add docs for custom dataset, reader and model technical (#2526)
* add docs for custom dataset, reader and model technical * modify docs according to review, test=document_fix * modify READER.md, test=document_fix
Showing
docs/advanced_tutorials/READER.md
0 → 100644
docs/images/model_figure.png
0 → 100644
{kind=link}
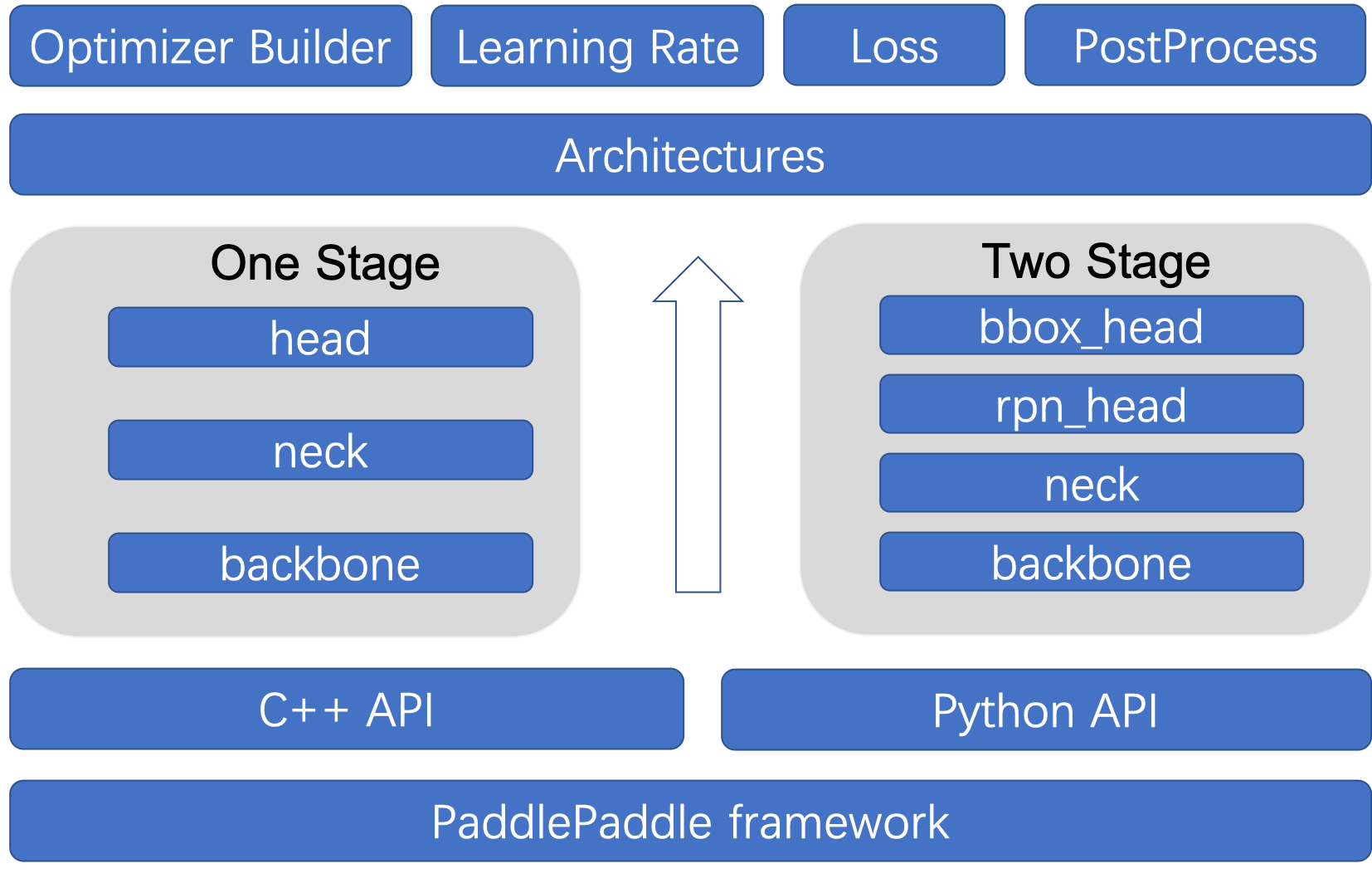
147.8 KB
docs/images/reader_figure.png
0 → 100644
{kind=link}
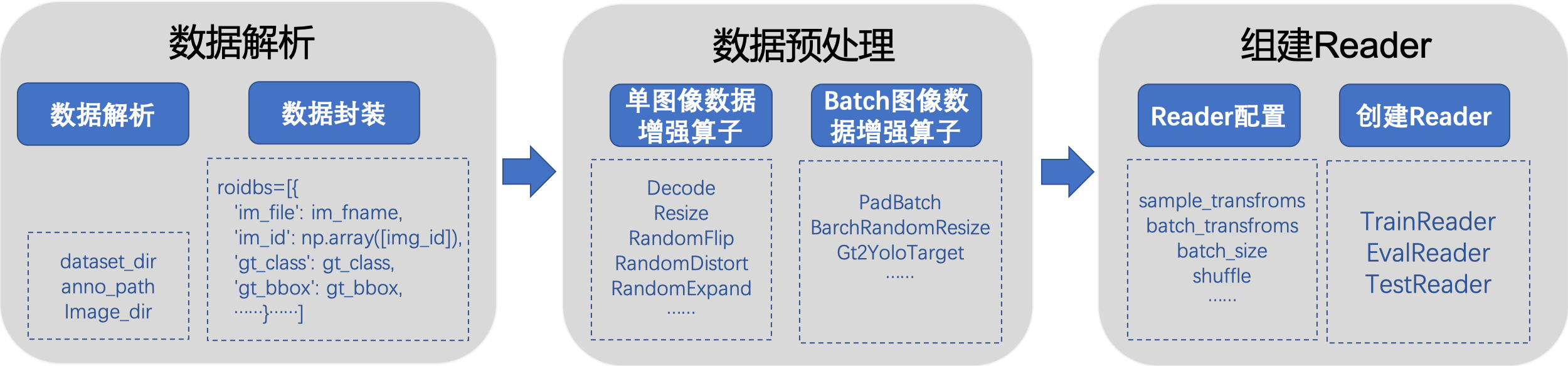
195.0 KB
ppdet/data/tools/x2coco.py
已删除
100644 → 0