Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleDetection
提交
96192a85
P
PaddleDetection
项目概览
PaddlePaddle
/
PaddleDetection
大约 2 年 前同步成功
通知
708
Star
11112
Fork
2696
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
184
列表
看板
标记
里程碑
合并请求
40
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleDetection
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
184
Issue
184
列表
看板
标记
里程碑
合并请求
40
合并请求
40
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
96192a85
编写于
3月 29, 2018
作者:
T
typhoonzero
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'develop' of
https://github.com/PaddlePaddle/Paddle
into fix_dist_slr_height
上级
450be963
241f3c98
变更
12
隐藏空白更改
内联
并排
Showing
12 changed file
with
235 addition
and
14 deletion
+235
-14
cmake/generic.cmake
cmake/generic.cmake
+6
-0
doc/fluid/design/concurrent/channel.md
doc/fluid/design/concurrent/channel.md
+139
-0
doc/fluid/design/concurrent/images/channel_recv.png
doc/fluid/design/concurrent/images/channel_recv.png
+0
-0
doc/fluid/design/concurrent/images/channel_send.png
doc/fluid/design/concurrent/images/channel_send.png
+0
-0
paddle/fluid/framework/CMakeLists.txt
paddle/fluid/framework/CMakeLists.txt
+1
-1
paddle/fluid/framework/block_desc.cc
paddle/fluid/framework/block_desc.cc
+43
-6
paddle/fluid/framework/block_desc.h
paddle/fluid/framework/block_desc.h
+5
-0
paddle/scripts/submit_local.sh.in
paddle/scripts/submit_local.sh.in
+8
-2
python/paddle/fluid/layer_helper.py
python/paddle/fluid/layer_helper.py
+2
-3
python/paddle/fluid/layers/nn.py
python/paddle/fluid/layers/nn.py
+2
-1
python/paddle/fluid/nets.py
python/paddle/fluid/nets.py
+1
-1
python/paddle/fluid/tests/unittests/test_protobuf_descs.py
python/paddle/fluid/tests/unittests/test_protobuf_descs.py
+28
-0
未找到文件。
cmake/generic.cmake
浏览文件 @
96192a85
...
...
@@ -587,6 +587,9 @@ function(grpc_library TARGET_NAME)
get_filename_component
(
PROTO_WE
${
grpc_library_PROTO
}
NAME_WE
)
get_filename_component
(
PROTO_PATH
${
ABS_PROTO
}
PATH
)
#FIXME(putcn): the follwoing line is supposed to generate *.pb.h and cc, but
# somehow it didn't. line 602 to 604 is to patching this. Leaving this here
# for now to enable dist CI.
protobuf_generate_cpp
(
grpc_proto_srcs grpc_proto_hdrs
"
${
ABS_PROTO
}
"
)
set
(
grpc_grpc_srcs
"
${
CMAKE_CURRENT_BINARY_DIR
}
/
${
PROTO_WE
}
.grpc.pb.cc"
)
set
(
grpc_grpc_hdrs
"
${
CMAKE_CURRENT_BINARY_DIR
}
/
${
PROTO_WE
}
.grpc.pb.h"
)
...
...
@@ -597,6 +600,9 @@ function(grpc_library TARGET_NAME)
COMMAND
${
PROTOBUF_PROTOC_EXECUTABLE
}
ARGS --grpc_out
"
${
CMAKE_CURRENT_BINARY_DIR
}
"
-I
"
${
PROTO_PATH
}
"
--plugin=protoc-gen-grpc=
"
${
GRPC_CPP_PLUGIN
}
"
"
${
ABS_PROTO
}
"
COMMAND
${
PROTOBUF_PROTOC_EXECUTABLE
}
ARGS --cpp_out
"
${
CMAKE_CURRENT_BINARY_DIR
}
"
-I
"
${
PROTO_PATH
}
"
"
${
ABS_PROTO
}
"
DEPENDS
"
${
ABS_PROTO
}
"
${
PROTOBUF_PROTOC_EXECUTABLE
}
extern_grpc
)
# FIXME(typhoonzero): grpc generated code do not generate virtual-dtor, mark it
...
...
doc/fluid/design/concurrent/channel.md
0 → 100644
浏览文件 @
96192a85
# Channel Design
## Introduction
A Channel is a data structure that allows for synchronous interprocess
communication via message passing. It is a fundemental component of CSP
(communicating sequential processes), and allows for users to pass data
between threads without having to worry about synchronization.
