Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleDetection
提交
2f6f46a4
P
PaddleDetection
项目概览
PaddlePaddle
/
PaddleDetection
大约 2 年 前同步成功
通知
708
Star
11112
Fork
2696
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
184
列表
看板
标记
里程碑
合并请求
40
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleDetection
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
184
Issue
184
列表
看板
标记
里程碑
合并请求
40
合并请求
40
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
2f6f46a4
编写于
2月 21, 2021
作者:
C
cnn
提交者:
GitHub
2月 21, 2021
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
[cherry-pick] Fix deploy python/cpp infer bugs (#2242)
* cherry-pick #2234, test=dygraph
上级
5de081f6
变更
10
隐藏空白更改
内联
并排
Showing
10 changed file
with
38 addition
and
87 deletion
+38
-87
.travis.yml
.travis.yml
+1
-1
dygraph/deploy/cpp/docs/windows_vs2019_build.md
dygraph/deploy/cpp/docs/windows_vs2019_build.md
+9
-33
dygraph/deploy/cpp/include/preprocess_op.h
dygraph/deploy/cpp/include/preprocess_op.h
+7
-6
dygraph/deploy/cpp/scripts/build.sh
dygraph/deploy/cpp/scripts/build.sh
+0
-1
dygraph/deploy/cpp/src/object_detector.cc
dygraph/deploy/cpp/src/object_detector.cc
+1
-1
dygraph/deploy/cpp/src/preprocess_op.cc
dygraph/deploy/cpp/src/preprocess_op.cc
+6
-20
dygraph/deploy/python/preprocess.py
dygraph/deploy/python/preprocess.py
+7
-9
dygraph/ppdet/engine/export_utils.py
dygraph/ppdet/engine/export_utils.py
+3
-8
dygraph/ppdet/engine/trainer.py
dygraph/ppdet/engine/trainer.py
+2
-1
dygraph/ppdet/modeling/architectures/ssd.py
dygraph/ppdet/modeling/architectures/ssd.py
+2
-7
未找到文件。
.travis.yml
浏览文件 @
2f6f46a4
...
@@ -20,7 +20,7 @@ addons:
...
@@ -20,7 +20,7 @@ addons:
before_install
:
before_install
:
-
sudo pip install -U virtualenv pre-commit pip
-
sudo pip install -U virtualenv pre-commit pip
-
docker pull paddlepaddle/paddle:latest
-
docker pull paddlepaddle/paddle:latest
-
git pull https://github.com/PaddlePaddle/PaddleDetection
master
-
git pull https://github.com/PaddlePaddle/PaddleDetection
release/2.0-rc
script
:
script
:
-
exit_code=0
-
exit_code=0
...
...
dygraph/deploy/cpp/docs/windows_vs2019_build.md
浏览文件 @
2f6f46a4
...
@@ -47,24 +47,14 @@ fluid_inference
...
@@ -47,24 +47,14 @@ fluid_inference
### Step4: 编译
### Step4: 编译
#### 通过图形化操作编译CMake
1.
进入到
`cpp`
文件夹
```
1.
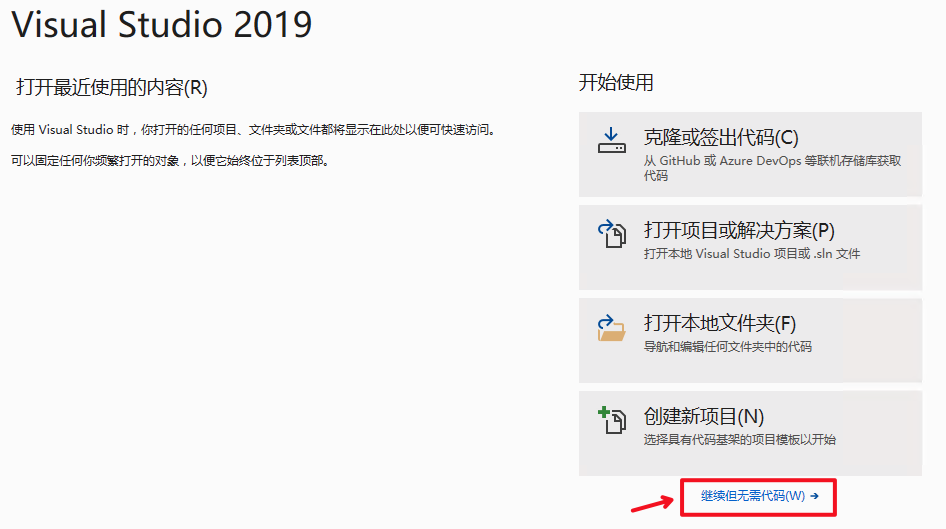
打开Visual Studio 2019 Community,点击
`继续但无需代码`
cd D:\projects\PaddleDetection\deploy\cpp
```
2.
