Merge remote-tracking branch 'upstream/develop' into merge_grad_gtest
Showing
{kind=link}
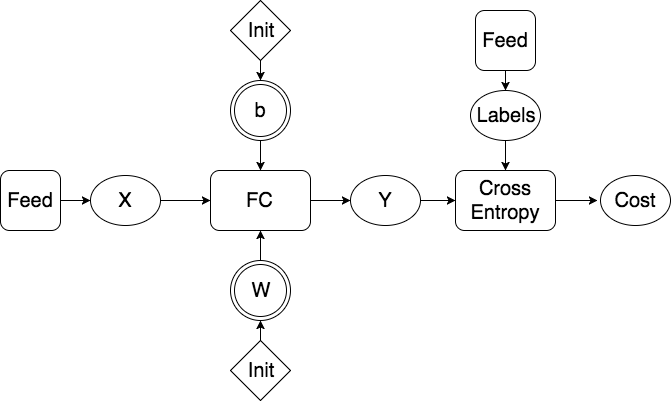
31.5 KB
{kind=link}
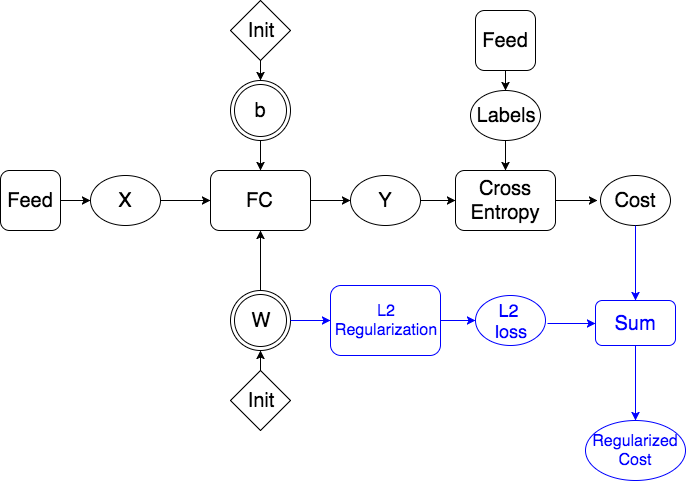
45.0 KB
{kind=link}
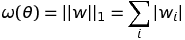
1.1 KB
{kind=link}
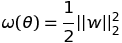
989 字节
{kind=link}
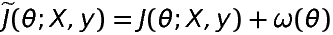
1.6 KB
doc/design/prune.md
0 → 100644
doc/design/regularization.md
0 → 100644
{kind=link}
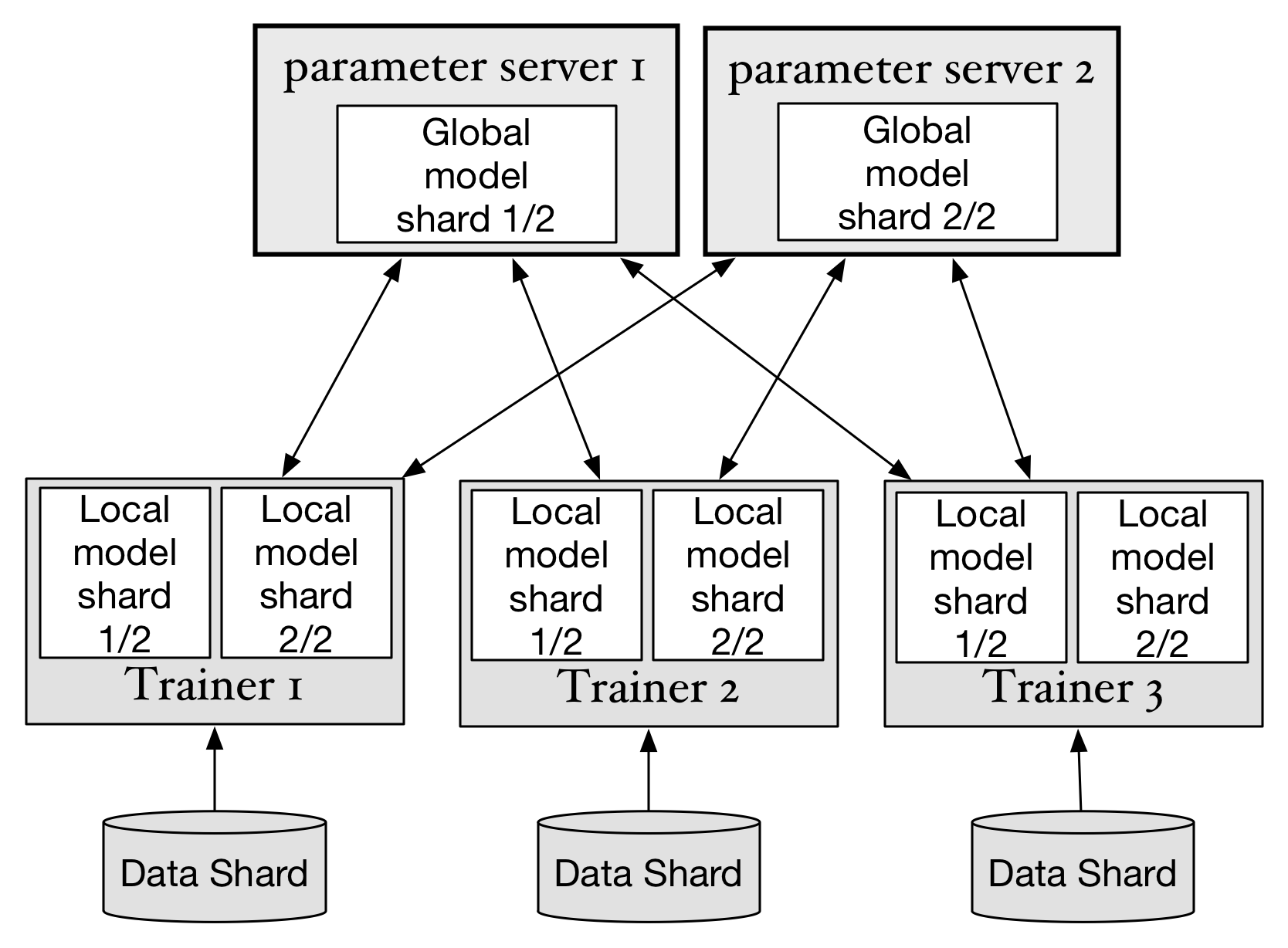
141.7 KB
{kind=link}
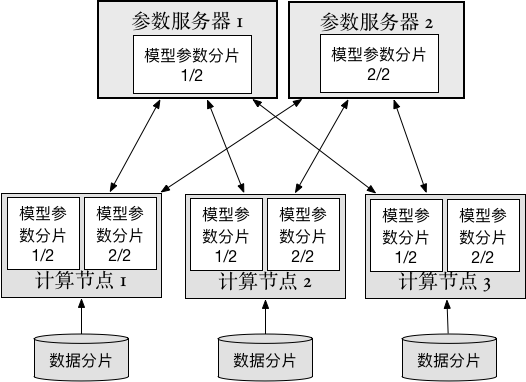
33.1 KB
paddle/framework/prune.cc
