Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleDetection
提交
f7144154
P
PaddleDetection
项目概览
PaddlePaddle
/
PaddleDetection
大约 2 年 前同步成功
通知
708
Star
11112
Fork
2696
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
184
列表
看板
标记
里程碑
合并请求
40
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleDetection
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
184
Issue
184
列表
看板
标记
里程碑
合并请求
40
合并请求
40
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
f7144154
编写于
9月 21, 2020
作者:
C
cnn
提交者:
GitHub
9月 21, 2020
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add yolov3_mobilenet_v1_roadsign.yml, fix bug, test=document_fix (#1461)
上级
6300438e
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
304 addition
and
2 deletion
+304
-2
configs/yolov3_mobilenet_v1_roadsign.yml
configs/yolov3_mobilenet_v1_roadsign.yml
+302
-0
docs/images/visualdl_roadsign.png
docs/images/visualdl_roadsign.png
+0
-0
docs/tutorials/QUICK_STARTED_cn.md
docs/tutorials/QUICK_STARTED_cn.md
+2
-2
未找到文件。
configs/yolov3_mobilenet_v1_roadsign.yml
0 → 100644
浏览文件 @
f7144154
#####################################基础配置#####################################
# 检测算法使用YOLOv3,backbone使用MobileNet_v1
# 检测模型的名称
architecture
:
YOLOv3
# 根据硬件选择是否使用GPU
use_gpu
:
true
#
### max_iters为最大迭代次数,而一个iter会运行batch_size * device_num张图片。batch_size在下面 TrainReader.batch_size设置。
max_iters
:
3600
# log平滑参数,平滑窗口大小,会从取历史窗口中取log_smooth_window大小的loss求平均值
log_smooth_window
:
20
# 模型保存文件夹
save_dir
:
output
# 每隔多少迭代保存模型
snapshot_iter
:
200
# ### mAP 评估方式,mAP评估方式可以选择COCO和VOC或WIDERFACE,其中VOC有11point和integral两种评估方法
# VOC数据格式只能使用VOC mAP评估方法
metric
:
VOC
map_type
:
integral
# ### pretrain_weights 可以是imagenet的预训练好的分类模型权重,也可以是在VOC或COCO数据集上的预训练的检测模型权重
# 模型配置文件和权重文件可参考[模型库](https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.4/docs/MODEL_ZOO.md)
pretrain_weights
:
https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1.tar
# 模型保存文件夹,如果开启了--eval,会在这个文件夹下保存best_model
weights
:
output/yolov3_mobilenet_v1_roadsign/
# ### 根据用户数据设置类别数,注意这里不含背景类
num_classes
:
4
# finetune时忽略的参数,按照正则化匹配,匹配上的参数会被忽略掉
finetune_exclude_pretrained_params
:
[
'
yolo_output'
]
# use_fine_grained_loss
use_fine_grained_loss
:
false
# 检测模型的结构
YOLOv3
:
# 默认是 MobileNetv1
backbone
:
MobileNet
yolo_head
:
YOLOv3Head
# 检测模型的backbone
MobileNet
:
norm_decay
:
0.
conv_group_scale
:
1
with_extra_blocks
:
false
# 检测模型的Head
YOLOv3Head
:
# anchor_masks
anchor_masks
:
[[
6
,
7
,
8
],
[
3
,
4
,
5
],
[
0
,
1
,
2
]]
# 3x3 anchors
anchors
:
[[
10
,
13
],
[
16
,
30
],
[
33
,
23
],
[
30
,
61
],
[
62
,
45
],
[
59
,
119
],
[
116
,
90
],
[
156
,
198
],
[
373
,
326
]]
# yolo_loss
yolo_loss
:
YOLOv3Loss
# nms 类型参数,可以设置为[MultiClassNMS, MultiClassSoftNMS, MatrixNMS], 默认使用 MultiClassNMS
nms
:
# background_label,背景标签(类别)的索引,如果设置为 0 ,则忽略背景标签(类别)。如果设置为 -1 ,则考虑所有类别。默认值:0
background_label
:
-1
# NMS步骤后每个图像要保留的总bbox数。 -1表示在NMS步骤之后保留所有bbox。
keep_top_k
:
100
# 在NMS中用于剔除检测框IOU的阈值,默认值:0.3 。
nms_threshold
:
0.45
# 基于 score_threshold 的过滤检测后,根据置信度保留的最大检测次数。
nms_top_k
:
1000
# 是否归一化,默认值:True 。
normalized
:
false
# 过滤掉低置信度分数的边界框的阈值。
score_threshold
:
0.01
YOLOv3Loss
:
