Merge branch 'ppdet_split' of /paddle/work/paddle-fork/models
Showing
.gitignore
0 → 100644
.style.yapf
0 → 100644
README.md
0 → 100644
README_cn.md
0 → 100644
configs/face_detection/README.md
0 → 100644
configs/faster_rcnn_r101_1x.yml
0 → 100644
configs/faster_rcnn_r50_1x.yml
0 → 100644
configs/faster_rcnn_r50_2x.yml
0 → 100644
configs/faster_rcnn_r50_vd_1x.yml
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
configs/mask_rcnn_r101_fpn_1x.yml
0 → 100644
此差异已折叠。
此差异已折叠。
configs/mask_rcnn_r50_1x.yml
0 → 100644
此差异已折叠。
configs/mask_rcnn_r50_2x.yml
0 → 100644
此差异已折叠。
configs/mask_rcnn_r50_fpn_1x.yml
0 → 100644
此差异已折叠。
configs/mask_rcnn_r50_fpn_2x.yml
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
configs/retinanet_r101_fpn_1x.yml
0 → 100644
此差异已折叠。
configs/retinanet_r50_fpn_1x.yml
0 → 100644
此差异已折叠。
此差异已折叠。
configs/ssd/ssd_vgg16_300.yml
0 → 100644
此差异已折叠。
configs/ssd/ssd_vgg16_300_voc.yml
0 → 100644
此差异已折叠。
configs/ssd/ssd_vgg16_512.yml
0 → 100644
此差异已折叠。
configs/ssd/ssd_vgg16_512_voc.yml
0 → 100644
此差异已折叠。
configs/yolov3_darknet.yml
0 → 100644
此差异已折叠。
configs/yolov3_darknet_voc.yml
0 → 100644
此差异已折叠。
configs/yolov3_mobilenet_v1.yml
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
configs/yolov3_r34.yml
0 → 100644
此差异已折叠。
configs/yolov3_r34_voc.yml
0 → 100644
此差异已折叠。
{kind=link}