## How to use it
Paddle offers python APIs to open and close channels, along with sending
and receiving data to/from a channel.
### Create a channel
Creates a new channel that takes in variables of a specific dtype.
-
**fluid.make_channel(dtype, capacity=0)**
-
**dtype**
: The data type of variables being sent/received through channel
-
**capacity**
: The capacity of the channel. A capacity of 0 represents
an unbuffered channel. Capacity > 0 represents a buffered channel
```
ch = fluid.make_channel(dtype=core.VarDesc.VarType.LOD_TENSOR, 10)
```
### Close a channel
Closes a channel. Any pending senders and receivers will be awoken during
this time. Receivers can still receive from a closed channel, but senders
are not allowed to send any additional data to the channel (Paddle will
raise an exception if users try to send to a closed channel.)
-
**fluid.channel_close(channel)**
```
fluid.channel_close(ch)
```
### Send data to a channel
Sends a variable to a channel. Currently, variables of dtype
`LoDTensor`
,
`LoDRankTable`
,
`LoDTensorArray`
,
`SelectedRows`
,
`ReaderHolder`
, and
`ChannelHolder`
are supported.
By default, the data of the Variable is moved from the sender to the receiver,
however the user can optionally copy the data before performing the send.
-
**channel_send(channel, variable, is_copy=False)**
-
**channel**
: The channel to send the variable to
-
**variable**
: The variable to send to the channel
-
**is_copy**
: If set to True, channel_send will perform a variable assign
to copy the source variable to a new variable to be sent.
```
ch = fluid.make_channel(dtype=core.VarDesc.VarType.LOD_TENSOR)
var = fill_constant(shape=[1],dtype=core.VarDesc.VarType.INT32, value=100)
fluid.channel_send(ch, var, True)
```
### Receive data from a channel
Receives a variable from a channel. The data of the variable is moved to the
receiving variable.
-
**channel_recv(channel, return_variable)**
-
**channel**
: The channel to receive the variable from
-
**return_variable**
: The destination variable used to store the data of the
variable received from the channel
```
ch = fluid.make_channel(dtype=core.VarDesc.VarType.LOD_TENSOR)
var = fill_constant(shape=[1],dtype=core.VarDesc.VarType.INT32, value=-1)
fluid.channel_recv(ch, var)
```
## How it Works
Channels provides a simple interface for different threads to share data.
To support the synchronization requirements, channels utilizes a series of
internal queues, locks, and conditional variables.
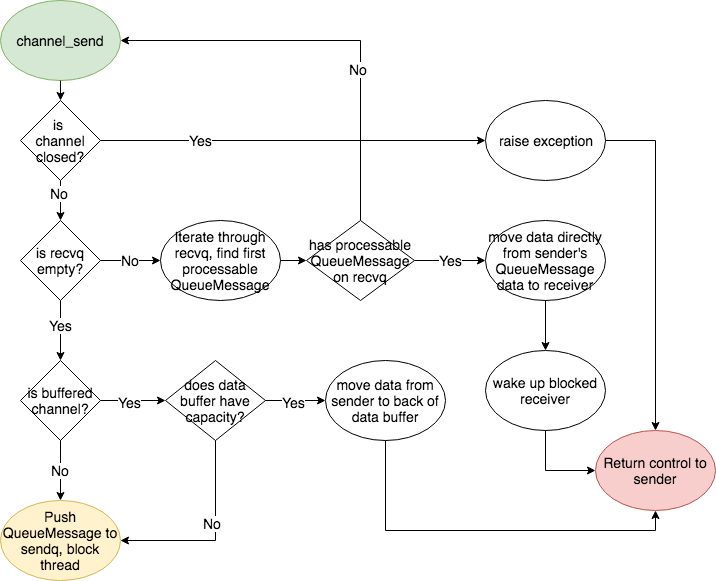
### QueueMessage
QueueMessage encapsulates the state of the channel send/receive operation to be
put in the
**sendq/recvq**
. It contains a condition variable used to lock the
thread (when there are no available sends/receives). In addition, it contains
a callback function to notify a thread when the QueueMessage is being
processed by the channel.
### Queues
-
**buff_**
: This queue holds the data buffer in a buffered channel. The
capacity is set to the capacity of the channel. This data buffer is not
used in an unbuffered channel.
-
**sendq**
: This queue holds the QueueMessage of any pending senders of a
channel. When a thread performs a channel_send operation on the channel, the
channel_send operation will put a new QueueMessage on the sendq and block the
current thread under two conditions:
1.