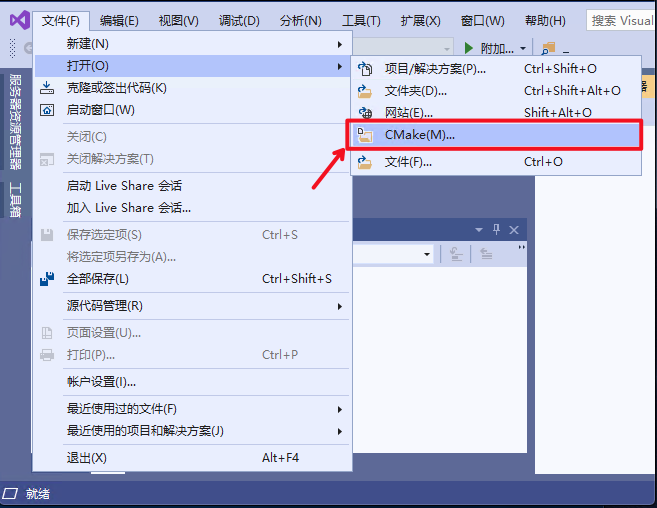
点击:
`文件`
->
`打开`
->
`CMake`
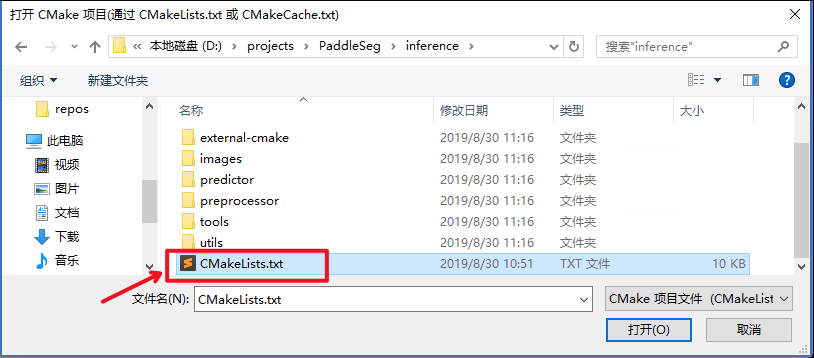
选择项目代码所在路径,并打开
`CMakeList.txt`
:
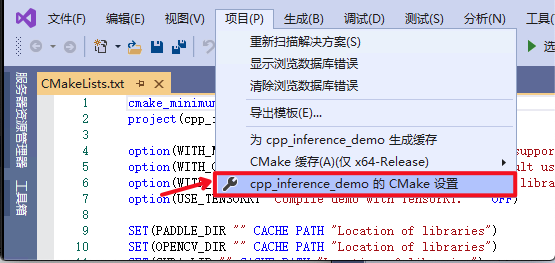
3.
点击:
`项目`
->
`cpp_inference_demo的CMake设置`
4.
点击
`浏览`
,分别设置编译选项指定
`CUDA`
、
`CUDNN_LIB`
、
`OpenCV`
、
`Paddle预测库`
的路径
2.
使用CMake生成项目文件
三个
编译参数的含义说明如下(带
*表示仅在使用**GPU版本**预测库时指定, 其中CUDA库版本尽量对齐,**使用9.0、10.0版本,不使用9.2、10.1等版本CUDA库*
*
):
编译参数的含义说明如下(带
*表示仅在使用**GPU版本**预测库时指定, 其中CUDA库版本尽量对齐,**使用9.0、10.0版本,不使用9.2、10.1等版本CUDA库*
*
):
| 参数名 | 含义 |
| 参数名 | 含义 |
| ---- | ---- |
| ---- | ---- |
...
@@ -75,23 +65,8 @@ fluid_inference
...
