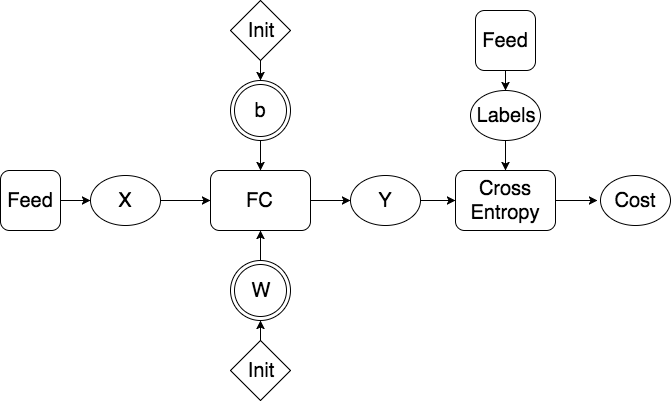
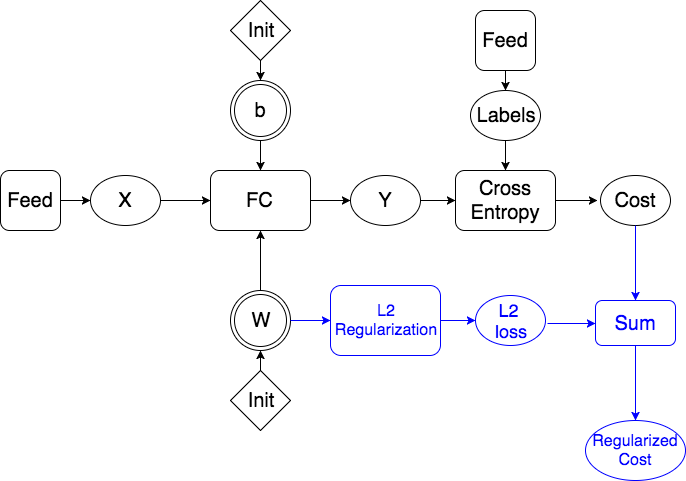
Design Doc for Regularization (#4869)
* Add initail design doc for regularization * Updating image links * Commiting the images for the equations * Adding computation graph images * Adding section on computation graph
Showing
{kind=link}
31.5 KB
{kind=link}
45.0 KB
{kind=link}
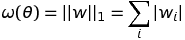
1.1 KB
{kind=link}
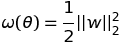
989 字节
{kind=link}
1.6 KB
doc/design/regularization.md
0 → 100644