The channel is buffered and is full
2.
The channel is unbuffered and does not have a receiver
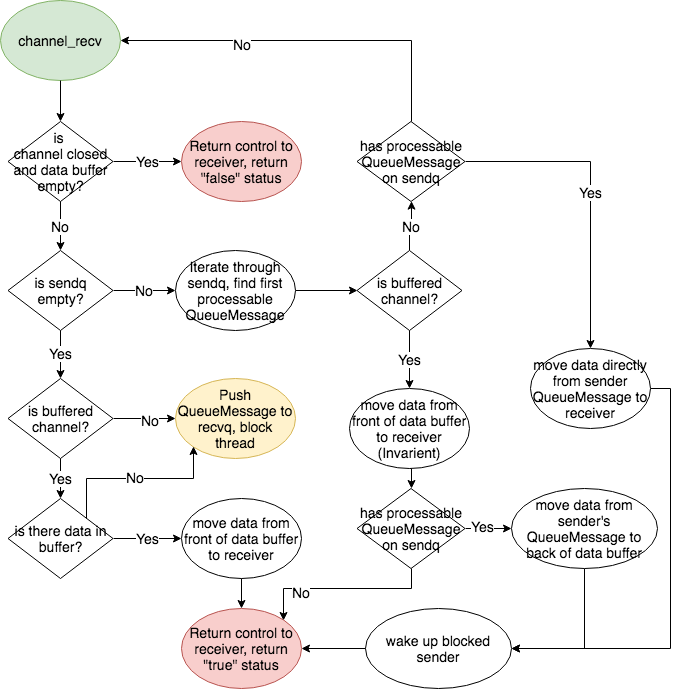
-
**recvq**
: This queue holds the QueueMessage of any pending receivers of a
channel. When a thread performs a channel_recv operation on the channel, the
channel_recv operation will put a new QueueMessage on the recvq and block the
current thread under two conditions:
1.
The channel is buffered and there is no data on the buff_
2.
The channel is unbuffered and does not have a sender
### State diagram
#### Channel Send
<p
align=
"center"
>
<img
src=
"./images/channel_send.png"
/><br/>
</p>
#### Channel Receive
<p
align=
"center"
>
<img
src=
"./images/channel_recv.png"
/><br/>
</p>
## Limitations and Considerations
### Variable Copy
In golang, variables in channels are copied from the sender to the receiver.
In Paddle, the data from our variables are
**moved**
from sender to receiver.
As a result, these variables should not be used after they are sent. We
provide a flag in channel_send method to allow users to copy the variable to
be sent before it is sent.
Please note that this is acheived by adding an
**assign**
operator and creating
a temporary variable that is sent in place of the original variable. Please
note that
**assign**
operator has limited support for only certain variables
datatypes.
doc/fluid/design/concurrent/images/channel_recv.png
0 → 100644
浏览文件 @
96192a85
133.4 KB
doc/fluid/design/concurrent/images/channel_send.png
0 → 100644
浏览文件 @
96192a85
83.6 KB
paddle/fluid/framework/CMakeLists.txt
浏览文件 @
96192a85
...
...
@@ -100,7 +100,7 @@ cc_test(init_test SRCS init_test.cc DEPS init)
cc_test
(
op_kernel_type_test SRCS op_kernel_type_test.cc DEPS place device_context framework_proto
)
cc_test
(
cow_ptr_tests SRCS details/cow_ptr_test.cc
)
cc_test
(
channel_test SRCS channel_test.cc
)
#
cc_test(channel_test SRCS channel_test.cc)
cc_test
(
tuple_test SRCS tuple_test.cc
)
cc_test
(
concurrency_test SRCS concurrency_test.cc DEPS go_op channel_close_op channel_create_op
channel_send_op channel_recv_op sum_op select_op elementwise_add_op compare_op
...
...
paddle/fluid/framework/block_desc.cc
浏览文件 @
96192a85
...
...