# 这里的batch_size与训练中的batch_size(即TrainReader.batch_size)不同.
# 仅且当use_fine_grained_loss=true时,计算Loss时使用,且必须要与TrainReader.batch_size设置成一样
batch_size
:
8
# 忽略样本的阈值 ignore_thresh
ignore_thresh
:
0.7
# 是否使用label_smooth
label_smooth
:
true
LearningRate
:
# ### 学习率设置 参考 https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.4/docs/FAQ.md#faq%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98
# base_lr
base_lr
:
0.0001
# 学习率调整策略
# 具体实现参考[API](fluid.layers.piecewise_decay)
schedulers
:
# 学习率调整策略
-
!PiecewiseDecay
gamma
:
0.1
milestones
:
# ### 参考 https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.4/docs/FAQ.md#faq%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98
# ### 8/12 11/12
-
2400
-
3300
# 在训练开始时,调低学习率为base_lr * start_factor,然后逐步增长到base_lr,这个过程叫学习率热身,按照以下公式更新学习率
# linear_step = end_lr - start_lr
# lr = start_lr + linear_step * (global_step / warmup_steps)
# 具体实现参考[API](fluid.layers.linear_lr_warmup)
-
!LinearWarmup
start_factor
:
0.3333333333333333
steps
:
100
OptimizerBuilder
:
# 默认使用SGD+Momentum进行训练
# 具体实现参考[API](fluid.optimizer)
optimizer
:
momentum
:
0.9
type
:
Momentum
# 默认使用SGD+Momentum进行训练
# 具体实现参考[API](fluid.optimizer)
regularizer
:
factor
:
0.0005
type
:
L2
#####################################数据配置#####################################
# 模型训练集设置参考
# 训练、验证、测试使用的数据配置主要区别在数据路径、模型输入、数据增强参数设置
# 如果使用 yolov3_reader.yml,下面的参数设置优先级高,会覆盖yolov3_reader.yml中的参数设置。
# _READER_: 'yolov3_reader.yml'
TrainReader
:
# 训练过程中模型的输入设置
# 包括图片,图片长宽高等基本信息,图片id,标记的目标框,类别等信息
inputs_def
:
fields
:
[
'
image'
,
'
gt_bbox'
,
'
gt_class'
,
'
gt_score'
]
# num_max_boxes,每个样本的groud truth的最多保留个数,若不够用0填充。
num_max_boxes
:
50
# 训练数据集路径
dataset
:
# 指定数据集格式
!VOCDataSet
#dataset/xxx/
#├── annotations