@@ -75,23 +65,8 @@ fluid_inference
| USE_PADDLE_20RC1 | 是否使用2.0rc1预测库。如果使用2.0rc1,在windows环境下预测库名称发生变化,且仅支持动态库方式编译 |
| USE_PADDLE_20RC1 | 是否使用2.0rc1预测库。如果使用2.0rc1,在windows环境下预测库名称发生变化,且仅支持动态库方式编译 |
**注意:**
1. 使用
`CPU`
版预测库,请把
`WITH_GPU`
的勾去掉 2. 如果使用的是
`openblas`
版本,请把
`WITH_MKL`
勾去掉
**注意:**
1. 使用
`CPU`
版预测库,请把
`WITH_GPU`
的勾去掉 2. 如果使用的是
`openblas`
版本,请把
`WITH_MKL`
勾去掉
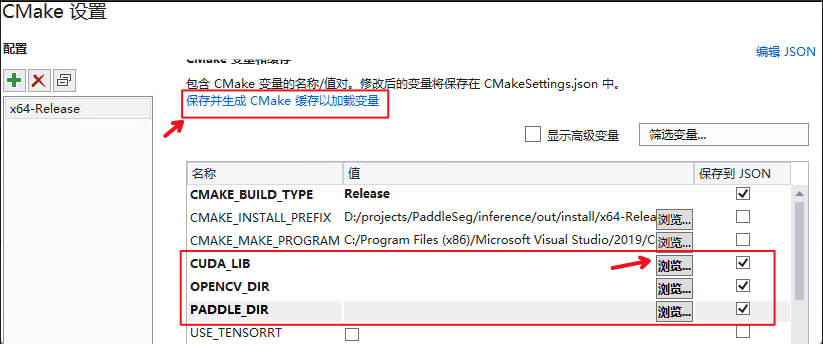
**设置完成后**
, 点击上图中
`保存并生成CMake缓存以加载变量`
。
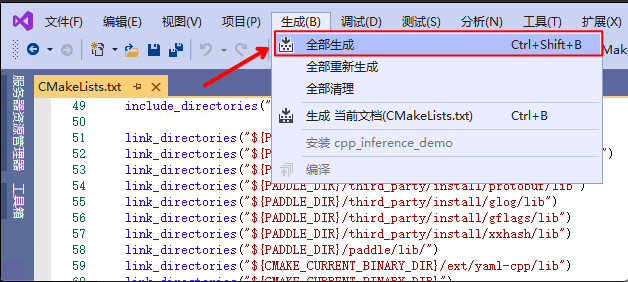
5.
点击
`生成`
->
`全部生成`
执行如下命令项目文件:
#### 通过命令行操作编译CMake
1.
进入到
`cpp`
文件夹
```
cd D:\projects\PaddleDetection\deploy\cpp
```
2.
使用CMake生成项目文件
```
```
cmake . -G "Visual Studio 16 2019" -A x64 -T host=x64 -DWITH_GPU=ON -DWITH_MKL=ON -DCMAKE_BUILD_TYPE=Release -DCUDA_LIB=path_to_cuda_lib -DCUDNN_LIB=path_to_cudnn_lib -DPADDLE_DIR=path_to_paddle_lib -DOPENCV_DIR=path_to_opencv
cmake . -G "Visual Studio 16 2019" -A x64 -T host=x64 -DWITH_GPU=ON -DWITH_MKL=ON -DCMAKE_BUILD_TYPE=Release -DCUDA_LIB=path_to_cuda_lib -DCUDNN_LIB=path_to_cudnn_lib -DPADDLE_DIR=path_to_paddle_lib -DOPENCV_DIR=path_to_opencv
```
```
...
@@ -102,7 +77,8 @@ cmake . -G "Visual Studio 16 2019" -A x64 -T host=x64 -DWITH_GPU=ON -DWITH_MKL=O
...
@@ -102,7 +77,8 @@ cmake . -G "Visual Studio 16 2019" -A x64 -T host=x64 -DWITH_GPU=ON -DWITH_MKL=O
```
```
3.
编译
3.
编译
用
`Visual Studio 16 2019`
打开
`cpp`
文件夹下的
`PaddleObjectDetector.sln`
,点击
`生成`
->
`全部生成`
用
`Visual Studio 16 2019`
打开
`cpp`
文件夹下的
`PaddleObjectDetector.sln`
,将编译模式设置为
`Release`
,点击
`生成`
->
`全部生成
### Step5: 预测及可视化
### Step5: 预测及可视化
...
