_speed
│ └── PaddleGAN_
ms
vsr_bs4_fp32_SingleP_DP_N1C4_speed
├── profiling_log
├── profiling_log
│ └── PaddleGAN_
basic
vsr_bs4_fp32_SingleP_DP_N1C1_profiling
│ └── PaddleGAN_
ms
vsr_bs4_fp32_SingleP_DP_N1C1_profiling
└── train_log
└── train_log
├── PaddleGAN_
basic
vsr_bs4_fp32_SingleP_DP_N1C1_log
├── PaddleGAN_
ms
vsr_bs4_fp32_SingleP_DP_N1C1_log
└── PaddleGAN_
basic
vsr_bs4_fp32_MultiP_DP_N1C4_log
└── PaddleGAN_
ms
vsr_bs4_fp32_MultiP_DP_N1C4_log
```
```
test_tipc/docs/test.png
0 → 100644
浏览文件 @
eebf94d9
223.8 KB
test_tipc/prepare.sh
浏览文件 @
eebf94d9
...
@@ -172,5 +172,10 @@ elif [ ${MODE} = "whole_infer" ];then
...
@@ -172,5 +172,10 @@ elif [ ${MODE} = "whole_infer" ];then
mkdir
-p
./data/singan
mkdir
-p
./data/singan
mv
./data/SinGAN-official_images/Images/stone.png ./data/singan
mv
./data/SinGAN-official_images/Images/stone.png ./data/singan
fi
fi
elif
[
${
MODE
}
=
"benchmark_train"
]
;
then
if
[
${
model_name
}
=
"msvsr"
]
;
then
rm
-rf
./data/reds
*
wget
-nc
-P
./data/ https://paddlegan.bj.bcebos.com/datasets/reds_lite.tar
--no-check-certificate
cd
./data/
&&
tar
xf reds_lite.tar
&&
cd
../
fi
fi
fi
test_tipc/test_train_inference_python.sh
浏览文件 @
eebf94d9
...
@@ -48,11 +48,11 @@ norm_export=$(func_parser_value "${lines[29]}")
...
@@ -48,11 +48,11 @@ norm_export=$(func_parser_value "${lines[29]}")
inference_dir
=
$(
func_parser_value
"
${
lines
[35]
}
"
)
inference_dir
=
$(
func_parser_value
"
${
lines
[35]
}
"
)
# parser inference model
# parser inference model
infer_model_dir_list
=
$(
func_parser_value
"
${
lines
[36]
}
"
)
infer_model_dir_list
=
$(
func_parser_value
"
${
lines
[36]
}
"
)
infer_export_list
=
$(
func_parser_value
"
${
lines
[37]
}
"
)
infer_export_list
=
$(
func_parser_value
"
${
lines
[37]
}
"
)
infer_is_quant
=
$(
func_parser_value
"
${
lines
[38]
}
"
)
infer_is_quant
=
$(
func_parser_value
"
${
lines
[38]
}
"
)
# parser inference
# parser inference
inference_py
=
$(
func_parser_value
"
${
lines
[39]
}
"
)
inference_py
=
$(
func_parser_value
"
${
lines
[39]
}
"
)
use_gpu_key
=
$(
func_parser_key
"
${
lines
[40]
}
"
)
use_gpu_key
=
$(
func_parser_key
"
${
lines
[40]
}
"
)
use_gpu_list
=
$(
func_parser_value
"
${
lines
[40]
}
"
)
use_gpu_list
=
$(
func_parser_value
"
${
lines
[40]
}
"
)
...
@@ -85,7 +85,7 @@ function func_inference(){
...
@@ -85,7 +85,7 @@ function func_inference(){
_log_path
=
$4
_log_path
=
$4
_img_dir
=
$5
_img_dir
=
$5
_flag_quant
=
$6
_flag_quant
=
$6
# inference
# inference
for
use_gpu
in
${
use_gpu_list
[*]
}
;
do
for
use_gpu
in
${
use_gpu_list
[*]
}
;
do
if
[
${
use_gpu
}
=
"False"
]
||
[
${
use_gpu
}
=
"cpu"
]
;
then
if
[
${
use_gpu
}
=
"False"
]
||
[
${
use_gpu
}
=
"cpu"
]
;
then
for
use_mkldnn
in
${
use_mkldnn_list
[*]
}
;
do
for
use_mkldnn
in
${
use_mkldnn_list
[*]
}
;
do
...