#│ ├── xxx1.xml
#│ ├── xxx2.xml
#│ ├── xxx3.xml
#│ | ...
#├── images
#│ ├── xxx1.png
#│ ├── xxx2.png
#│ ├── xxx3.png
#│ | ...
#├── label_list.txt (用户自定义必须提供,且文件名称必须是label_list.txt。当使用VOC数据且use_default_label=true时,可不提供 )
#├── train.txt (训练数据集文件列表, ./images/xxx1.png ./Annotations/xxx1.xml)
#└── valid.txt (测试数据集文件列表)
# 图片文件夹相对路径,路径是相对于dataset_dir,图像路径= dataset_dir + image_dir + image_name
dataset_dir
:
dataset/roadsign_voc
# 标记文件名
anno_path
:
train.txt
# 是否包含背景类,若with_background=true,num_classes需要+1
# YOLO 系列with_background必须是false,FasterRCNN系列是true ###
with_background
:
false
sample_transforms
:
# 读取Image图像为numpy数组
# 可以选择将图片从BGR转到RGB,可以选择对一个batch中的图片做mixup增强
-
!DecodeImage
to_rgb
:
True
with_mixup
:
True
# MixupImage
-
!MixupImage
alpha
:
1.5
beta
:
1.5
# ColorDistort
-
!ColorDistort
{}
# RandomExpand
-
!RandomExpand
fill_value
:
[
123.675
,
116.28
,
103.53
]
# 随机扩充比例,默认值是4.0
ratio
:
1.5
-
!RandomCrop
{}
-
!RandomFlipImage
is_normalized
:
false
# 归一化坐标
-
!NormalizeBox
{}
# 如果 bboxes 数量小于 num_max_boxes,填充值为0的 box
-
!PadBox
num_max_boxes
:
50
# 坐标格式转化,从XYXY转成XYWH格式
-
!BboxXYXY2XYWH
{}
# 以下是对一个batch中的所有图片同时做的数据处理
batch_transforms
:
# 多尺度训练时,从list中随机选择一个尺寸,对一个batch数据同时同时resize
-
!RandomShape
sizes
:
[
320
,
352
,
384
,
416
,
448
,
480
,
512
,
544
,
576
,
608
]
random_inter
:
True
# NormalizeImage
-
!NormalizeImage
mean
:
[
0.485
,
0.456
,
0.406
]
std
:
[
0.229
,
0.224
,
0.225
]
is_scale
:
True
is_channel_first
:
false
-
!Permute
to_bgr
:
false
channel_first
:
True
# Gt2YoloTarget is only used when use_fine_grained_loss set as true,
# this operator will be deleted automatically if use_fine_grained_loss
# is set as false
-
!Gt2YoloTarget
anchor_masks
:
[[
6
,
7
,
8
],
[
3
,
4
,
5
],
[
0
,
1
,
2
]]
