[cherry-pick]add rcnn model doc. (#710)
* Add rcnn model doc.
Showing
configs/gcnet/README_cn.md
0 → 100644
configs/iou_loss/README_cn.md
0 → 100644
configs/libra_rcnn/README_cn.md
0 → 100644
{kind=link}
78.0 KB
{kind=link}
97.5 KB
{kind=link}
60.5 KB
{kind=link}
19.9 KB
{kind=link}
18.7 KB
{kind=link}
6.8 KB
{kind=link}
18.7 KB
{kind=link}
10.3 KB
{kind=link}
8.7 KB
{kind=link}
7.9 KB
{kind=link}
19.1 KB
{kind=link}

77.4 KB
{kind=link}

207.0 KB
{kind=link}
99.4 KB
{kind=link}
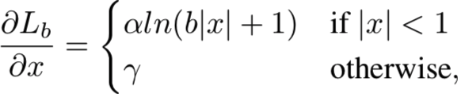
16.7 KB
{kind=link}
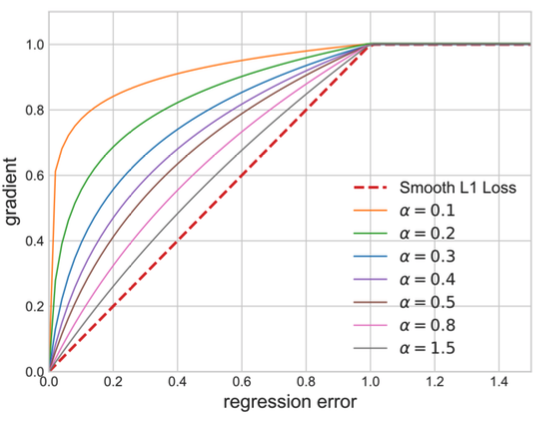
112.7 KB
{kind=link}
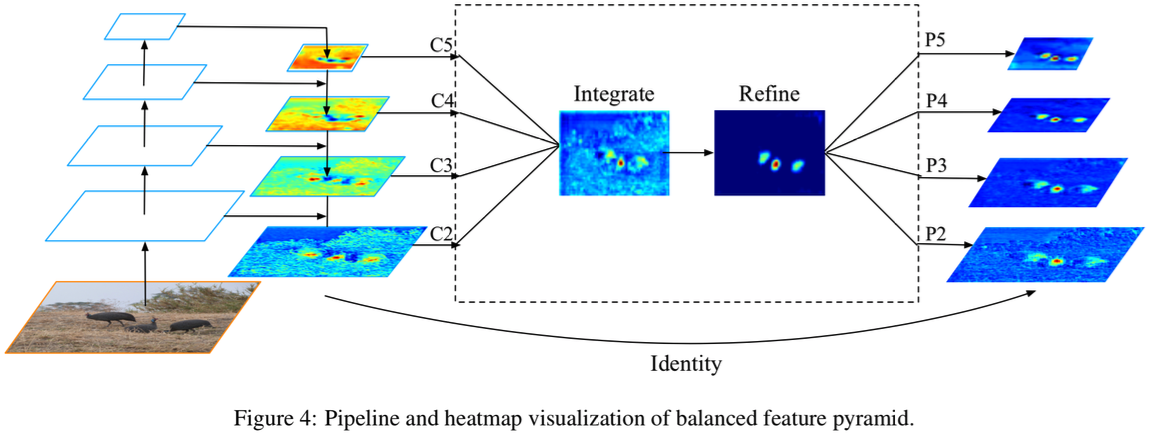
260.9 KB
{kind=link}
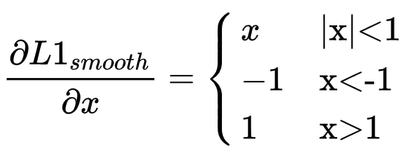
19.6 KB