The user can submit a distributed training job with Python code, rather than with a command-line interface.
## Runtime Environment On Kubernetes
For a distributed training job, there is two Docker image called *runtime Docker image* and *base Docker image*. The runtime Docker image is the Docker image that gets scheduled by Kubernetes to run during training. The base Docker image is for building the runtime Docker image.
### Base Docker Image
Usually, the base Docker image is PaddlePaddle product Docker image including paddle binary files and python package. And of course, users can specify any image name hosted on any docker registry which users have the access right.
### Runtime Docker Image
The trainer package which user upload and some Python dependencies are packaged into a runtime Docker image based on base Docker image.
- Handle Python Dependencies
You need to provide requirements.txt file in your `trainer-package` folder. Example:
```txt
pillow
protobuf==3.1.0
```
More [details](https://pip.readthedocs.io/en/1.1/requirements.html) about requirements, an example project looks like:
```bash
paddle_example
|-quick_start
|-trainer.py
|-dataset.py
|-requirements.txt
```
## Submit Distributed Training Job With Python Code
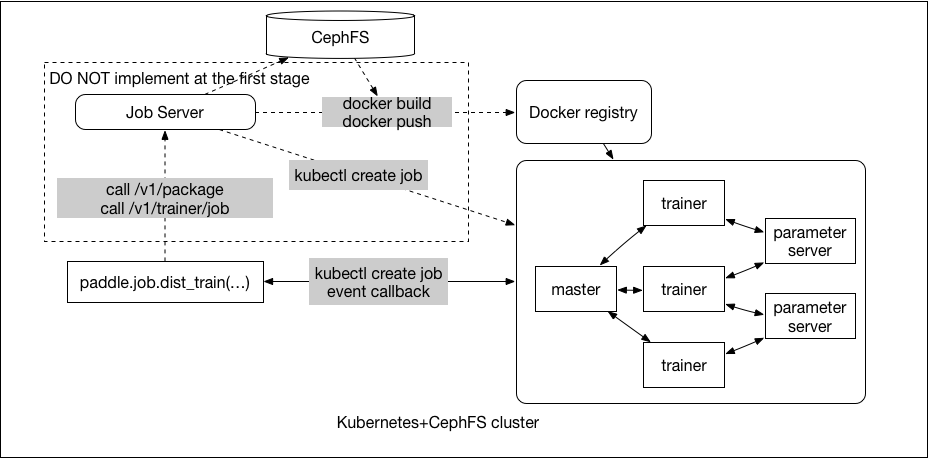
<imgsrc="./src/submit-job.png"width="800">
-`paddle.job.dist_train()` will call the Job Server API `/v1/packages` to upload the trainer package and save them on CephFS, and then call `/v1/trainer/job` to submit the PaddlePaddle distributed job.
-`/v1/trainer/job` will start a building job for preparing the runtime Docker image. When the building job is finished, Job Server will submit the PaddlePaddle distributed job to Kubernetes.
-*NOTE*: For the first version, we will not prepare the runtime Docker image, instead, the package is uploaded to Paddle Cloud, and Paddle Cloud will mount the package in a temporary folder into the base Docker image. We will not support custom Python dependencies in the first version as well.
You can call `paddle.job.dist_train` and provide distributed training configuration as the parameters:
```python
paddle.job.dist_train(
trainer=dist_trainer(),
paddle_job=PaddleJob(
job_name="paddle-cloud",
entry_point="python %s"%__file__,
trainer_package="/example/word2vec",
image="yancey1989/paddle-job",
trainers=10,
pservers=3,
trainer_cpu=1,
trainer_gpu=1,
trainer_mem="10G",
pserver_cpu=1,
pserver_mem="2G"
))
```
The parameter `trainer` of `paddle.job.dist_train` is a function and you can implement it as follows:
```python
defdist_trainer():
deftrainer_creator():
trainer=paddle.v2.trainer.SGD(...)
trainer.train(...)
returntrainer_creator
```
The pseudo code of `paddle.job.dist_train` is as follows:
```python
defdist_train(trainer,paddle_job):
# if the code is running on cloud, set PADDLE_ON_CLOUD=YES
ifos.getenv("RUNNING_ON_CLOUD","NO")=="NO":
#submit the paddle job
paddle_job.submit()
else:
#start the training
trainer()
```
### PaddleJob Parameters
parameter | type | explanation
--- | --- | ---
job_name | str | the unique name for the training job
entry_point | str | entry point for startup trainer process
trainer_package | str | trainer package file path which user have the access right
image|str|the [base image](#base-docker-image) for building the [runtime image](#runtime-docker-image)
pservers|int| Parameter Server process count
trainers|int| Trainer process count
pserver_cpu|int| CPU count for each Parameter Server process
pserver_mem|str| memory allocated for each Parameter Server process, a plain integer using one of these suffixes: E, P, T, G, M, K
trainer_cpu|int| CPU count for each Trainer process
trainer_mem|str| memory allocated for each Trainer process, a plain integer using one of these suffixes: E, P, T, G, M, K
trainer_gpu|int| GPU count for each Trainer process, if you only want CPU, do not set this parameter
### Deploy Parameter Server, Trainer and Master Process
- Deploy PaddlePaddle Parameter Server processes, it's a Kubernetes ReplicaSet.
- Deploy PaddlePaddle Trainer processes, it's a Kubernetes Job.
- Deploy PaddlePaddle Master processes, it's a Kubernetes ReplicaSet.
## Job Server
- RESTful API
Job server provides RESTful HTTP API for receiving the trainer package and displaying
PaddlePaddle job related informations.
-`POST /v1/package` receive the trainer package and save them on CephFS
-`POST /v1/trainer/job` submit a trainer job
-`GET /v1/jobs/` list all jobs
-`GET /v1/jobs/<job-name>` the status of a job
-`DELETE /v1/jobs/<job-name>` delete a job
-`GET /v1/version` job server version
- Build Runtime Docker Image on Kubernetes
`paddle.job.dist_train` will upload the trainer package to Job Server, save them on the distributed filesystem, and then start up a job for building the runtime Docker image that gets scheduled by Kubernetes to run during training.
There are some benefits for building runtime Docker image on JobServer:
- On Paddle Cloud, users will run the trainer code in a Jupyter Notebook which is a Kubernetes Pod, if we want to execute `docker build` in the Pod, we should mount the host's `docker.sock` to the Pod, user's code will connect the host's Docker Engine directly, it's not safe.
- Users only need to upload the training package files, does not need to install docker engine, docker registry as dependencies.
- If we want to change another image type, such as RKT, users do not need to care about it.
- Deploy Parameter Server, Trainer and Master Processes
`POST /v1/trainer/job` receives the distributed training parameters, and deploy the job as follows:
- Deploy PaddlePaddle Parameter Server processes, it's a Kubernetes ReplicaSet.
- Deploy PaddlePaddle Trainer processes, it's a Kubernetes Job.
- Deploy PaddlePaddle Master processes, it's a Kubernetes ReplicaSet.
{kind=link}