Merge branch 'develop' of github.com:PaddlePaddle/Paddle into hsigmoid_op
Showing
{kind=link}
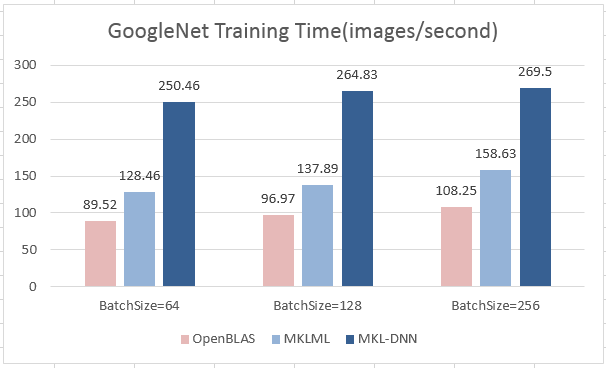
17.8 KB
{kind=link}
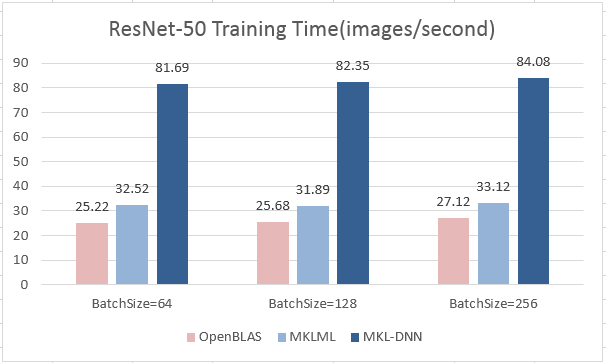
19.8 KB
benchmark/figs/vgg-cpu-train.png
0 → 100644
{kind=link}
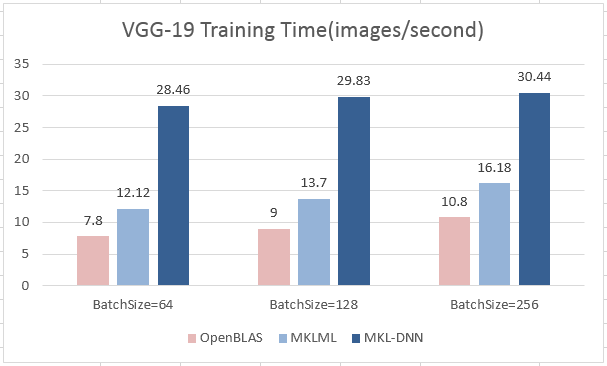
17.9 KB
cmake/external/cares.cmake
0 → 100644
cmake/external/grpc.cmake
0 → 100644
doc/api/v2/fluid.rst
0 → 100644
doc/api/v2/fluid/data_feeder.rst
0 → 100644
doc/api/v2/fluid/evaluator.rst
0 → 100644
doc/api/v2/fluid/executor.rst
0 → 100644
doc/api/v2/fluid/initializer.rst
0 → 100644
doc/api/v2/fluid/layers.rst
0 → 100644
doc/api/v2/fluid/nets.rst
0 → 100644
doc/api/v2/fluid/optimizer.rst
0 → 100644
doc/api/v2/fluid/param_attr.rst
0 → 100644
doc/api/v2/fluid/profiler.rst
0 → 100644
doc/api/v2/fluid/regularizer.rst
0 → 100644
doc/design/fluid-compiler.graffle
0 → 100644
文件已添加
doc/design/fluid-compiler.png
0 → 100644
{kind=link}

121.2 KB
doc/design/fluid.md
0 → 100644
{kind=link}
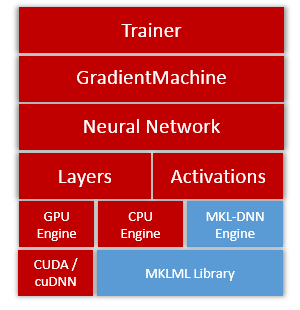
13.3 KB
{kind=link}
22.4 KB
{kind=link}
11.4 KB
{kind=link}
18.0 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
doc/design/support_new_device.md
0 → 100644
doc/howto/dev/write_docs_en.rst
0 → 100644
doc/howto/read_source.md
0 → 100644
paddle/capi/error.cpp
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/math/float16.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/math/tests/test_float16.cu
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/fill_op.cc
0 → 100644
此差异已折叠。
paddle/operators/hinge_loss_op.cc
0 → 100644
此差异已折叠。
paddle/operators/hinge_loss_op.cu
0 → 100644
此差异已折叠。
paddle/operators/hinge_loss_op.h
0 → 100644
此差异已折叠。
paddle/operators/log_loss_op.cc
0 → 100644
此差异已折叠。
paddle/operators/log_loss_op.cu
0 → 100644
此差异已折叠。
paddle/operators/log_loss_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/math/unpooling.h
0 → 100644
此差异已折叠。
paddle/operators/nce_op.cc
0 → 100644
此差异已折叠。
paddle/operators/nce_op.h
0 → 100644
此差异已折叠。
paddle/operators/recv_op.cc
0 → 100644
此差异已折叠。
paddle/operators/row_conv_op.cc
0 → 100644
此差异已折叠。
paddle/operators/row_conv_op.cu
0 → 100644
此差异已折叠。
paddle/operators/row_conv_op.h
0 → 100644
此差异已折叠。
paddle/operators/send_op.cc
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/operators/unpool_op.cc
0 → 100644
此差异已折叠。
paddle/operators/unpool_op.cu.cc
0 → 100644
此差异已折叠。
paddle/operators/unpool_op.h
0 → 100644
此差异已折叠。
paddle/platform/cuda_profiler.h
0 → 100644
此差异已折叠。
paddle/scripts/check_env.sh
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。