...
dygraph/deploy/cpp/include/preprocess_op.h
浏览文件 @
2f6f46a4
...
@@ -58,7 +58,7 @@ class InitInfo : public PreprocessOp{
...
@@ -58,7 +58,7 @@ class InitInfo : public PreprocessOp{
virtual
void
Run
(
cv
::
Mat
*
im
,
ImageBlob
*
data
);
virtual
void
Run
(
cv
::
Mat
*
im
,
ImageBlob
*
data
);
};
};
class
Normalize
:
public
PreprocessOp
{
class
Normalize
Image
:
public
PreprocessOp
{
public:
public:
virtual
void
Init
(
const
YAML
::
Node
&
item
,
const
std
::
vector
<
int
>
image_shape
)
{
virtual
void
Init
(
const
YAML
::
Node
&
item
,
const
std
::
vector
<
int
>
image_shape
)
{
mean_
=
item
[
"mean"
].
as
<
std
::
vector
<
float
>>
();
mean_
=
item
[
"mean"
].
as
<
std
::
vector
<
float
>>
();
...
@@ -133,13 +133,14 @@ class Preprocessor {
...
@@ -133,13 +133,14 @@ class Preprocessor {
}
}
std
::
shared_ptr
<
PreprocessOp
>
CreateOp
(
const
std
::
string
&
name
)
{
std
::
shared_ptr
<
PreprocessOp
>
CreateOp
(
const
std
::
string
&
name
)
{
if
(
name
==
"Resize
Op
"
)
{
if
(
name
==
"Resize"
)
{
return
std
::
make_shared
<
Resize
>
();
return
std
::
make_shared
<
Resize
>
();
}
else
if
(
name
==
"Permute
Op
"
)
{
}
else
if
(
name
==
"Permute"
)
{
return
std
::
make_shared
<
Permute
>
();
return
std
::
make_shared
<
Permute
>
();
}
else
if
(
name
==
"NormalizeImageOp"
)
{
}
else
if
(
name
==
"NormalizeImage"
)
{
return
std
::
make_shared
<
Normalize
>
();
return
std
::
make_shared
<
NormalizeImage
>
();
}
else
if
(
name
==
"PadBatchOp"
||
name
==
"PadStride"
)
{
}
else
if
(
name
==
"PadStride"
)
{
// use PadStride instead of PadBatch
return
std
::
make_shared
<
PadStride
>
();
return
std
::
make_shared
<
PadStride
>
();
}
}
std
::
cerr
<<
"can not find function of OP: "
<<
name
<<
" and return: nullptr"
<<
std
::
endl
;
std
::
cerr
<<
"can not find function of OP: "
<<
name
<<
" and return: nullptr"
<<
std
::
endl
;
...
...
dygraph/deploy/cpp/scripts/build.sh
浏览文件 @
2f6f46a4
...
@@ -69,7 +69,6 @@ cmake .. \
...
@@ -69,7 +69,6 @@ cmake .. \
-DTENSORRT_LIB_DIR
=
${
TENSORRT_LIB_DIR
}
\
-DTENSORRT_LIB_DIR
=
${
TENSORRT_LIB_DIR
}
\
-DTENSORRT_INC_DIR
=
${
TENSORRT_INC_DIR
}
\
-DTENSORRT_INC_DIR
=
${
TENSORRT_INC_DIR
}
\
-DPADDLE_DIR
=
${
PADDLE_DIR
}
\
-DPADDLE_DIR
=
${
PADDLE_DIR
}
\
-DWITH_STATIC_LIB
=
${
WITH_STATIC_LIB
}
\
-DCUDA_LIB
=
${
CUDA_LIB
}
\
-DCUDA_LIB
=
${
CUDA_LIB
}
\
-DCUDNN_LIB
=
${
CUDNN_LIB
}
\
-DCUDNN_LIB
=
${
CUDNN_LIB
}
\
-DOPENCV_DIR
=
${
OPENCV_DIR
}
-DOPENCV_DIR
=
${
OPENCV_DIR
}
...
...
dygraph/deploy/cpp/src/object_detector.cc
浏览文件 @
2f6f46a4
...
