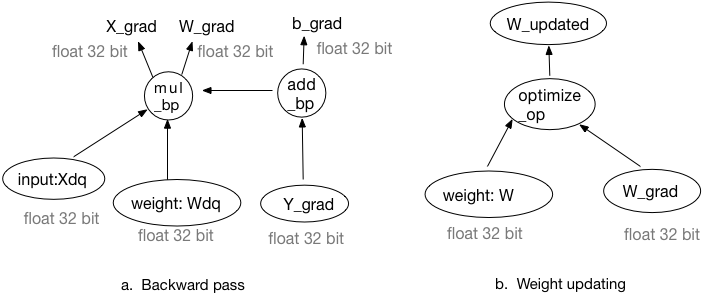
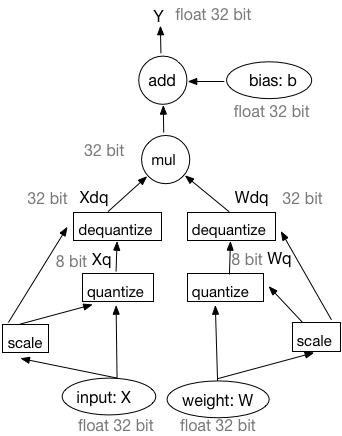
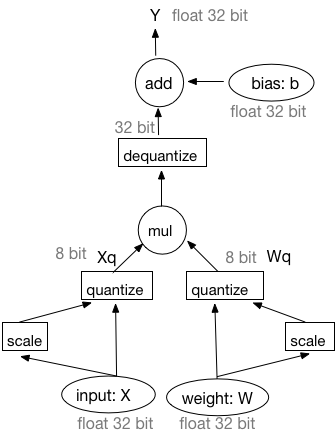
Design doc of fixed-point quantization. (#10553)
* Design doc of fixed-point quantization. * Update fixed point quantization desigin doc. * Fix doc format. * Update the backward part. * Fix the grammatical.
Showing
{kind=link}
41.5 KB
{kind=link}
32.2 KB
{kind=link}
27.3 KB