导出fastrcnn模型使用CPU预测内存溢出
Created by: atczyh
使用faster_rcnn_r50_1x.yml完成模型训练后,按照EXPORT_MODEL.md教程方法导出模型:
python3 tools/export_model.py -c configs/faster_rcnn_r50_1x.yml --output_dir=./inference_model -o weights=output/faster_rcnn_r50_1x/model_final
导出模型后使用https://github.com/PaddlePaddle/PaddleDetection/pull/147/files/bab5c42223eb5fb5daf537b2c43b67a5e6689ca6#diff-62bd3de6f2c75660138c062aaaf2797e提供的tools/tensorrt_infer.py 进行预测,预测命令如下:
python3 tools/tensorinfer.py --model_path=inference_model/faster_rcnn_r50_1x/ --infer_img=PaddleDetection/000003.jpg --arch=RCNN --mode=trt_fp32 --visualize --min_subgraph_size=30
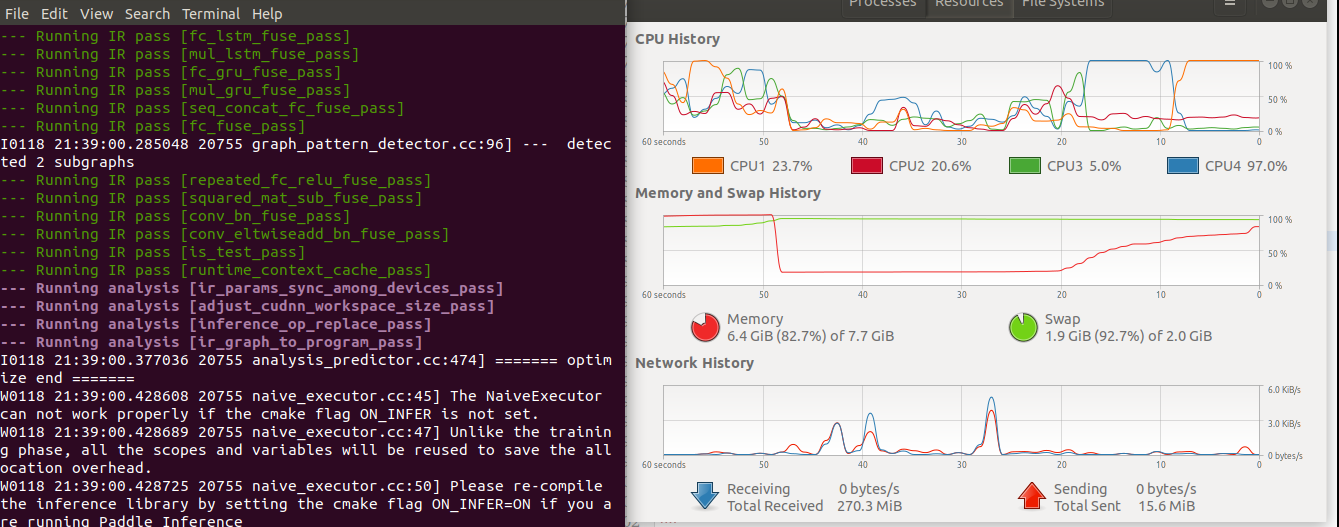
启动预测后内存用量不断增加,直至内存全部使用完毕,预测停止
I0118 21:40:01.983398 20802 graph_pattern_detector.cc:96] --- detected 2 subgraphs
--- Running IR pass [repeated_fc_relu_fuse_pass]
--- Running IR pass [squared_mat_sub_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
--- Running IR pass [is_test_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
I0118 21:40:02.078835 20802 analysis_predictor.cc:474] ======= optimize end =======
W0118 21:40:02.124074 20802 naive_executor.cc:45] The NaiveExecutor can not work properly if the cmake flag ON_INFER is not set.
W0118 21:40:02.124132 20802 naive_executor.cc:47] Unlike the training phase, all the scopes and variables will be reused to save the allocation overhead.
W0118 21:40:02.124141 20802 naive_executor.cc:50] Please re-compile the inference library by setting the cmake flag ON_INFER=ON if you are running Paddle Inference
Killed
 请帮忙看看什么原因导致的?
请帮忙看看什么原因导致的?