0 → 100644
paddle/framework/prune.h
0 → 100644
paddle/framework/prune_test.cc
0 → 100644
paddle/operators/batch_norm_op.md
0 → 100644
{kind=link}
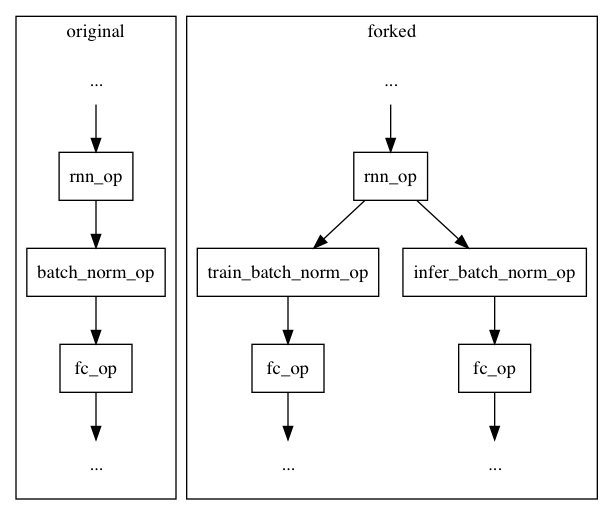
23.3 KB
{kind=link}

161.3 KB
paddle/operators/math/matmul.h
0 → 100644
paddle/operators/matmul_op.cc
0 → 100644
paddle/operators/matmul_op.cu
0 → 100644
paddle/operators/matmul_op.h
0 → 100644
paddle/operators/momentum_op.cc
0 → 100644
paddle/operators/momentum_op.cu
0 → 100644
paddle/operators/momentum_op.h
0 → 100644
此差异已折叠。
paddle/operators/proximal_gd_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。