465.6 KB
{kind=link}

521.4 KB
{kind=link}

472.1 KB
{kind=link}

505.5 KB
{kind=link}

168.4 KB
{kind=link}

191.3 KB
此差异已折叠。
此差异已折叠。
contrib/README.md
0 → 100644
此差异已折叠。
contrib/README_cn.md
0 → 100644
此差异已折叠。
{kind=link}

78.6 KB
{kind=link}

794.1 KB
{kind=link}

885.4 KB
{kind=link}

834.8 KB
{kind=link}
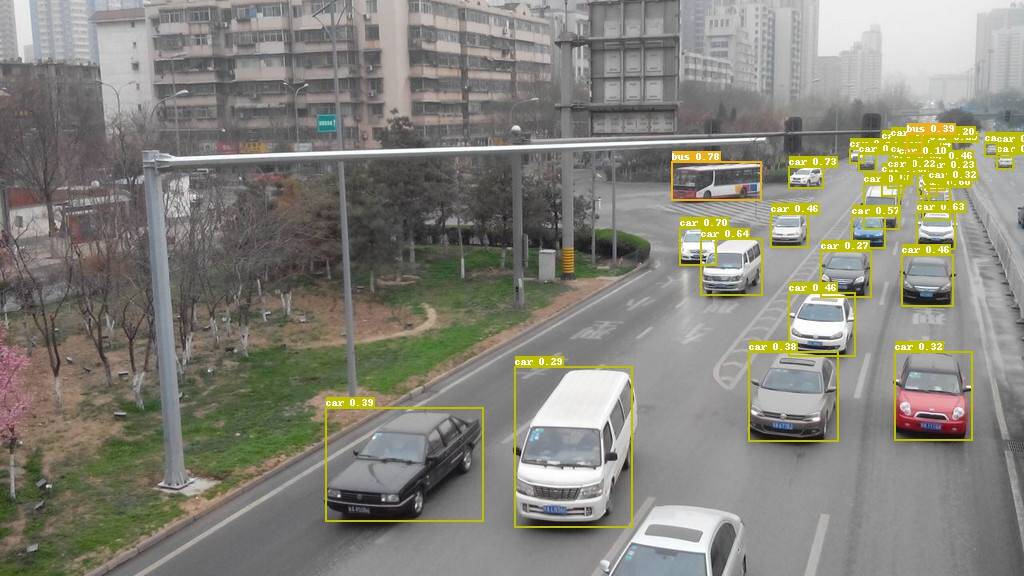
84.8 KB
{kind=link}

311.0 KB
此差异已折叠。
此差异已折叠。
dataset/coco/download_coco.py
0 → 100644
此差异已折叠。
dataset/fruit/download_fruit.py
0 → 100644
此差异已折叠。
dataset/voc/download_voc.py
0 → 100644
此差异已折叠。
dataset/wider_face/download.sh
0 → 100755
此差异已折叠。
demo/000000014439.jpg
0 → 100644
{kind=link}