@@ -96,7 +96,7 @@ function func_inference(){
...
@@ -96,7 +96,7 @@ function func_inference(){
for
batch_size
in
${
batch_size_list
[*]
}
;
do
for
batch_size
in
${
batch_size_list
[*]
}
;
do
for
precision
in
${
precision_list
[*]
}
;
do
for
precision
in
${
precision_list
[*]
}
;
do
set_precision
=
$(
func_set_params
"
${
precision_key
}
"
"
${
precision
}
"
)
set_precision
=
$(
func_set_params
"
${
precision_key
}
"
"
${
precision
}
"
)
_save_log_path
=
"
${
_log_path
}
/python_infer_cpu_usemkldnn_
${
use_mkldnn
}
_threads_
${
threads
}
_precision_
${
precision
}
_batchsize_
${
batch_size
}
.log"
_save_log_path
=
"
${
_log_path
}
/python_infer_cpu_usemkldnn_
${
use_mkldnn
}
_threads_
${
threads
}
_precision_
${
precision
}
_batchsize_
${
batch_size
}
.log"
set_infer_data
=
$(
func_set_params
"
${
image_dir_key
}
"
"
${
_img_dir
}
"
)
set_infer_data
=
$(
func_set_params
"
${
image_dir_key
}
"
"
${
_img_dir
}
"
)
set_benchmark
=
$(
func_set_params
"
${
benchmark_key
}
"
"
${
benchmark_value
}
"
)
set_benchmark
=
$(
func_set_params
"
${
benchmark_key
}
"
"
${
benchmark_value
}
"
)
...
@@ -118,7 +118,7 @@ function func_inference(){
...
@@ -118,7 +118,7 @@ function func_inference(){
for
precision
in
${
precision_list
[*]
}
;
do
for
precision
in
${
precision_list
[*]
}
;
do
if
[[
${
_flag_quant
}
=
"False"
]]
&&
[[
${
precision
}
=
~
"int8"
]]
;
then
if
[[
${
_flag_quant
}
=
"False"
]]
&&
[[
${
precision
}
=
~
"int8"
]]
;
then
continue
continue
fi
fi
if
[[
${
precision
}
=
~
"fp16"
||
${
precision
}
=
~
"int8"
]]
&&
[
${
use_trt
}
=
"False"
]
;
then
if
[[
${
precision
}
=
~
"fp16"
||
${
precision
}
=
~
"int8"
]]
&&
[
${
use_trt
}
=
"False"
]
;
then
continue
continue
fi
fi
...
@@ -139,7 +139,7 @@ function func_inference(){
...
@@ -139,7 +139,7 @@ function func_inference(){
last_status
=
${
PIPESTATUS
[0]
}
last_status
=
${
PIPESTATUS
[0]
}
eval
"cat
${
_save_log_path
}
"
eval
"cat
${
_save_log_path
}
"
status_check
$last_status
"
${
command
}
"
"
${
status_log
}
"
status_check
$last_status
"
${
command
}
"
"
${
status_log
}
"
done
done
done
done
done
done
...
@@ -169,7 +169,7 @@ if [ ${MODE} = "whole_infer" ]; then
...
@@ -169,7 +169,7 @@ if [ ${MODE} = "whole_infer" ]; then
set_export_weight
=
$(
func_set_params
"
${
export_weight
}
"
"
${
infer_model
}
"
)
set_export_weight
=
$(
func_set_params
"
${
export_weight
}
"
"
${
infer_model
}
"
)
set_save_infer_key
=
"
${
save_infer_key
}
${
save_infer_dir
}
"
set_save_infer_key
=
"
${
save_infer_key
}
${
save_infer_dir
}
"
export_cmd
=
"
${
python
}
${
infer_run_exports
[Count]
}
${
set_export_weight
}
${
set_save_infer_key
}
"
export_cmd
=
"
${
python
}
${
infer_run_exports
[Count]
}
${
set_export_weight
}
${
set_save_infer_key
}
"
echo
${
infer_run_exports
[Count]
}
echo
${
infer_run_exports
[Count]
}
echo
$export_cmd
echo
$export_cmd
eval
$export_cmd
eval
$export_cmd
status_export
=
$?
status_export
=
$?