anchors
:
[[
10
,
13
],
[
16
,
30
],
[
33
,
23
],
[
30
,
61
],
[
62
,
45
],
[
59
,
119
],
[
116
,
90
],
[
156
,
198
],
[
373
,
326
]]
downsample_ratios
:
[
32
,
16
,
8
]
# 1个GPU的batch size,默认为1。需要注意:每个iter迭代会运行batch_size * device_num张图片
batch_size
:
8
# 是否shuffle
shuffle
:
true
# mixup,-1表示不做Mixup数据增强。注意,这里是epoch为单位
mixup_epoch
:
250
# 注意,在某些情况下,drop_last=false时训练过程中可能会出错,建议训练时都设置为true
drop_last
:
true
# 若选用多进程,设置使用多进程/线程的数目
# 开启多进程后,占用内存会成倍增加,根据内存设置###
worker_num
:
4
# 共享内存bufsize。注意,缓存是以batch为单位,缓存的样本数据总量为batch_size * bufsize,所以请注意不要设置太大,请根据您的硬件设置。
bufsize
:
2
# 是否使用多进程
use_process
:
true
EvalReader
:
# 评估过程中模型的输入设置
# 包括图片,图片长宽高等基本信息,图片id,标记的目标框,类别等信息
inputs_def
:
fields
:
[
'
image'
,
'
im_size'
,
'
im_id'
,
'
gt_bbox'
,
'
gt_class'
,
'
is_difficult'
]
# num_max_boxes,每个样本的groud truth的最多保留个数,若不够用0填充。
num_max_boxes
:
50
# 数据集路径
dataset
:
!VOCDataSet
# 图片文件夹相对路径,路径是相对于dataset_dir,图像路径= dataset_dir + image_dir + image_name
dataset_dir
:
dataset/roadsign_voc
# 评估文件列表
anno_path
:
valid.txt
# 是否包含背景类,若with_background=true,num_classes需要+1
# YOLO 系列with_background必须是false,FasterRCNN系列是true ###
with_background
:
false
sample_transforms
:
# 读取Image图像为numpy数组
# 可以选择将图片从BGR转到RGB,可以选择对一个batch中的图片做mixup增强
-
!DecodeImage
to_rgb
:
True
# ResizeImage
-
!ResizeImage
target_size
:
608
interp
:
2
# NormalizeImage
-
!NormalizeImage
mean
:
[
0.485
,
0.456
,
0.406
]
std
:
[
0.229
,
0.224
,
0.225
]
is_scale
:
True
is_channel_first
:
false
# 如果 bboxes 数量小于 num_max_boxes,填充值为0的 box
-
!PadBox
num_max_boxes
:
50
-
!Permute
to_bgr
:
false
channel_first
:
True
# 1个GPU的batch size,默认为1。需要注意:每个iter迭代会运行batch_size * device_num张图片
batch_size
:
8
# drop_empty
drop_empty
:
false
# 若选用多进程,设置使用多进程/线程的数目
# 开启多进程后,占用内存会成倍增加,根据内存设置###
worker_num
