Merge branch 'develop' of upstream into profiler_tool
Showing
{kind=link}
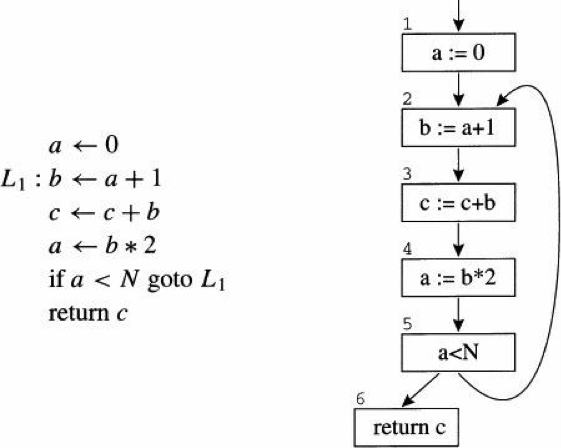
83.3 KB
{kind=link}
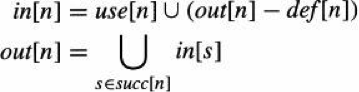
22.5 KB
{kind=link}
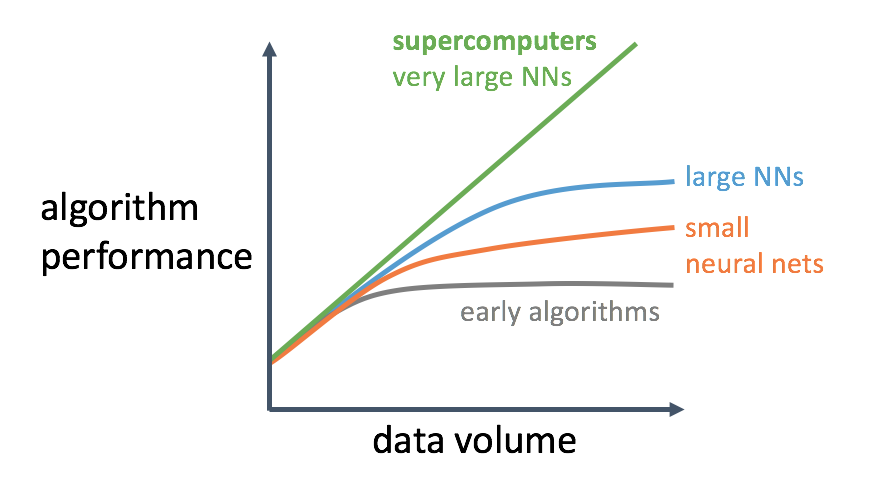
39.7 KB
doc/design/memory_optimization.md
0 → 100644
paddle/inference/CMakeLists.txt
0 → 100644
paddle/inference/example.cc
0 → 100644
paddle/inference/inference.cc
0 → 100644
paddle/inference/inference.h
0 → 100644