This document introduces how to use PaddleFL to train a model with Fl Strategy: DPSGD.
### Dependencies
- paddlepaddle>=1.6
### How to install PaddleFL
Please use python which has paddlepaddle installed
```
python setup.py install
```
### Model
The simplest Softmax regression model is to get features with input layer passing through a fully connected layer and then compute and ouput probabilities of multiple classifications directly via Softmax function [[PaddlePaddle tutorial: recognize digits](https://github.com/PaddlePaddle/book/tree/develop/02.recognize_digits#references)].
### Datasets
Public Dataset [MNIST](http://yann.lecun.com/exdb/mnist/)
The dataset will downloaded automatically in the API and will be located under `/home/username/.cache/paddle/dataset/mnist`:
| train-images-idx3-ubyte | train data picture, 60,000 data |
| train-labels-idx1-ubyte | train data label, 60,000 data |
| t10k-images-idx3-ubyte | test data picture, 10,000 data |
| t10k-labels-idx1-ubyte | test data label, 10,000 data |
### How to work in PaddleFL
PaddleFL has two phases , CompileTime and RunTime. In CompileTime, a federated learning task is defined by fl_master. In RunTime, a federated learning job is executed on fl_server and fl_trainer in distributed clusters.
```
sh run.sh
```
#### How to work in CompileTime
In this example, we implement compile time programs in fl_master.py
```
python fl_master.py
```
In fl_master.py, we first define FL-Strategy, User-Defined-Program and Distributed-Config. Then FL-Job-Generator generate FL-Job for federated server and worker.
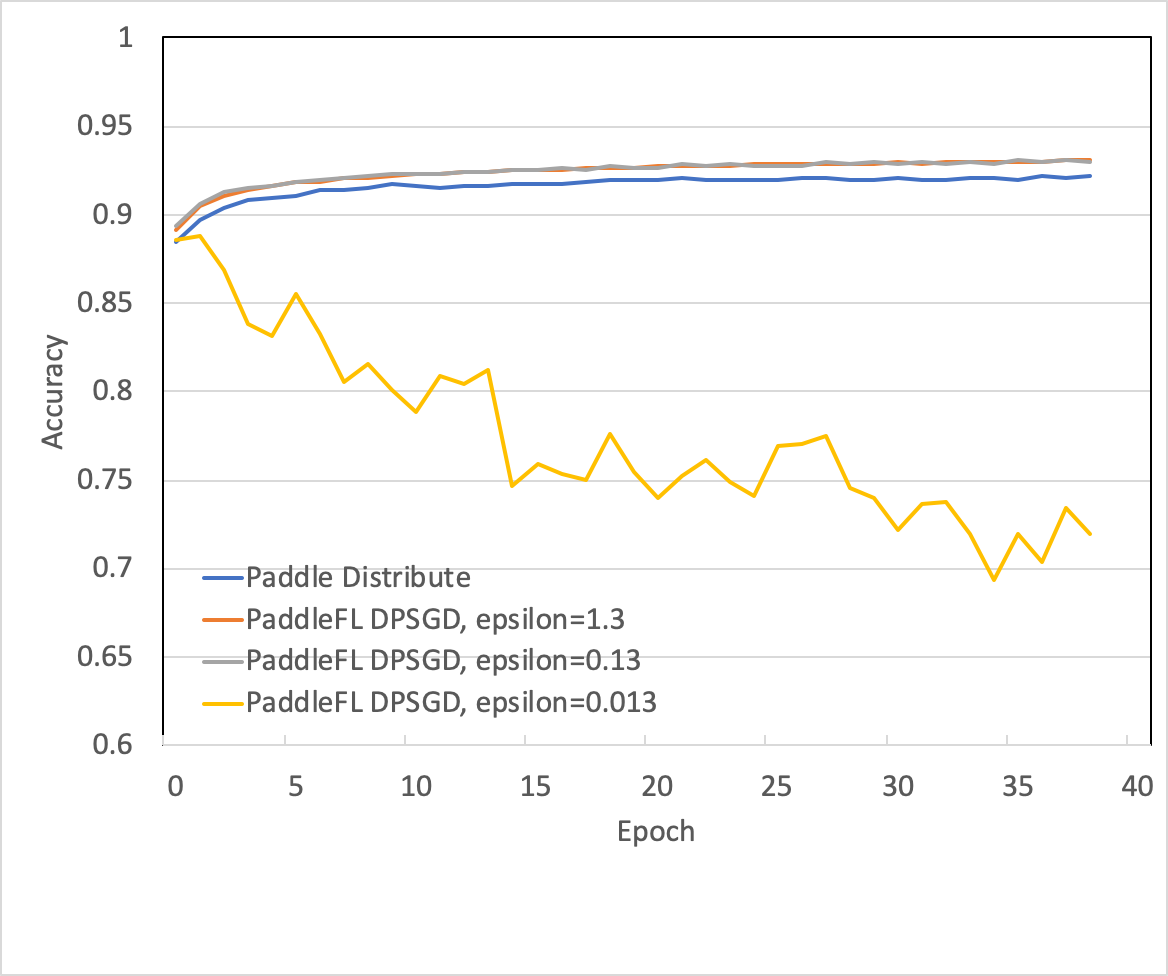
To show the effectiveness of DPSGD-based federated learning with PaddleFL, a simulated experiment is conducted on an open source dataset MNIST. From the figure given below, model evaluation results are similar between DPSGD-based federated learning and traditional parameter server training when the overall privacy budget *epsilon* is 1.3 or 0.13.
{kind=link}