Merge branch 'develop' into fix-crf-weight-and-coeff-bug
Showing
.dockerignore
0 → 120000
.gitmodules
0 → 100644
CONTRIBUTING.md
0 → 100644
WORKSPACE
0 → 100644
benchmark/.gitignore
0 → 100644
benchmark/README.md
0 → 100644
此差异已折叠。
benchmark/caffe/image/run.sh
0 → 100755
benchmark/figs/alexnet-4gpu.png
0 → 100644
{kind=link}
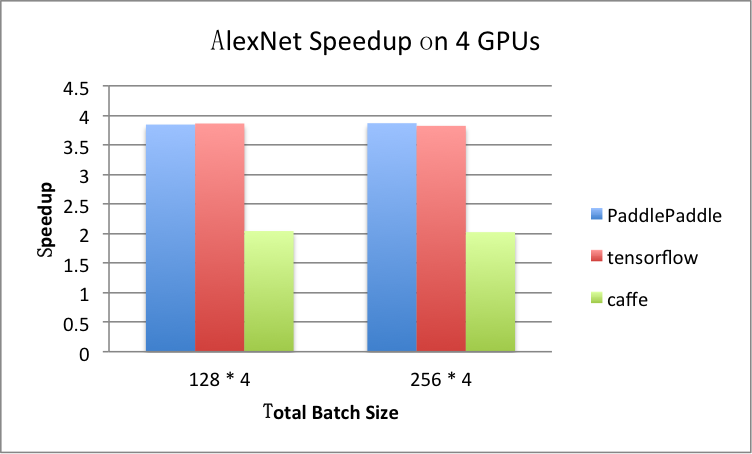
81.8 KB
benchmark/figs/googlenet-4gpu.png
0 → 100644
{kind=link}
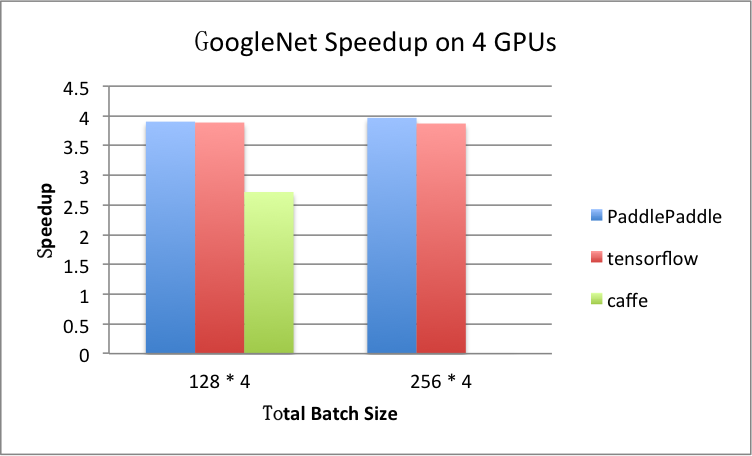
81.8 KB
benchmark/figs/rnn_lstm_4gpus.png
0 → 100644
{kind=link}
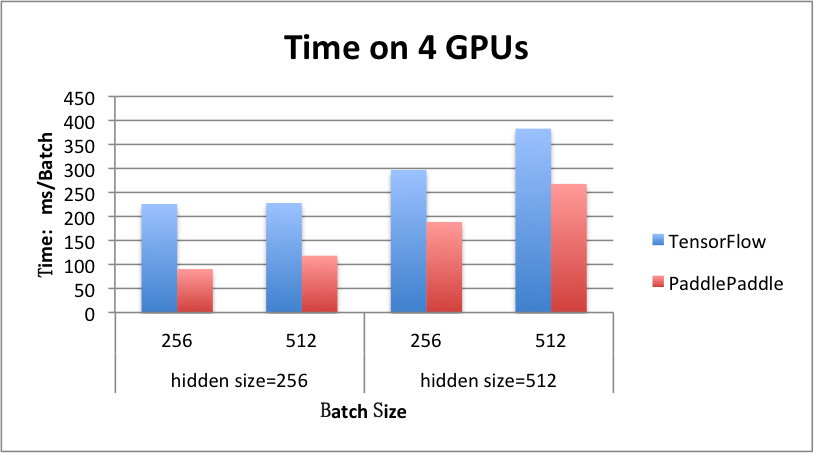
71.5 KB
benchmark/figs/rnn_lstm_cls.png
0 → 100644
{kind=link}
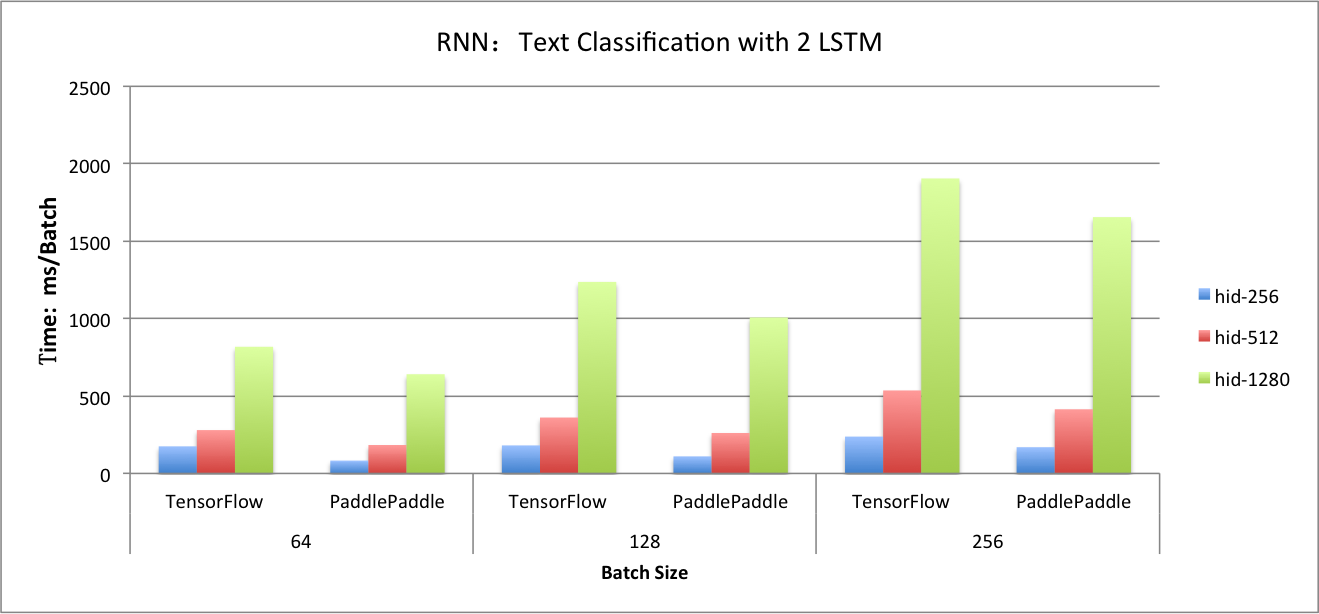
114.9 KB
benchmark/paddle/image/alexnet.py
0 → 100644
benchmark/paddle/image/run.sh
0 → 100755
benchmark/paddle/rnn/imdb.py
0 → 100755
benchmark/paddle/rnn/provider.py
0 → 100644
benchmark/paddle/rnn/rnn.py
0 → 100755
benchmark/paddle/rnn/run.sh
0 → 100755
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/image/run.sh
0 → 100755
此差异已折叠。
benchmark/tensorflow/rnn/rnn.py
0 → 100755
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/rnn/run.sh
0 → 100755
cmake/enableCXX11.cmake
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
cmake/version.cmake
0 → 100644
demo/gan/.gitignore
0 → 100644
demo/gan/README.md
0 → 100644
demo/gan/data/download_cifar.sh
0 → 100755
此差异已折叠。
demo/gan/data/get_mnist_data.sh
0 → 100755
此差异已折叠。
demo/gan/gan_conf.py
0 → 100644
此差异已折叠。
demo/gan/gan_conf_image.py
0 → 100644
此差异已折叠。
demo/gan/gan_trainer.py
0 → 100644
此差异已折叠。
demo/image_classification/predict.sh
100644 → 100755
此差异已折叠。
demo/introduction/.gitignore
0 → 100644
此差异已折叠。
此差异已折叠。
demo/quick_start/api_predict.py
0 → 100755
此差异已折叠。
demo/quick_start/api_predict.sh
0 → 100755
此差异已折叠。
demo/semantic_role_labeling/data/get_data.sh
100644 → 100755
此差异已折叠。
demo/semantic_role_labeling/predict.sh
100644 → 100755
此差异已折叠。
demo/semantic_role_labeling/test.sh
100644 → 100755
此差异已折叠。
demo/semantic_role_labeling/train.sh
100644 → 100755
此差异已折叠。
此差异已折叠。
doc/about/index_cn.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
文件已移动
此差异已折叠。
文件已移动
doc/api/index.rst
已删除
100644 → 0
此差异已折叠。
doc/api/index_cn.rst
0 → 100644
此差异已折叠。
doc/api/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
doc/getstarted/index_cn.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
