Paddle FL MPC (PFM) is a framework for privacy-preserving deep learning based on PaddlePaddle. It follows the same running mechanism and programming paradigm with PaddlePaddle, while using secure multi-party computation (MPC) to enable secure training and prediction.
With PFM, it is easy to train models or conduct prediction as on PaddlePaddle over encrypted data, without the need for cryptography expertise. Furthermore, the rich industry-oriented models and algorithms built on PaddlePaddle can be smoothly migrated to secure versions on PFM with little effort.
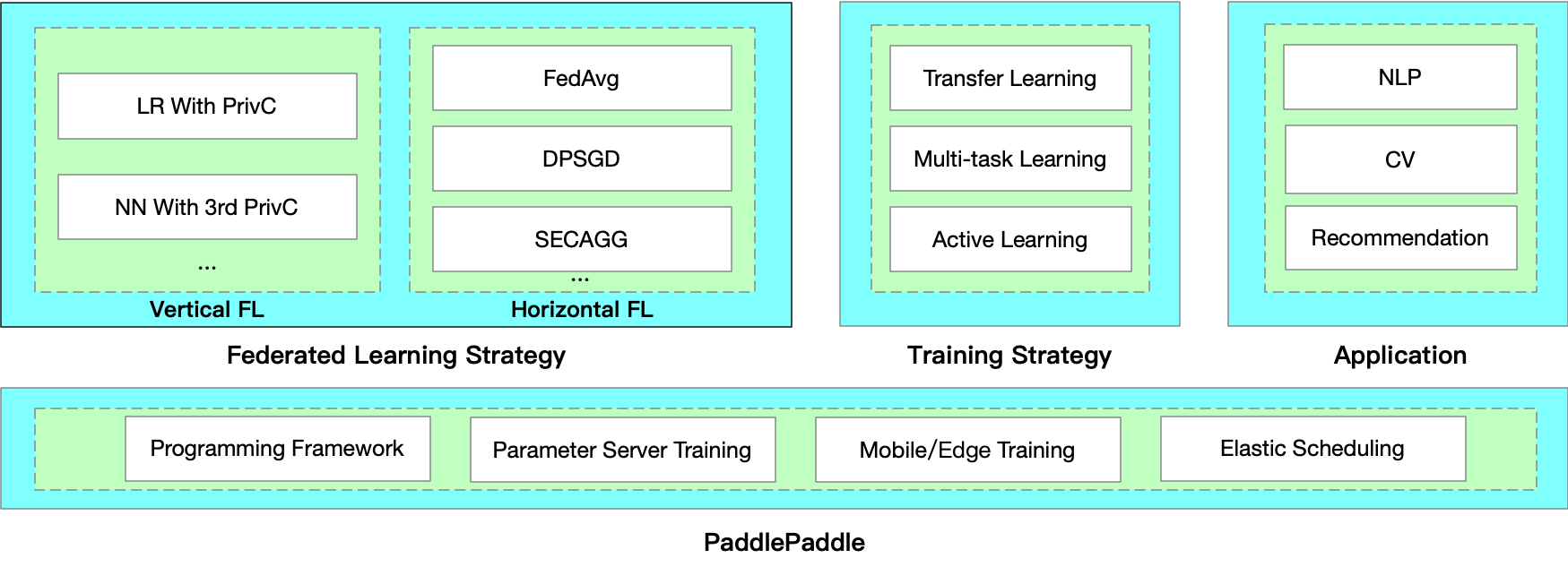
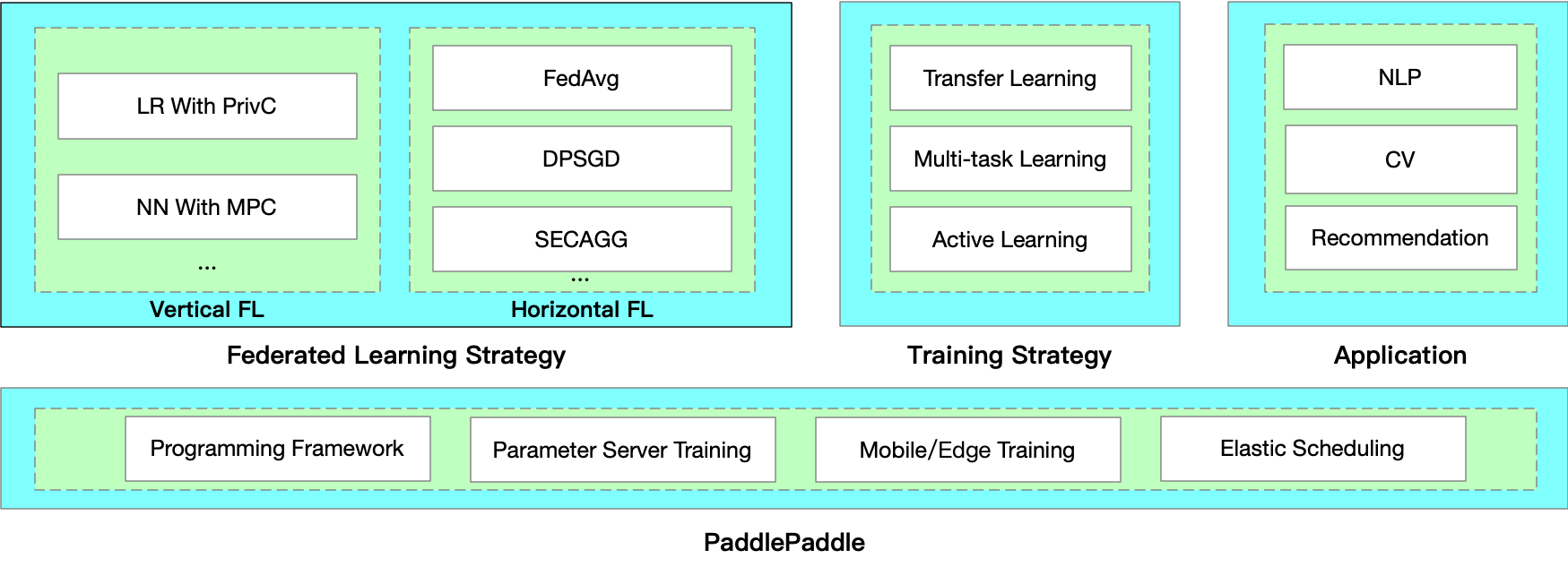
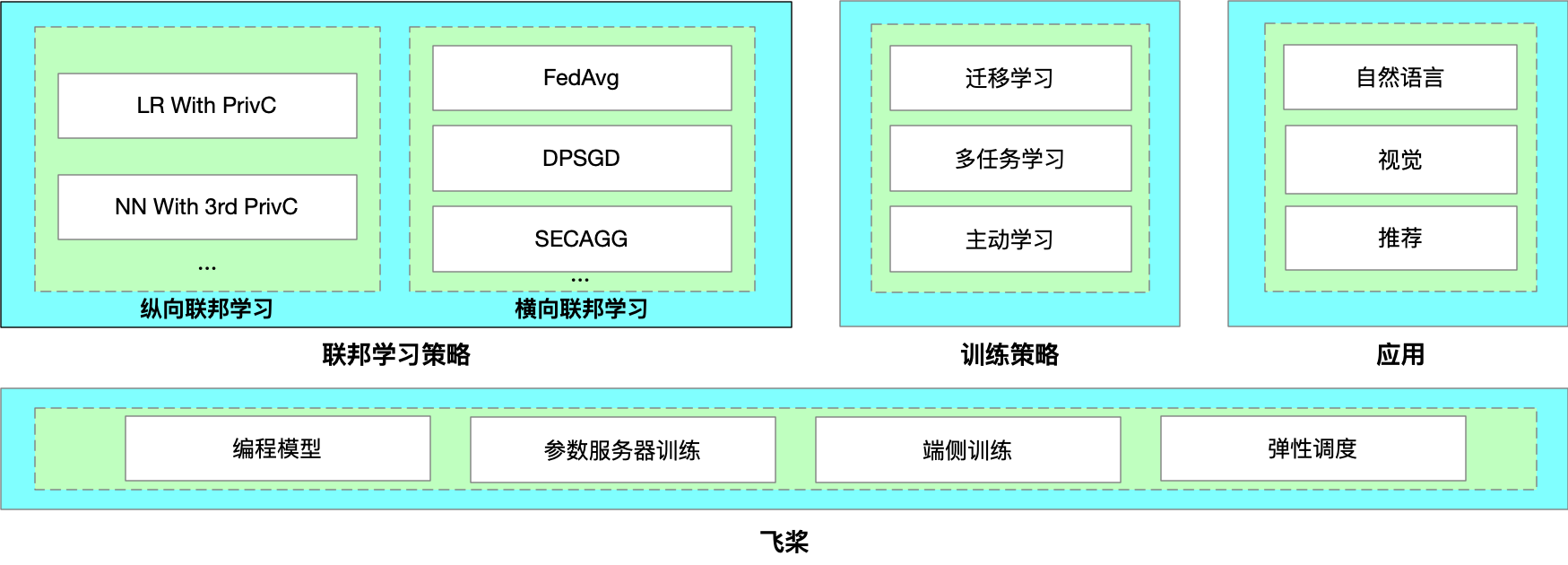
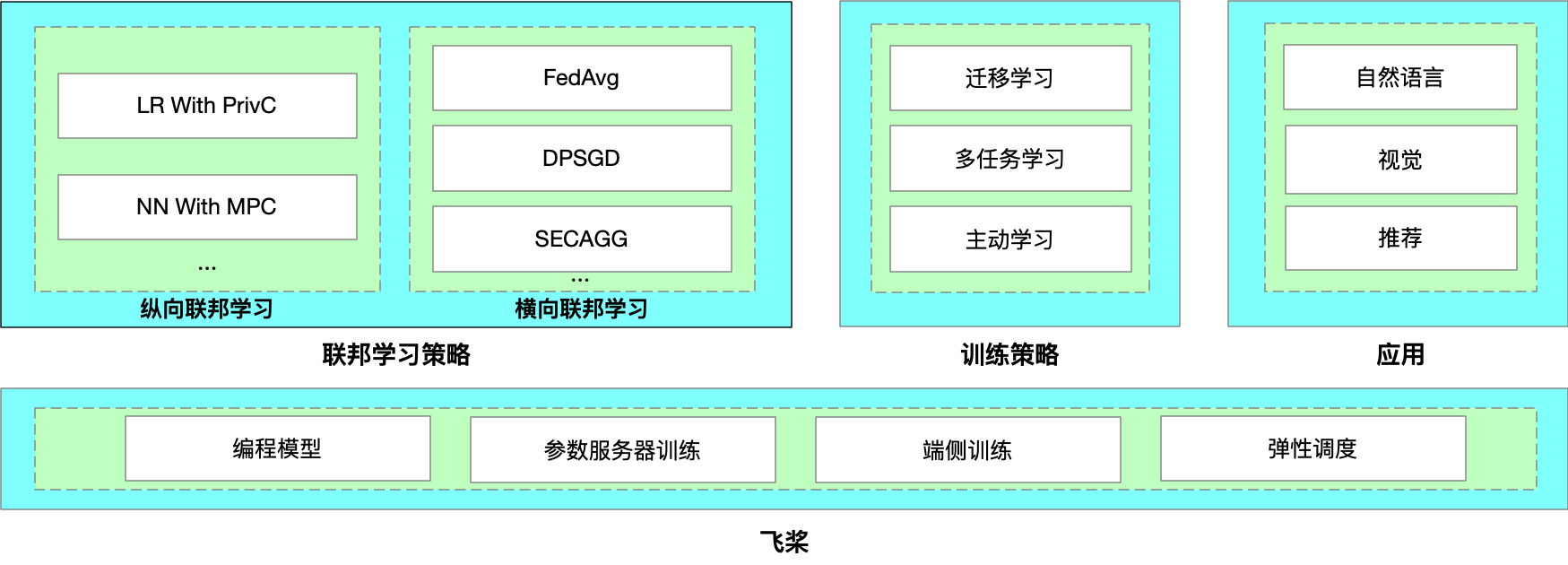
As a key product of PaddleFL, PFM intrinsically supports federated learning well, including horizontal, vertical and transfer learning scenarios. It provides both provable security (semantic security) and competitive performance.
Execute compile commands, where `PYTHON_EXECUTABLE` is path to the python binary where the PaddlePaddle is installed, `CMAKE_CXX_COMPILER` is the path of G++ and `PYTHON_INCLUDE_DIRS` is the corresponding python include directory. You can get the `PYTHON_INCLUDE_DIRS` via the following command:
If you want to compile and install from source code, please click [here](./docs/source/md/compile_and_install.md) to get instructions.
