Design doc for Model average(renaming it to Parameter Average) (#5137)
* Adding design doc for model average (now called parameter_average) * Updating title * Updating image tag * Updating review comments
Showing
doc/design/images/asgd.gif
0 → 100644
{kind=link}
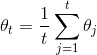
620 字节
doc/design/images/theta_star.gif
0 → 100644
{kind=link}
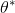
156 字节
doc/design/parameter_average.md
0 → 100644