yolo训练时间随gpu数目增加而增加
Created by: barry2025
环境: docker: paddlepaddle/paddle:1.7.1-gpu-cuda9.0-cudnn7 paddledetection: release0.2 模型:yolov3_r50vd_dcn.yml,yolov3_r34_voc.yml 显卡:P4, V100
固定config中的batch_size,采用2卡训练:
 采用单卡训练:
采用单卡训练:
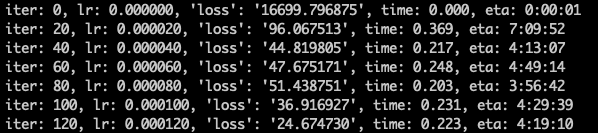
每张卡的batch_size是一样的,但是每次的迭代时间随着卡数增加而增加了,请问这里是有什么配置或者环境没设置好吗