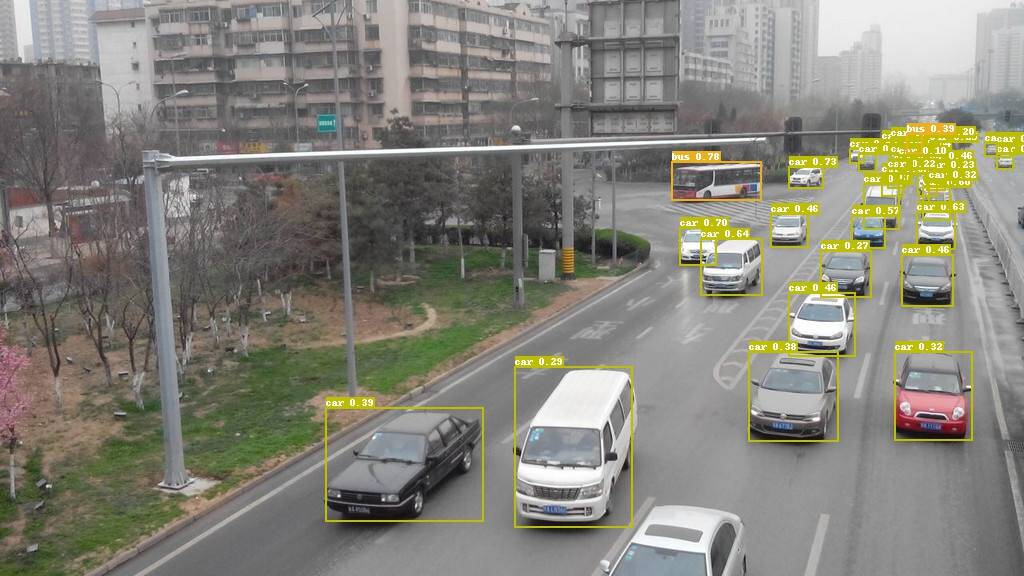
add models and documents for vehicle and pedestrian detection (#3559)
* add modes and documents for vehicle and pedestrian detection * remove needless output images * add class names * add Configure for training * fix table in READ.md * compress the images in the demo/output * change the score_threshold for vehicle inference * change Yolo v3 to YOLOv3
Showing
{kind=link}

465.6 KB
{kind=link}

521.4 KB
{kind=link}

472.1 KB
{kind=link}

505.5 KB
{kind=link}

168.4 KB
{kind=link}

191.3 KB
contrib/README.md
0 → 100644
contrib/README_cn.md
0 → 100644
{kind=link}

78.6 KB
{kind=link}

794.1 KB
{kind=link}

885.4 KB
{kind=link}

834.8 KB
{kind=link}
84.8 KB
{kind=link}

311.0 KB