There are mainly two components in PaddleFL: **Data Parallel** and **Federated Learning with MPC (PFM)**.
With Data Parallel, distributed data holders can finish their Federated Learning tasks based on common horizontal federated strategies, such as FedAvg, DPSGD, etc.
Besides, PFM is implemented based on secure multi-party computation (MPC) to enable secure training and prediction. As a key product of PaddleFL, PFM intrinsically supports federated learning well, including horizontal, vertical and transfer learning scenarios. Users with little cryptography expertise can also train models or conduct prediction on encrypted data.
In PaddleFL, components for defining a federated learning task and training a federated learning job are as follows:
...
...
@@ -126,54 +84,19 @@ In PaddleFL, components for defining a federated learning task and training a fe
-**FL-Worker**: Each organization participates in federated learning will have one or more federated workers that will communicate with the federated parameter server.
-**FL-scheduler**: Decide which set of trainers can join the training before each updating cycle.
-**FL-scheduler**: Decide which set of trainers can join the training before each updating cycle.
For more instructions, please refer to the [examples](./python/paddle_fl/paddle_fl/examples)
### Federated Learning with MPC
Paddle FL MPC implements secure training and inference tasks based on the underlying MPC protocol like ABY3[11], which is a high efficient three-party computing model.
In ABY3, participants can be classified into roles of Input Party (IP), Computing Party (CP) and Result Party (RP). Input Parties (e.g., the training data/model owners) encrypt and distribute data or models to Computing Parties. Computing Parties (e.g., the VM on the cloud) conduct training or inference tasks based on specific MPC protocols, being restricted to see only the encrypted data or models, and thus guarantee the data privacy. When the computation is completed, one or more Result Parties (e.g., data owners or specified third-party) receive the encrypted results from Computing Parties, and reconstruct the plaintext results. Roles can be overlapped, e.g., a data owner can also act as a computing party.
A full training or inference process in PFM consists of mainly three phases: data preparation, training/inference, and result reconstruction.
#### A. Data preparation
##### 1. Private data alignment
PFM enables data owners (IPs) to find out records with identical keys (like UUID) without revealing private data to each other. This is especially useful in the vertical learning cases where segmented features with same keys need to be identified and aligned from all owners in a private manner before training. Using the OT-based PSI (Private Set Intersection) algorithm, PFM can perform private alignment at a speed of up to 60k records per second.
##### 2. Encryption and distribution
In PFM, data and models from IPs will be encrypted using Secret-Sharing[10], and then be sent to CPs, via directly transmission or distributed storage like HDFS. Each CP can only obtain one share of each piece of data, and thus is unable to recover the original value in the Semi-honest model.
As in PaddlePaddle, a training or inference job can be separated into the compile-time phase and the run-time phase:
##### 1. Compile time
***MPC environment specification**: a user needs to choose a MPC protocol, and configure the network settings. In current version, PFM provides only the "ABY3" protocol. More protocol implementation will be provided in future.
***User-defined job program**: a user can define the machine learning model structure and the training strategies (or inference task) in a PFM program, using the secure operators.
##### 2. Run time
A PFM program is exactly a PaddlePaddle program, and will be executed as normal PaddlePaddle programs. For example, in run-time a PFM program will be transpiled into ProgramDesc, and then be passed to and run by the Executor. The main concepts in the run-time phase are as follows:
***Computing nodes**: a computing node is an entity corresponding to a Computing Party. In real deployment, it can be a bare-metal machine, a cloud VM, a docker or even a process. PFM requires exactly three computing nodes in each run, which is determined by the underlying ABY3 protocol. A PFM program will be deployed and run in parallel on all three computing nodes.
***Operators using MPC**: PFM provides typical machine learning operators in `paddle_fl.mpc` over encrypted data. Such operators are implemented upon PaddlePaddle framework, based on MPC protocols like ABY3. Like other PaddlePaddle operators, in run time, instances of PFM operators are created and run in order by Executor.
#### C. Result reconstruction
Upon completion of the secure training (or inference) job, the models (or prediction results) will be output by CPs in encrypted form. Result Parties can collect the encrypted results, decrypt them using the tools in PFM, and deliver the plaintext results to users.
For more instructions, please refer to [mpc examples](./python/paddle_fl/mpc/examples)
{kind=link}
{kind=link}
{kind=link}
{kind=link}