...
@@ -207,17 +207,17 @@ else
...
@@ -207,17 +207,17 @@ else
IFS
=
"|"
IFS
=
"|"
env
=
" "
env
=
" "
fi
fi
for
autocast
in
${
autocast_list
[*]
}
;
do
for
autocast
in
${
autocast_list
[*]
}
;
do
if
[
${
autocast
}
=
"
amp
"
]
;
then
if
[
${
autocast
}
=
"
fp16
"
]
;
then
set_amp_config
=
"
Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
"
set_amp_config
=
"
--amp
"
else
else
set_amp_config
=
" "
set_amp_config
=
" "
fi
fi
for
trainer
in
${
trainer_list
[*]
}
;
do
for
trainer
in
${
trainer_list
[*]
}
;
do
flag_quant
=
False
flag_quant
=
False
run_train
=
${
norm_trainer
}
run_train
=
${
norm_trainer
}
run_export
=
${
norm_export
}
run_export
=
${
norm_export
}
if
[
${
run_train
}
=
"null"
]
;
then
if
[
${
run_train
}
=
"null"
]
;
then
continue
continue
fi
fi
...
@@ -239,11 +239,11 @@ else
...
@@ -239,11 +239,11 @@ else
fi
fi
set_save_model
=
$(
func_set_params
"
${
save_model_key
}
"
"
${
save_log
}
"
)
set_save_model
=
$(
func_set_params
"
${
save_model_key
}
"
"
${
save_log
}
"
)
if
[
${#
gpu
}
-le
2
]
;
then
# train with cpu or single gpu
if
[
${#
gpu
}
-le
2
]
;
then
# train with cpu or single gpu
cmd
=
"
${
python
}
${
run_train
}
${
set_use_gpu
}
${
set_save_model
}
${
set_train_params1
}
${
set_epoch
}
${
set_pretrain
}
${
set_
autocast
}
${
set_batchsize
}
${
set_amp_config
}
"
cmd
=
"
${
python
}
${
run_train
}
${
set_use_gpu
}
${
set_save_model
}
${
set_train_params1
}
${
set_epoch
}
${
set_pretrain
}
${
set_
batchsize
}
${
set_amp_config
}
"
elif
[
${#
ips
}
-le
26
]
;
then
# train with multi-gpu
elif
[
${#
ips
}
-le
26
]
;
then
# train with multi-gpu
cmd
=
"
${
python
}
-m paddle.distributed.launch --gpus=
${
gpu
}
${
run_train
}
${
set_use_gpu
}
${
set_save_model
}
${
set_train_params1
}
${
set_epoch
}
${
set_pretrain
}
${
set_
autocast
}
${
set_
batchsize
}
${
set_amp_config
}
"
cmd
=
"
${
python
}
-m paddle.distributed.launch --gpus=
${
gpu
}
${
run_train
}
${
set_use_gpu
}
${
set_save_model
}
${
set_train_params1
}
${
set_epoch
}
${
set_pretrain
}
${
set_batchsize
}
${
set_amp_config
}
"
else
# train with multi-machine
else
# train with multi-machine
cmd
=
"
${
python
}
-m paddle.distributed.launch --ips=
${
ips
}
--gpus=
${
gpu
}
${
run_train
}
${
set_use_gpu
}
${
set_save_model
}
${
set_train_params1
}
${
set_pretrain
}
${
set_epoch
}
${
set_
autocast
}
${
set_
batchsize
}
${
set_amp_config
}
"
cmd
=
"
${
python
}
-m paddle.distributed.launch --ips=
${
ips
}
--gpus=
${
gpu
}
${
run_train
}
${
set_use_gpu
}
${
set_save_model
}
${
set_train_params1
}
${
set_pretrain
}
${
set_epoch
}
${
set_batchsize
}
${
set_amp_config
}
"
fi
fi
# run train
# run train
eval
"unset CUDA_VISIBLE_DEVICES"
eval
"unset CUDA_VISIBLE_DEVICES"
...
