merge develop
Showing
doc/design/python_api.md
0 → 100644
doc/design/refactor/session.md
0 → 100644
文件已添加
{kind=link}
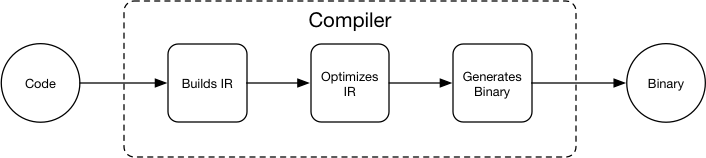
15.5 KB
文件已移动
{kind=link}
文件已添加
{kind=link}
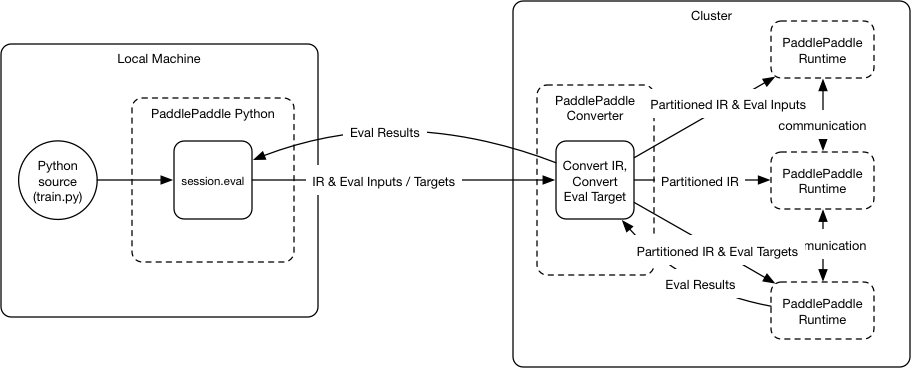
46.5 KB
文件已移动
{kind=link}
文件已添加
{kind=link}
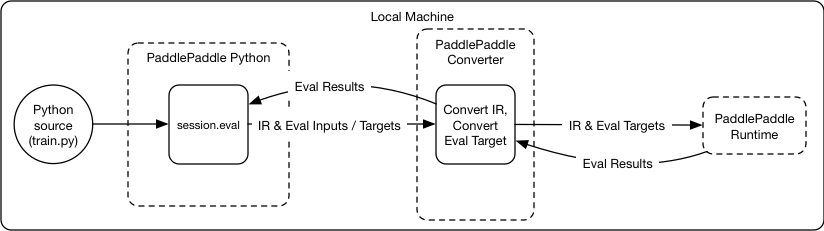
28.3 KB
文件已添加
{kind=link}
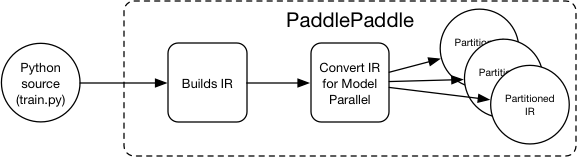
19.7 KB
doc/design/register_grad_op.md
0 → 100644
doc/design/tensor_array.md
0 → 100644
doc/faq/cluster/index_cn.rst
0 → 100644
此差异已折叠。
doc/faq/local/index_cn.rst
0 → 100644
文件已移动
文件已移动
doc/faq/model/index_cn.rst
0 → 100644
doc/faq/parameter/index_cn.rst
0 → 100644
doc/howto/dev/use_eigen_en.md
0 → 100644
paddle/framework/block_desc.cc
0 → 100644
paddle/framework/block_desc.h
0 → 100644
paddle/framework/data_type.h
0 → 100644
paddle/framework/op_desc.cc
0 → 100644
此差异已折叠。
paddle/framework/op_desc.h
0 → 100644
此差异已折叠。
paddle/framework/program_desc.cc
0 → 100644
此差异已折叠。
paddle/framework/program_desc.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/framework/tensor_array.cc
0 → 100644
此差异已折叠。
paddle/framework/tensor_array.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/framework/type_defs.h
0 → 100644
此差异已折叠。
paddle/framework/var_desc.cc
0 → 100644
此差异已折叠。
paddle/framework/var_desc.h
0 → 100644
此差异已折叠。
paddle/memory/.clang-format
已删除
100644 → 0
此差异已折叠。
paddle/memory/.clang-format
0 → 120000
此差异已折叠。
此差异已折叠。
paddle/operators/.clang-format
0 → 120000
此差异已折叠。
paddle/operators/adadelta_op.cc
0 → 100644
此差异已折叠。
paddle/operators/adadelta_op.cu
0 → 100644
此差异已折叠。
paddle/operators/adadelta_op.h
0 → 100644
此差异已折叠。
paddle/operators/adagrad_op.cc
0 → 100644
此差异已折叠。
paddle/operators/adagrad_op.cu
0 → 100644
此差异已折叠。
paddle/operators/adagrad_op.h
0 → 100644
此差异已折叠。
paddle/operators/adamax_op.cc
0 → 100644
此差异已折叠。
paddle/operators/adamax_op.h
0 → 100644
此差异已折叠。
paddle/operators/concat_op.cu
0 → 100644
此差异已折叠。
paddle/operators/conv_shift_op.cc
0 → 100644
此差异已折叠。
paddle/operators/conv_shift_op.cu
0 → 100644
此差异已折叠。
paddle/operators/conv_shift_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/operators/gather.cu.h
0 → 100644
此差异已折叠。
paddle/operators/gather_op.cu
0 → 100644
此差异已折叠。
paddle/operators/interp_op.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/math/pooling.cc
0 → 100644
此差异已折叠。
paddle/operators/math/pooling.cu
0 → 100644
此差异已折叠。
paddle/operators/math/pooling.h
0 → 100644
此差异已折叠。
paddle/operators/math/softmax.cu
0 → 100644
此差异已折叠。
paddle/operators/math/softmax.h
0 → 100644
此差异已折叠。
paddle/operators/pool_op.cc
0 → 100644
此差异已折叠。
paddle/operators/pool_op.cu
0 → 100644
此差异已折叠。
paddle/operators/pool_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/reduce_op.cc
0 → 100644
此差异已折叠。
paddle/operators/reduce_op.cu
0 → 100644
此差异已折叠。
paddle/operators/reduce_op.h
0 → 100644
此差异已折叠。
paddle/operators/rmsprop_op.cc
0 → 100644
此差异已折叠。
paddle/operators/rmsprop_op.cu
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/operators/scatter.cu.h
0 → 100644
此差异已折叠。
paddle/operators/scatter_op.cu
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/split_op.cu
0 → 100644
此差异已折叠。
paddle/pybind/.clang-format
0 → 120000
此差异已折叠。
paddle/pybind/exception.cc
0 → 100644
此差异已折叠。
paddle/pybind/exception.h
0 → 100644
此差异已折叠。
paddle/pybind/protobuf.cc
0 → 100644
此差异已折叠。
paddle/pybind/protobuf.h
0 → 100644
此差异已折叠。
paddle/string/.clang-format
0 → 120000
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。