@@ -131,7 +131,7 @@ void ObjectDetector::Postprocess(
...
@@ -131,7 +131,7 @@ void ObjectDetector::Postprocess(
result
->
clear
();
result
->
clear
();
int
rh
=
1
;
int
rh
=
1
;
int
rw
=
1
;
int
rw
=
1
;
if
(
config_
.
arch_
==
"
SSD"
||
config_
.
arch_
==
"
Face"
)
{
if
(
config_
.
arch_
==
"Face"
)
{
rh
=
raw_mat
.
rows
;
rh
=
raw_mat
.
rows
;
rw
=
raw_mat
.
cols
;
rw
=
raw_mat
.
cols
;
}
}
...
...
dygraph/deploy/cpp/src/preprocess_op.cc
浏览文件 @
2f6f46a4
...
@@ -31,7 +31,7 @@ void InitInfo::Run(cv::Mat* im, ImageBlob* data) {
...
@@ -31,7 +31,7 @@ void InitInfo::Run(cv::Mat* im, ImageBlob* data) {
};
};
}
}
void
Normalize
::
Run
(
cv
::
Mat
*
im
,
ImageBlob
*
data
)
{
void
Normalize
Image
::
Run
(
cv
::
Mat
*
im
,
ImageBlob
*
data
)
{
double
e
=
1.0
;
double
e
=
1.0
;
if
(
is_scale_
)
{
if
(
is_scale_
)
{
e
/=
255.0
;
e
/=
255.0
;
...
@@ -62,6 +62,10 @@ void Permute::Run(cv::Mat* im, ImageBlob* data) {
...
@@ -62,6 +62,10 @@ void Permute::Run(cv::Mat* im, ImageBlob* data) {
void
Resize
::
Run
(
cv
::
Mat
*
im
,
ImageBlob
*
data
)
{
void
Resize
::
Run
(
cv
::
Mat
*
im
,
ImageBlob
*
data
)
{
auto
resize_scale
=
GenerateScale
(
*
im
);
auto
resize_scale
=
GenerateScale
(
*
im
);
data
->
input_shape_
=
{
static_cast
<
int
>
(
im
->
cols
*
resize_scale
.
first
),
static_cast
<
int
>
(
im
->
rows
*
resize_scale
.
second
)
};
cv
::
resize
(
cv
::
resize
(
*
im
,
*
im
,
cv
::
Size
(),
resize_scale
.
first
,
resize_scale
.
second
,
interp_
);
*
im
,
*
im
,
cv
::
Size
(),
resize_scale
.
first
,
resize_scale
.
second
,
interp_
);
data
->
im_shape_
=
{
data
->
im_shape_
=
{
...
@@ -72,24 +76,6 @@ void Resize::Run(cv::Mat* im, ImageBlob* data) {
...
@@ -72,24 +76,6 @@ void Resize::Run(cv::Mat* im, ImageBlob* data) {
resize_scale
.
second
,
resize_scale
.
second
,
resize_scale
.
first
,
resize_scale
.
first
,
};
};
if
(
keep_ratio_
)
{
int
max_size
=
input_shape_
[
1
];
// Padding the image with 0 border
cv
::
copyMakeBorder
(
*
im
,
*
im
,
0
,
max_size
-
im
->
rows
,
0
,
max_size
-
im
->
cols
,
cv
::
BORDER_CONSTANT
,
cv
::
Scalar
(
0
));
}
data
->
input_shape_
=
{
static_cast
<
int
>
(
im
->
rows
),
static_cast
<
int
>
(
im
->
cols
),
};
}
}
std
::
pair
<
float
,
float
>
Resize
::
GenerateScale
(
const
cv
::
Mat
&
im
)
{
std
::
pair
<
float
,
float
>
Resize
::
GenerateScale
(
const
cv
::
Mat
&
im
)
{
...
@@ -145,7 +131,7 @@ void PadStride::Run(cv::Mat* im, ImageBlob* data) {
...