@@ -253,17 +253,17 @@ else
...
@@ -253,17 +253,17 @@ else
status_check
$?
"
${
cmd
}
"
"
${
status_log
}
"
status_check
$?
"
${
cmd
}
"
"
${
status_log
}
"
set_eval_pretrain
=
$(
func_set_params
"
${
pretrain_model_key
}
"
"
${
save_log
}
/
${
train_model_name
}
"
)
set_eval_pretrain
=
$(
func_set_params
"
${
pretrain_model_key
}
"
"
${
save_log
}
/
${
train_model_name
}
"
)
# save norm trained models to set pretrain for pact training and fpgm training
# save norm trained models to set pretrain for pact training and fpgm training
# run eval
# run eval
if
[
${
eval_py
}
!=
"null"
]
;
then
if
[
${
eval_py
}
!=
"null"
]
;
then
set_eval_params1
=
$(
func_set_params
"
${
eval_key1
}
"
"
${
eval_value1
}
"
)
set_eval_params1
=
$(
func_set_params
"
${
eval_key1
}
"
"
${
eval_value1
}
"
)
eval_cmd
=
"
${
python
}
${
eval_py
}
${
set_eval_pretrain
}
${
set_use_gpu
}
${
set_eval_params1
}
"
eval_cmd
=
"
${
python
}
${
eval_py
}
${
set_eval_pretrain
}
${
set_use_gpu
}
${
set_eval_params1
}
"
eval
$eval_cmd
eval
$eval_cmd
status_check
$?
"
${
eval_cmd
}
"
"
${
status_log
}
"
status_check
$?
"
${
eval_cmd
}
"
"
${
status_log
}
"
fi
fi
# run export model
# run export model
if
[
${
run_export
}
!=
"null"
]
;
then
if
[
${
run_export
}
!=
"null"
]
;
then
# run export model
# run export model
save_infer_path
=
"
${
save_log
}
"
save_infer_path
=
"
${
save_log
}
"
set_export_weight
=
"
${
save_log
}
/
${
train_model_name
}
"
set_export_weight
=
"
${
save_log
}
/
${
train_model_name
}
"
...
@@ -272,7 +272,7 @@ else
...
@@ -272,7 +272,7 @@ else
export_cmd
=
"
${
python
}
${
run_export
}
${
set_export_weight_path
}
${
set_save_infer_key
}
"
export_cmd
=
"
${
python
}
${
run_export
}
${
set_export_weight_path
}
${
set_save_infer_key
}
"
eval
"
$export_cmd
"
eval
"
$export_cmd
"
status_check
$?
"
${
export_cmd
}
"
"
${
status_log
}
"
status_check
$?
"
${
export_cmd
}
"
"
${
status_log
}
"
#run inference
#run inference
eval
$env
eval
$env
save_infer_path
=
"
${
save_log
}
"
save_infer_path
=
"
${
save_log
}
"
...
@@ -282,11 +282,10 @@ else
...
@@ -282,11 +282,10 @@ else
infer_model_dir
=
${
save_infer_path
}
infer_model_dir
=
${
save_infer_path
}
fi
fi
func_inference
"
${
python
}
"
"
${
inference_py
}
"
"
${
infer_model_dir
}
"
"
${
LOG_PATH
}
"
"
${
train_infer_img_dir
}
"
"
${
flag_quant
}
"
func_inference
"
${
python
}
"
"
${
inference_py
}
"
"
${
infer_model_dir
}
"
"
${
LOG_PATH
}
"
"
${
train_infer_img_dir
}
"
"
${
flag_quant
}
"
eval
"unset CUDA_VISIBLE_DEVICES"
eval
"unset CUDA_VISIBLE_DEVICES"
fi
fi
done
# done with: for trainer in ${trainer_list[*]}; do
done
# done with: for trainer in ${trainer_list[*]}; do
done
# done with: for autocast in ${autocast_list[*]}; do
done
# done with: for autocast in ${autocast_list[*]}; do
done
# done with: for gpu in ${gpu_list[*]}; do
done
# done with: for gpu in ${gpu_list[*]}; do
fi
# end if [ ${MODE} = "infer" ]; then
fi
# end if [ ${MODE} = "infer" ]; then
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}