@@ -147,15 +147,52 @@ void BlockDesc::RemoveOp(size_t s, size_t e) {
if
(
ops_
.
begin
()
+
s
==
ops_
.
end
()
||
ops_
.
begin
()
+
e
==
ops_
.
end
())
{
return
;
}
auto
get_vars
=
[](
std
::
deque
<
std
::
unique_ptr
<
OpDesc
>>::
iterator
&
op
,
std
::
vector
<
std
::
string
>
&
v
)
{
auto
in_names
=
(
*
op
)
->
InputArgumentNames
();
v
.
insert
(
v
.
end
(),
in_names
.
begin
(),
in_names
.
end
());
auto
out_names
=
(
*
op
)
->
OutputArgumentNames
();
v
.
insert
(
v
.
end
(),
out_names
.
begin
(),
out_names
.
end
());
std
::
sort
(
v
.
begin
(),
v
.
end
());
auto
last
=
std
::
unique
(
v
.
begin
(),
v
.
end
());
v
.
erase
(
last
,
v
.
end
());
};
need_update_
=
true
;
for
(
auto
it
=
ops_
.
begin
()
+
s
;
it
!=
ops_
.
begin
()
+
e
;
it
++
)
{
auto
names
=
(
*
it
)
->
InputArgumentNames
();
for
(
auto
n
:
names
)
{
// TODO(typhoonzero): delete vars if no other op use it.
VLOG
(
3
)
<<
"deleting var "
<<
n
;
for
(
size_t
i
=
s
;
i
<
e
;
i
++
)
{
// since remove op one by one, every time remove the first op.
auto
op
=
ops_
.
begin
()
+
s
;
// collect input and output variables from current delete op
std
::
vector
<
std
::
string
>
cur_vars
;
get_vars
(
op
,
cur_vars
);
// remove current op
ops_
.
erase
(
ops_
.
begin
()
+
s
);
// collect input and output variables from other ops
std
::
vector
<
std
::
string
>
other_vars
;
for
(
auto
it
=
ops_
.
begin
();
it
!=
ops_
.
end
();
it
++
)
{
get_vars
(
it
,
other_vars
);
}
// variables should be deleted
std
::
vector
<
std
::
string
>
delete_vars
;
// delete_vars = cur_vars - cur_vars ^ other_input_vars
std
::
set_difference
(
cur_vars
.
begin
(),
cur_vars
.
end
(),
other_vars
.
begin
(),
other_vars
.
end
(),
std
::
inserter
(
delete_vars
,
delete_vars
.
end
()));
// remove variables
for
(
size_t
i
=
0
;
i
<
delete_vars
.
size
();
i
++
)
{
auto
name
=
delete_vars
[
i
];
auto
it
=
vars_
.
find
(
name
);
PADDLE_ENFORCE
(
it
!=
vars_
.
end
(),
"%s is not in variable list, it should not be deleted"
,
name
);
vars_
.
erase
(
it
);
VLOG
(
3
)
<<
"deleting variable "
<<
name
;
}
}
ops_
.
erase
(
ops_
.
begin
()
+
s
,
ops_
.
begin
()
+
e
);
}
std
::
vector
<
OpDesc
*>
BlockDesc
::
AllOps
()
const
{
...
...
paddle/fluid/framework/block_desc.h
浏览文件 @
96192a85
...
...
@@ -89,6 +89,11 @@ class BlockDesc {
OpDesc
*
InsertOp
(
size_t
index
);
/*
* Remove Op and its input/output variables.
* Note that for either input or ouput variable, if it is also an input or
* output variable of other ops, we should remain it.
*/
void
RemoveOp
(
size_t
s
,
size_t
e
);
std
::
vector
<
OpDesc
*>
AllOps
()
const
;
...
...
paddle/scripts/submit_local.sh.in
浏览文件 @
96192a85
...
...
@@ -153,9 +153,15 @@ if [ $? -ne 0 ]; then
exit
1
fi
INSTALLED_VERSION
=
`
pip freeze 2>/dev/null |
grep
'^paddle'
|
sed
's/.*==//g'
`
if
[
"@WITH_GPU@"
==
"ON"
]
;
then
PADDLE_NAME
=
"paddlepaddle-gpu"
else
PADDLE_NAME
=
"paddlepaddle"
fi
INSTALLED_VERSION
=
`
pip freeze 2>/dev/null |
grep
"^
${
PADDLE_NAME
}
=="
|
sed
's/.*==//g'
`
if
[
-z
${
INSTALLED_VERSION
}
]
;
then
if
[
-z
"
${
INSTALLED_VERSION
}
"
]
;
then
INSTALLED_VERSION
=
"0.0.0"
# not installed
fi
cat
<<
EOF
| python -
...
...
python/paddle/fluid/layer_helper.py
浏览文件 @
96192a85
...
...
