Merge pull request #1 from guru4elephant/trainer_with_run
initial commit of PaddleFL
Showing
.gitignore
0 → 100644
README_cn.md
0 → 100644
{kind=link}
121.8 KB
docs/source/_static/FL-logo.png
0 → 100644
{kind=link}
205.2 KB
{kind=link}
202.8 KB
docs/source/api/paddle_fl.rst
0 → 100644
docs/source/contents.rst
0 → 100644
{kind=link}
211.8 KB
docs/source/introduction.rst
0 → 100644
docs/source/md/introduction.md
0 → 100644
docs/source/md/logo.md
0 → 100644
docs/source/md/quick_start.md
0 → 100644
docs/source/md/reference.md
0 → 100644
docs/source/reference.rst
0 → 100644
docs/source/team.rst
0 → 100644
docs/src/team.rst
已删除
100644 → 0
images/FL-framework.png
0 → 100644
{kind=link}
121.8 KB
images/FL-training.png
0 → 100644
{kind=link}
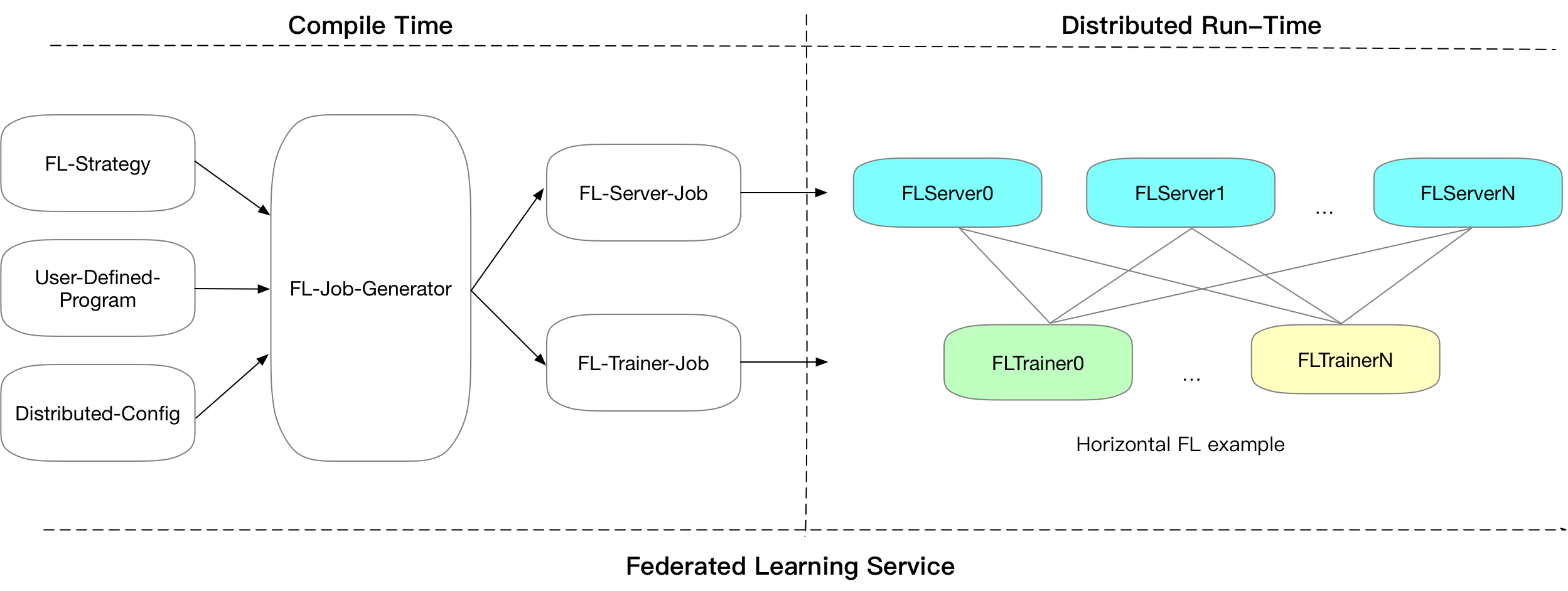
202.8 KB
paddle_fl/__init__.py
0 → 100644
paddle_fl/core/__init__.py
0 → 100644
paddle_fl/core/master/__init__.py
0 → 100644
paddle_fl/core/master/fl_job.py
0 → 100644
paddle_fl/core/server/__init__.py
0 → 100644
此差异已折叠。
paddle_fl/reader/__init__.py
0 → 100644
paddle_fl/version.py
0 → 100644