:
4
# 共享内存bufsize。注意,缓存是以batch为单位,缓存的样本数据总量为batch_size * bufsize,所以请注意不要设置太大,请根据您的硬件设置。
bufsize
:
2
TestReader
:
# 预测过程中模型的输入设置
# 包括图片,图片长宽高等基本信息,图片id,标记的目标框,类别等信息
inputs_def
:
# 预测图像输入尺寸
image_shape
:
[
3
,
608
,
608
]
fields
:
[
'
image'
,
'
im_size'
,
'
im_id'
]
# 数据集路径
dataset
:
# 预测数据
!ImageFolder
# anno_path
anno_path
:
dataset/roadsign_voc/label_list.txt
# 是否包含背景类,若with_background=true,num_classes需要+1
# YOLO 系列with_background必须是false,FasterRCNN系列是true ###
with_background
:
false
sample_transforms
:
-
!DecodeImage
to_rgb
:
True
# ResizeImage
-
!ResizeImage
# 注意与上面图像尺寸保持一致
target_size
:
608
interp
:
2
# NormalizeImage
-
!NormalizeImage
mean
:
[
0.485
,
0.456
,
0.406
]
std
:
[
0.229
,
0.224
,
0.225
]
is_scale
:
True
is_channel_first
:
false
# Permute
-
!Permute
to_bgr
:
false
channel_first
:
True
# 1个GPU的batch size,默认为1
batch_size
:
1
docs/images/visualdl_roadsign.png
查看替换文件 @
6300438e
浏览文件 @
f7144154
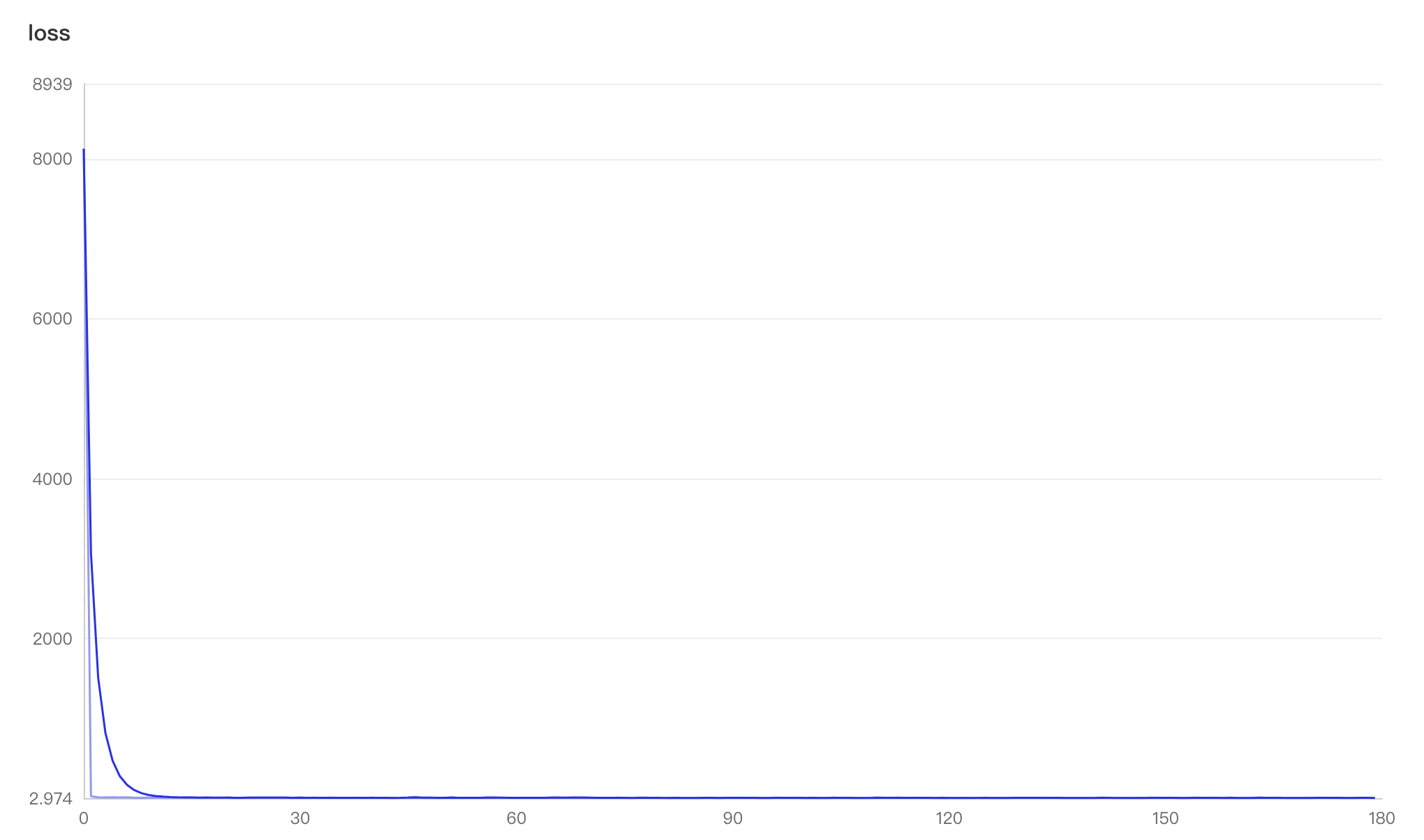
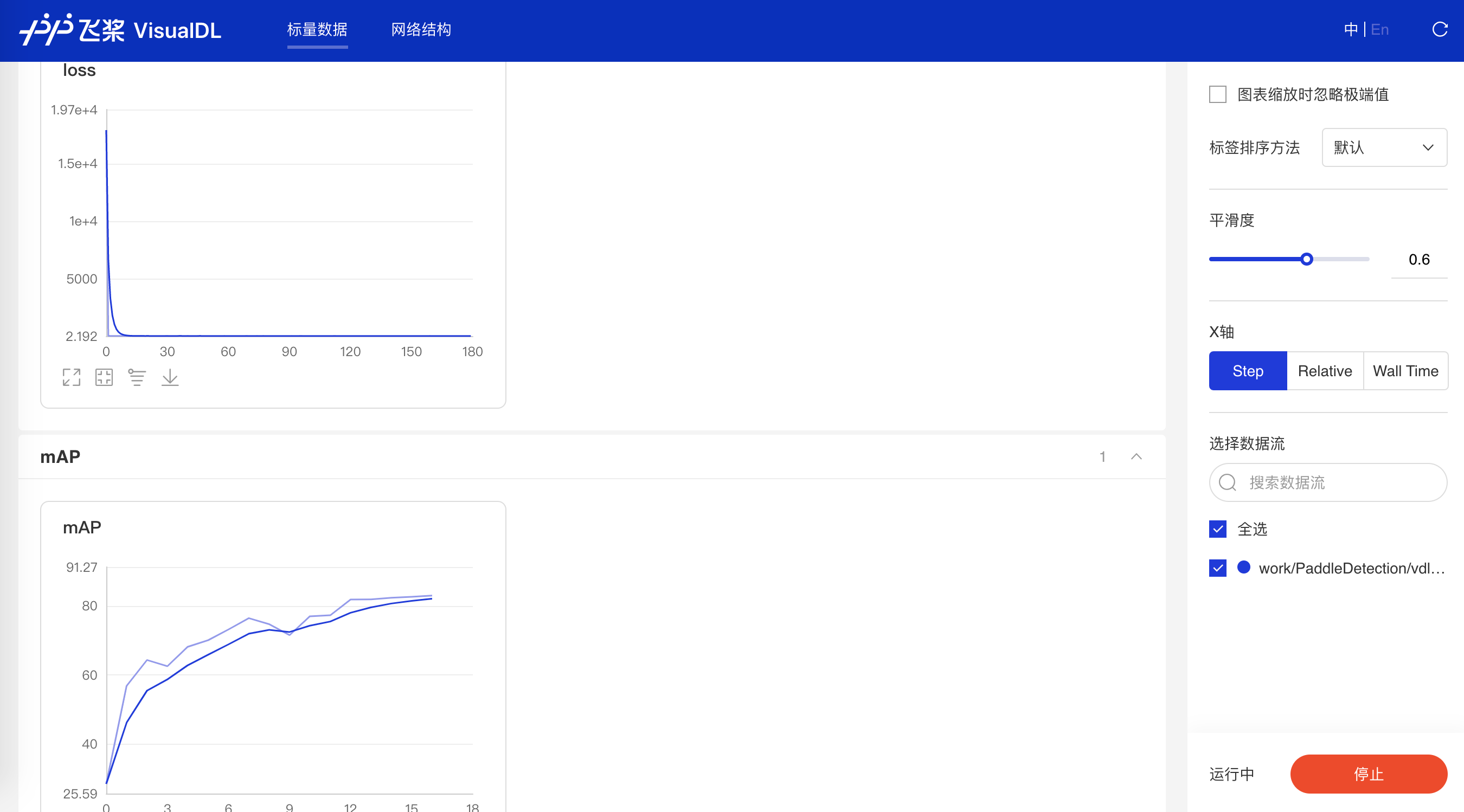
100.3 KB
|
W:
|
H:
216.8 KB
|
W:
|
H:
2-up
Swipe
Onion skin
docs/tutorials/QUICK_STARTED_cn.md
浏览文件 @
f7144154
...
@@ -59,9 +59,9 @@ visualdl --logdir vdl_dir/scalar/ --host <host_IP> --port <port_num>
...
@@ -59,9 +59,9 @@ visualdl --logdir vdl_dir/scalar/ --host <host_IP> --port <port_num>
# -c 参数表示指定使用哪个配置文件
# -c 参数表示指定使用哪个配置文件
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置)
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置)
python tools/eval.py -c configs/yolov3_mobilenet_v1_roadsign.yml-o use_gpu=true
python tools/eval.py -c configs/yolov3_mobilenet_v1_roadsign.yml
-o use_gpu=true
```
```

### 3、预测
### 3、预测
```
```
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}