190.7 KB
demo/000000014439_640x640.jpg
0 → 100644
{kind=link}
此差异已折叠。
demo/000000087038.jpg
0 → 100644
{kind=link}
此差异已折叠。
demo/000000570688.jpg
0 → 100644
{kind=link}
此差异已折叠。
demo/cas.png
0 → 100644
{kind=link}
此差异已折叠。
demo/mask_rcnn_demo.ipynb
0 → 100644
此差异已折叠。
demo/obj365_gt.png
0 → 100644
{kind=link}
此差异已折叠。
demo/obj365_pred.png
0 → 100644
{kind=link}
此差异已折叠。
demo/orange_71.jpg
0 → 100644
{kind=link}
此差异已折叠。
demo/orange_71_detection.jpg
0 → 100644
{kind=link}
此差异已折叠。
demo/output/000000570688.jpg
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
demo/tensorboard_fruit.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/BENCHMARK_INFER_cn.md
0 → 100644
此差异已折叠。
docs/CACascadeRCNN.md
0 → 100644
此差异已折叠。
docs/CONFIG.md
0 → 100644
此差异已折叠。
docs/CONFIG_cn.md
0 → 100644
此差异已折叠。
docs/DATA.md
0 → 100644
此差异已折叠。
docs/DATA_cn.md
0 → 100644
此差异已折叠。
docs/EXPORT_MODEL.md
0 → 100644
此差异已折叠。
docs/GETTING_STARTED.md
0 → 100644
此差异已折叠。
docs/GETTING_STARTED_cn.md
0 → 100644
此差异已折叠。
docs/INSTALL.md
0 → 100644
此差异已折叠。
docs/INSTALL_cn.md
0 → 100644
此差异已折叠。
docs/MODEL_ZOO.md
0 → 100644
此差异已折叠。
docs/MODEL_ZOO_cn.md
0 → 100644
此差异已折叠。
docs/QUICK_STARTED.md
0 → 100644
此差异已折叠。
docs/QUICK_STARTED_cn.md
0 → 100644
此差异已折叠。
docs/TRANSFER_LEARNING.md
0 → 100644
此差异已折叠。
docs/TRANSFER_LEARNING_cn.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
inference/CMakeLists.txt
0 → 100644
此差异已折叠。
inference/LICENSE
0 → 100644
此差异已折叠。
inference/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
inference/detection_demo.cpp
0 → 100644
此差异已折叠。
inference/docs/configuration.md
0 → 100644
此差异已折叠。
inference/docs/linux_build.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
inference/tools/coco17.json
0 → 100644
此差异已折叠。
此差异已折叠。
inference/tools/vis.py
0 → 100644
此差异已折叠。
inference/utils/conf_parser.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
inference/utils/utils.h
0 → 100644
此差异已折叠。
ppdet/__init__.py
0 → 100644
此差异已折叠。
ppdet/core/__init__.py
0 → 100644
此差异已折叠。
ppdet/core/config/__init__.py
0 → 100644
此差异已折叠。
ppdet/core/config/schema.py
0 → 100644
此差异已折叠。
ppdet/core/config/yaml_helpers.py
0 → 100644
此差异已折叠。
ppdet/core/workspace.py
0 → 100644
此差异已折叠。
ppdet/data/README.md
0 → 120000
此差异已折叠。
ppdet/data/README_cn.md
0 → 120000
此差异已折叠。
ppdet/data/__init__.py
0 → 100644
此差异已折叠。
ppdet/data/data_feed.py
0 → 100644
此差异已折叠。
ppdet/data/dataset.py
0 → 100644
此差异已折叠。
ppdet/data/reader.py
0 → 100644
此差异已折叠。
ppdet/data/source/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
ppdet/data/source/coco_loader.py
0 → 100644
此差异已折叠。
此差异已折叠。
ppdet/data/source/loader.py
0 → 100644
此差异已折叠。
ppdet/data/source/roidb_source.py
0 → 100644
此差异已折叠。
此差异已折叠。
ppdet/data/source/voc_loader.py
0 → 100644
此差异已折叠。
此差异已折叠。
ppdet/data/tests/000012.jpg
0 → 100644
{kind=link}
此差异已折叠。
ppdet/data/tests/coco.yml
0 → 100644
此差异已折叠。
此差异已折叠。
ppdet/data/tests/rcnn_dataset.yml
0 → 100644
此差异已折叠。
ppdet/data/tests/run_all_tests.py
0 → 100644
此差异已折叠。
ppdet/data/tests/set_env.py
0 → 100644
此差异已折叠。
此差异已折叠。
ppdet/data/tests/test_loader.py
0 → 100644
此差异已折叠。
ppdet/data/tests/test_operator.py
0 → 100644
此差异已折叠。
ppdet/data/tests/test_reader.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
ppdet/data/tools/labelme2coco.py
0 → 100644
此差异已折叠。
ppdet/data/transform/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
ppdet/data/transform/op_helper.py
0 → 100644
此差异已折叠。
ppdet/data/transform/operators.py
0 → 100644
此差异已折叠。
此差异已折叠。
ppdet/data/transform/post_map.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
ppdet/experimental/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
ppdet/modeling/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
ppdet/modeling/backbones/fpn.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
ppdet/modeling/backbones/senet.py
0 → 100644
此差异已折叠。
ppdet/modeling/backbones/vgg.py
0 → 100644
此差异已折叠。
ppdet/modeling/model_input.py
0 → 100644
此差异已折叠。
ppdet/modeling/ops.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
ppdet/modeling/tests/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
ppdet/optimizer.py
0 → 100644
此差异已折叠。
ppdet/utils/__init__.py
0 → 100644
此差异已折叠。
ppdet/utils/check.py
0 → 100644
此差异已折叠。
ppdet/utils/checkpoint.py
0 → 100644
此差异已折叠。
ppdet/utils/cli.py
0 → 100644
此差异已折叠。
ppdet/utils/coco_eval.py
0 → 100644
此差异已折叠。
ppdet/utils/colormap.py
0 → 100644
此差异已折叠。
ppdet/utils/dist_utils.py
0 → 100644
此差异已折叠。
ppdet/utils/download.py
0 → 100644
此差异已折叠。
ppdet/utils/eval_utils.py
0 → 100644
此差异已折叠。
ppdet/utils/map_utils.py
0 → 100644
此差异已折叠。
ppdet/utils/post_process.py
0 → 100644
此差异已折叠。
ppdet/utils/stats.py
0 → 100644
此差异已折叠。
ppdet/utils/visualizer.py
0 → 100644
此差异已折叠。
ppdet/utils/voc_eval.py
0 → 100644
此差异已折叠。
ppdet/utils/voc_utils.py
0 → 100644
此差异已折叠。
此差异已折叠。
requirements.txt
0 → 100644
此差异已折叠。
slim/distillation/README.md
0 → 100755
此差异已折叠。
slim/distillation/compress.py
0 → 100644
此差异已折叠。
slim/distillation/run.sh
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
slim/eval.py
0 → 100644
此差异已折叠。
slim/infer.py
0 → 100644
此差异已折叠。
slim/prune/README.md
0 → 100644
此差异已折叠。
slim/prune/compress.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
slim/quantization/README.md
0 → 100644
此差异已折叠。
slim/quantization/compress.py
0 → 100644
此差异已折叠。
slim/quantization/freeze.py
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
tools/__init__.py
0 → 100644
此差异已折叠。
tools/configure.py
0 → 100644
此差异已折叠。
tools/eval.py
0 → 100644
此差异已折叠。
tools/export_model.py
0 → 100644
此差异已折叠。
tools/face_eval.py
0 → 100644
此差异已折叠。
tools/infer.py
0 → 100644
此差异已折叠。
tools/train.py
0 → 100644
此差异已折叠。