Replace gif and photos in README & Revise the docs of video restore (#322)
* revise video restore docs * delete photos * Update README.md * Update install.md * update readme * Update README.md
Showing
docs/imgs/animeganv2.png
已删除
100644 → 0
{kind=link}

1.7 MB
docs/imgs/color_sr_peking.gif
已删除
100644 → 0
{kind=link}
因为 它太大了无法显示 image diff 。你可以改为 查看blob。
docs/imgs/dain_network.png
已删除
100644 → 0
{kind=link}
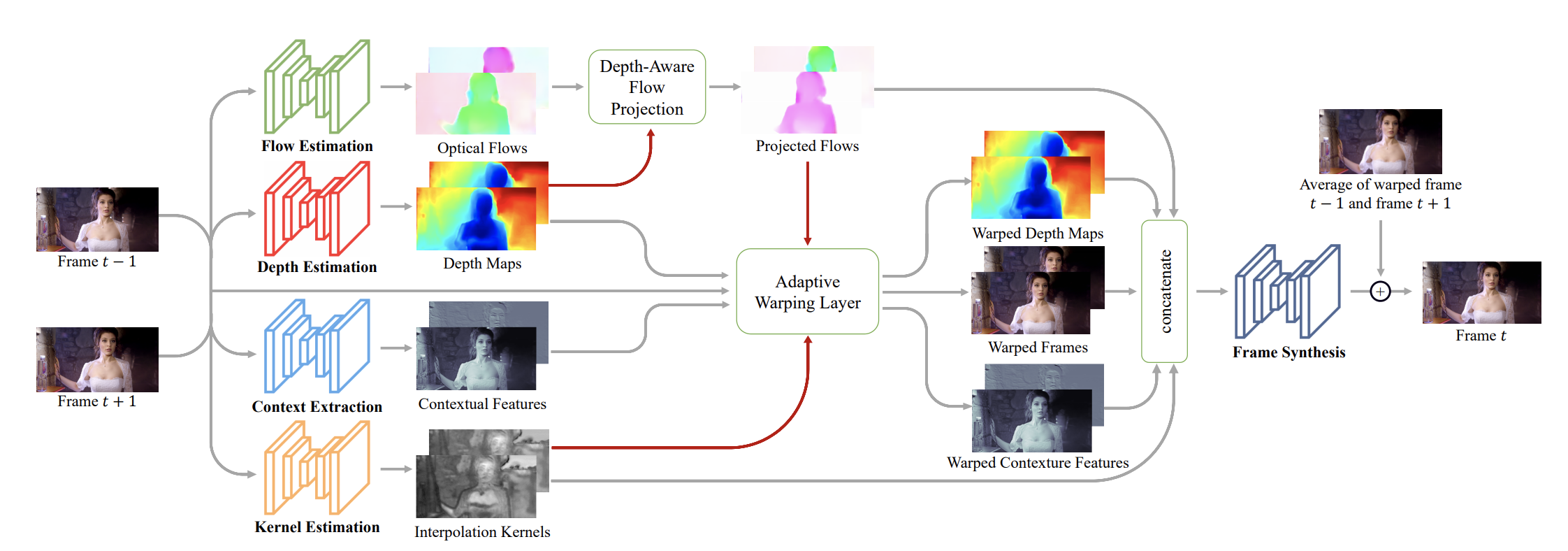
649.5 KB
{kind=link}
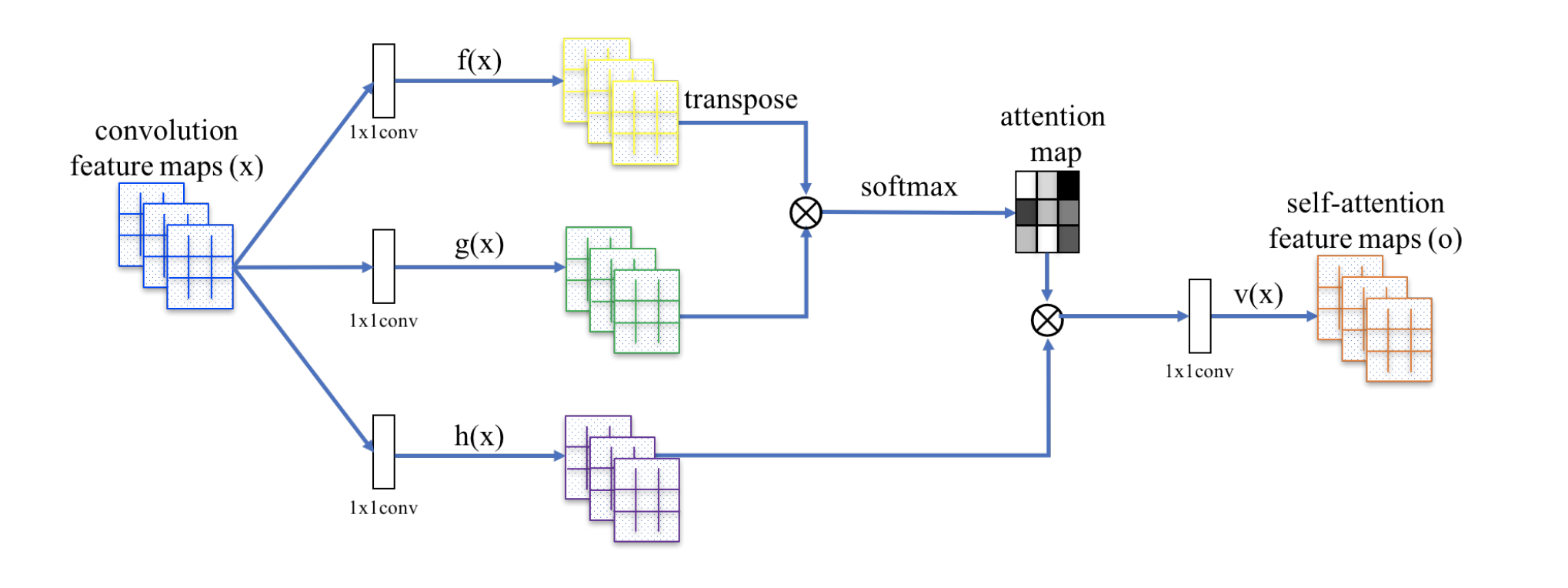
240.9 KB
docs/imgs/edvr_network.png
已删除
100644 → 0
{kind=link}
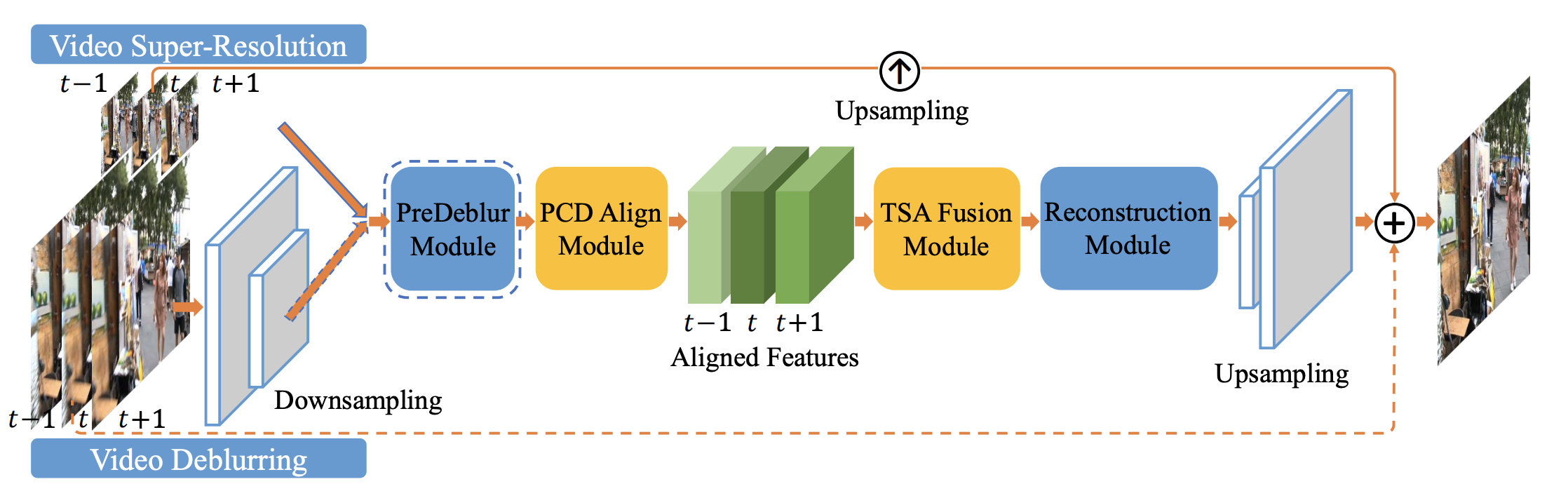
464.2 KB
docs/imgs/first_order.gif
已删除
100644 → 0
{kind=link}