@@ -145,7 +131,7 @@ void PadStride::Run(cv::Mat* im, ImageBlob* data) {
// Preprocessor op running order
// Preprocessor op running order
const
std
::
vector
<
std
::
string
>
Preprocessor
::
RUN_ORDER
=
{
const
std
::
vector
<
std
::
string
>
Preprocessor
::
RUN_ORDER
=
{
"InitInfo"
,
"Resize
Op"
,
"NormalizeImageOp"
,
"PadStrideOp"
,
"PermuteOp
"
"InitInfo"
,
"Resize
"
,
"NormalizeImage"
,
"PadStride"
,
"Permute
"
};
};
void
Preprocessor
::
Run
(
cv
::
Mat
*
im
,
ImageBlob
*
data
)
{
void
Preprocessor
::
Run
(
cv
::
Mat
*
im
,
ImageBlob
*
data
)
{
...
...
dygraph/deploy/python/preprocess.py
浏览文件 @
2f6f46a4
...
@@ -35,6 +35,7 @@ def decode_image(im_file, im_info):
...
@@ -35,6 +35,7 @@ def decode_image(im_file, im_info):
else
:
else
:
im
=
im_file
im
=
im_file
im_info
[
'im_shape'
]
=
np
.
array
(
im
.
shape
[:
2
],
dtype
=
np
.
float32
)
im_info
[
'im_shape'
]
=
np
.
array
(
im
.
shape
[:
2
],
dtype
=
np
.
float32
)
im_info
[
'scale_factor'
]
=
np
.
array
([
1.
,
1.
],
dtype
=
np
.
float32
)
return
im
,
im_info
return
im
,
im_info
...
@@ -66,8 +67,13 @@ class Resize(object):
...
@@ -66,8 +67,13 @@ class Resize(object):
im (np.ndarray): processed image (np.ndarray)
im (np.ndarray): processed image (np.ndarray)
im_info (dict): info of processed image
im_info (dict): info of processed image
"""
"""
assert
len
(
self
.
target_size
)
==
2
assert
self
.
target_size
[
0
]
>
0
and
self
.
target_size
[
1
]
>
0
im_channel
=
im
.
shape
[
2
]
im_channel
=
im
.
shape
[
2
]
im_scale_y
,
im_scale_x
=
self
.
generate_scale
(
im
)
im_scale_y
,
im_scale_x
=
self
.
generate_scale
(
im
)
# set image_shape
im_info
[
'input_shape'
][
1
]
=
int
(
im_scale_y
*
im
.
shape
[
0
])
im_info
[
'input_shape'
][
2
]
=
int
(
im_scale_x
*
im
.
shape
[
1
])
im
=
cv2
.
resize
(
im
=
cv2
.
resize
(
im
,
im
,
None
,
None
,
...
@@ -78,14 +84,6 @@ class Resize(object):
...
@@ -78,14 +84,6 @@ class Resize(object):
im_info
[
'im_shape'
]
=
np
.
array
(
im
.
shape
[:
2
]).
astype
(
'float32'
)
im_info
[
'im_shape'
]
=
np
.
array
(
im
.
shape
[:
2
]).
astype
(
'float32'
)
im_info
[
'scale_factor'
]
=
np
.
array
(
im_info
[
'scale_factor'
]
=
np
.
array
(
[
im_scale_y
,
im_scale_x
]).
astype
(
'float32'
)
[
im_scale_y
,
im_scale_x
]).
astype
(
'float32'
)
# padding im when image_shape fixed by infer_cfg.yml
if
self
.
keep_ratio
and
im_info
[
'input_shape'
][
1
]
is
not
None
:
max_size
=
im_info
[
'input_shape'
][
1
]
padding_im
=
np
.
zeros
(
(
max_size
,
max_size
,
im_channel
),
dtype
=
np
.
float32
)
im_h
,
im_w
=
im
.
shape
[:
2
]
padding_im
[:
im_h
,
:
im_w
,
:]
=
im
im
=
padding_im
return
im
,
im_info
return
im
,
im_info
def
generate_scale
(
self
,
im
):
def
generate_scale
(
self
,
im
):
...
@@ -174,7 +172,7 @@ class Permute(object):
...
@@ -174,7 +172,7 @@ class Permute(object):
class
PadStride
(
object
):
class
PadStride
(
object
):
""" padding image for model with FPN
""" padding image for model with FPN
, instead PadBatch(pad_to_stride, pad_gt) in original config
Args:
Args:
stride (bool): model with FPN need image shape % stride == 0
stride (bool): model with FPN need image shape % stride == 0
"""
"""
...
...
dygraph/ppdet/engine/export_utils.py
浏览文件 @
2f6f46a4
...