@@ -398,7 +398,6 @@ class LayerHelper(object):
return
input_var
if
isinstance
(
act
,
basestring
):
act
=
{
'type'
:
act
}
tmp
=
self
.
create_tmp_variable
(
dtype
=
input_var
.
dtype
)
if
'use_mkldnn'
in
self
.
kwargs
:
act
[
'use_mkldnn'
]
=
self
.
kwargs
.
get
(
'use_mkldnn'
)
...
...
@@ -408,9 +407,9 @@ class LayerHelper(object):
self
.
append_op
(
type
=
act_type
,
inputs
=
{
"X"
:
[
input_var
]},
outputs
=
{
"Out"
:
[
tmp
]},
outputs
=
{
"Out"
:
[
input_var
]},
attrs
=
act
)
return
tmp
return
input_var
def
_get_default_initializer
(
self
,
dtype
):
if
dtype
is
None
or
dtype_is_floating
(
dtype
)
is
True
:
...
...
python/paddle/fluid/layers/nn.py
浏览文件 @
96192a85
...
...
@@ -1483,6 +1483,7 @@ def batch_norm(input,
param_attr
=
None
,
bias_attr
=
None
,
data_layout
=
'NCHW'
,
in_place
=
False
,
name
=
None
,
moving_mean_name
=
None
,
moving_variance_name
=
None
):
...
...
@@ -1538,7 +1539,7 @@ def batch_norm(input,
saved_mean
=
helper
.
create_tmp_variable
(
dtype
=
dtype
,
stop_gradient
=
True
)
saved_variance
=
helper
.
create_tmp_variable
(
dtype
=
dtype
,
stop_gradient
=
True
)
batch_norm_out
=
helper
.
create_tmp_variable
(
dtype
)
batch_norm_out
=
input
if
in_place
else
helper
.
create_tmp_variable
(
dtype
)
helper
.
append_op
(
type
=
"batch_norm"
,
...
...
python/paddle/fluid/nets.py
浏览文件 @
96192a85
...
...
@@ -98,7 +98,7 @@ def img_conv_group(input,
use_mkldnn
=
use_mkldnn
)
if
conv_with_batchnorm
[
i
]:
tmp
=
layers
.
batch_norm
(
input
=
tmp
,
act
=
conv_act
)
tmp
=
layers
.
batch_norm
(
input
=
tmp
,
act
=
conv_act
,
in_place
=
True
)
drop_rate
=
conv_batchnorm_drop_rate
[
i
]
if
abs
(
drop_rate
)
>
1e-5
:
tmp
=
layers
.
dropout
(
x
=
tmp
,
dropout_prob
=
drop_rate
)
...
...
python/paddle/fluid/tests/unittests/test_protobuf_descs.py
浏览文件 @
96192a85
...
...
@@ -186,6 +186,34 @@ class TestBlockDesc(unittest.TestCase):
all_ops
.
append
(
block
.
op
(
idx
))
self
.
assertEqual
(
all_ops
,
[
op0
,
op1
,
op2
])
def
test_remove_op
(
self
):
prog
=
core
.
ProgramDesc
()
self
.
assertIsNotNone
(
prog
)
block
=
prog
.
block
(
0
)
self
.
assertIsNotNone
(
block
)
op1
=
block
.
append_op
()
op2
=
block
.
append_op
()
var1
=
block
.
var
(
"var1"
)
var2
=
block
.
var
(
"var2"
)
var3
=
block
.
var
(
"var3"
)
var4
=
block
.
var
(
"var4"
)
var5
=
block
.
var
(
"var5"
)
op1
.
set_input
(
"X"
,
[
"var1"
,
"var2"
])
op1
.
set_output
(
"Y"
,
[
"var3"
,
"var4"
])
op2
.
set_input
(
"X"
,
[
"var1"
])
op2
.
set_output
(
"Y"
,
[
"var4"
,
"var5"
])
# remove op1, its input var2 and output var3 will be removed at the same time,
# but its input var1 and output var4 will not be removed since they are used for op2.
block
.
remove_op
(
0
,
1
)
all_ops
=
[]
for
idx
in
xrange
(
0
,
block
.
op_size
()):
all_ops
.
append
(
block
.
op
(
idx
))
self
.
assertEqual
(
all_ops
,
[
op2
])
all_vars
=
block
.
all_vars
()
self
.
assertEqual
(
set
(
all_vars
),
{
var1
,
var4
,
var5
})
if
__name__
==
'__main__'
:
unittest
.
main
()
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}