7.4 MB
docs/imgs/horse2zebra.gif
已删除
100644 → 0
{kind=link}
因为 它太大了无法显示 image diff 。你可以改为 查看blob。
docs/imgs/makeup_shifter.png
已删除
100644 → 0
{kind=link}

1.5 MB
docs/imgs/mona.gif
已删除
100644 → 0
{kind=link}

961.1 KB
docs/imgs/photo2cartoon.png
已删除
100644 → 0
{kind=link}

882.9 KB
docs/imgs/realsr_network.png
已删除
100644 → 0
{kind=link}
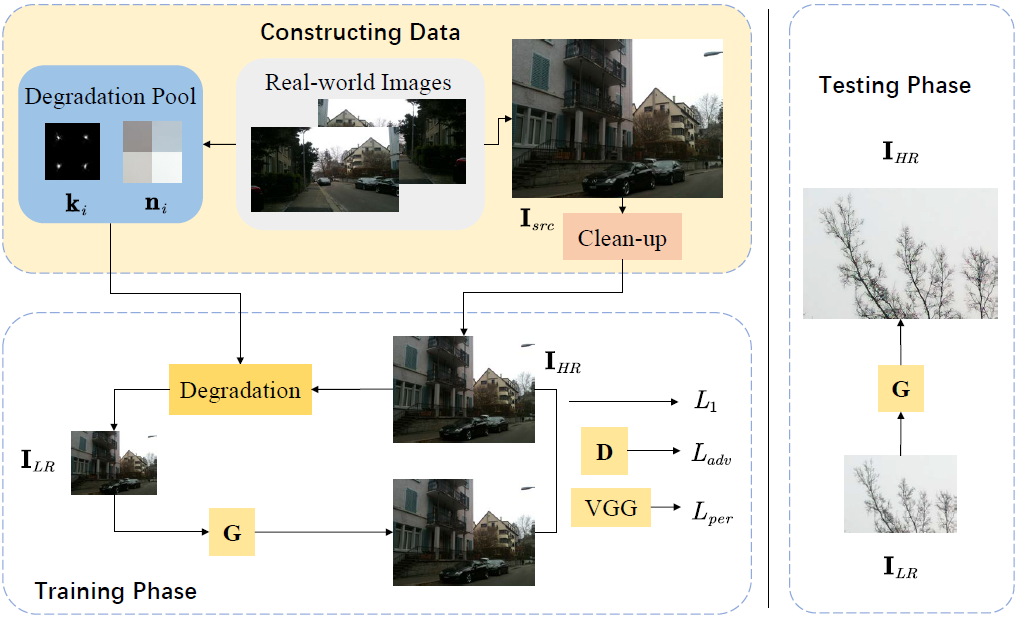
271.8 KB
{kind=link}
514.1 KB
docs/imgs/sr_demo.png
已删除
100644 → 0
{kind=link}

1.7 MB
docs/imgs/ugatit.png
已删除
100644 → 0
{kind=link}

824.9 KB