@@ -52,12 +52,6 @@ def _parse_reader(reader_cfg, dataset_cfg, metric, arch, image_shape):
...
@@ -52,12 +52,6 @@ def _parse_reader(reader_cfg, dataset_cfg, metric, arch, image_shape):
for
st
in
sample_transforms
[
1
:]:
for
st
in
sample_transforms
[
1
:]:
for
key
,
value
in
st
.
items
():
for
key
,
value
in
st
.
items
():
p
=
{
'type'
:
key
}
p
=
{
'type'
:
key
}
if
key
==
'Resize'
:
if
value
.
get
(
'keep_ratio'
,
False
)
and
image_shape
[
1
]
is
not
None
:
max_size
=
max
(
image_shape
[
1
:])
image_shape
=
[
3
,
max_size
,
max_size
]
value
[
'target_size'
]
=
image_shape
[
1
:]
p
.
update
(
value
)
p
.
update
(
value
)
preprocess_list
.
append
(
p
)
preprocess_list
.
append
(
p
)
batch_transforms
=
reader_cfg
.
get
(
'batch_transforms'
,
None
)
batch_transforms
=
reader_cfg
.
get
(
'batch_transforms'
,
None
)
...
@@ -65,9 +59,10 @@ def _parse_reader(reader_cfg, dataset_cfg, metric, arch, image_shape):
...
@@ -65,9 +59,10 @@ def _parse_reader(reader_cfg, dataset_cfg, metric, arch, image_shape):
methods
=
[
list
(
bt
.
keys
())[
0
]
for
bt
in
batch_transforms
]
methods
=
[
list
(
bt
.
keys
())[
0
]
for
bt
in
batch_transforms
]
for
bt
in
batch_transforms
:
for
bt
in
batch_transforms
:
for
key
,
value
in
bt
.
items
():
for
key
,
value
in
bt
.
items
():
# for deploy/infer, use PadStride(stride) instead PadBatch(pad_to_stride, pad_gt)
if
key
==
'PadBatch'
:
if
key
==
'PadBatch'
:
preprocess_list
.
append
({
'type'
:
'PadStride'
})
preprocess_list
.
append
({
preprocess_list
[
-
1
].
update
({
'type'
:
'PadStride'
,
'stride'
:
value
[
'pad_to_stride'
]
'stride'
:
value
[
'pad_to_stride'
]
})
})
break
break
...
...
dygraph/ppdet/engine/trainer.py
浏览文件 @
2f6f46a4
...
@@ -340,8 +340,9 @@ class Trainer(object):
...
@@ -340,8 +340,9 @@ class Trainer(object):
if
'inputs_def'
in
self
.
cfg
[
'TestReader'
]:
if
'inputs_def'
in
self
.
cfg
[
'TestReader'
]:
inputs_def
=
self
.
cfg
[
'TestReader'
][
'inputs_def'
]
inputs_def
=
self
.
cfg
[
'TestReader'
][
'inputs_def'
]
image_shape
=
inputs_def
.
get
(
'image_shape'
,
None
)
image_shape
=
inputs_def
.
get
(
'image_shape'
,
None
)
# set image_shape=[3, -1, -1] as default
if
image_shape
is
None
:
if
image_shape
is
None
:
image_shape
=
[
3
,
None
,
None
]
image_shape
=
[
3
,
-
1
,
-
1
]
self
.
model
.
eval
()
self
.
model
.
eval
()
...
...
dygraph/ppdet/modeling/architectures/ssd.py
浏览文件 @
2f6f46a4
...
@@ -54,13 +54,8 @@ class SSD(BaseArch):
...
@@ -54,13 +54,8 @@ class SSD(BaseArch):
def
get_pred
(
self
):
def
get_pred
(
self
):
bbox_pred
,
bbox_num
=
self
.
_forward
()
bbox_pred
,
bbox_num
=
self
.
_forward
()
label
=
bbox_pred
[:,
0
]
score
=
bbox_pred
[:,
1
]
bbox
=
bbox_pred
[:,
2
:]
output
=
{
output
=
{
'bbox'
:
bbox
,
"bbox"
:
bbox_pred
,
'score'
:
score
,
"bbox_num"
:
bbox_num
,
'label'
:
label
,
'bbox_num'
:
bbox_num
}
}
return
output
return
output
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录