doc/howto/index_cn.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/howto/source/api.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/howto/source/cuda/nn.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/howto/source/index.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/howto/source/trainer.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
此差异已折叠。
doc/index_cn.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/tutorials/index.md
已删除
100644 → 0
此差异已折叠。
doc/tutorials/index_cn.md
0 → 100644
此差异已折叠。
doc/tutorials/index_en.md
0 → 100644
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/CMakeLists.txt
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/cluster/index.rst
已删除
100644 → 0
此差异已折叠。
doc_cn/concepts/nn.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/demo/index.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/index.rst
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
doc_cn/ui/cmd/index.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/ui/index.rst
已删除
100644 → 0
此差异已折叠。
doc_theme/static/css/override.css
0 → 100644
此差异已折叠。
doc_theme/static/images/PP_w.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_theme/templates/layout.html
0 → 100644
此差异已折叠。
doc_theme/templates/search.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/math/TensorApply.h
0 → 100644
此差异已折叠。
paddle/math/TensorAssign.h
0 → 100644
此差异已折叠。
paddle/math/TensorEvaluate.h
0 → 100644
此差异已折叠。
paddle/math/TensorExpression.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/math/TrainingAlgorithmOp.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/math/tests/PerfUtils.h
0 → 100644
此差异已折叠。
paddle/math/tests/TensorCheck.h
0 → 100644
此差异已折叠。
paddle/math/tests/TestUtils.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/math/tests/test_Matrix.cpp
0 → 100644
此差异已折叠。
paddle/math/tests/test_Tensor.cu
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/scripts/docker/Dockerfile
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/scripts/docker/build.sh
100644 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/utils/CompilerMacros.h
已删除
100644 → 0
此差异已折叠。
paddle/utils/CpuId.cpp
0 → 100644
此差异已折叠。
paddle/utils/CpuId.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
third_party/gflags.BUILD
0 → 100644
此差异已折叠。
third_party/gflags_test/BUILD
0 → 100644
此差异已折叠。
此差异已折叠。
third_party/glog.BUILD
0 → 100644
此差异已折叠。
third_party/glog_test/BUILD
0 → 100644
此差异已折叠。
此差异已折叠。
third_party/gtest.BUILD
0 → 100644
此差异已折叠。
third_party/protobuf_test/BUILD
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。