Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleDetection
提交
1752b6a1
P
PaddleDetection
项目概览
PaddlePaddle
/
PaddleDetection
大约 2 年 前同步成功
通知
708
Star
11112
Fork
2696
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
184
列表
看板
标记
里程碑
合并请求
40
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleDetection
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
184
Issue
184
列表
看板
标记
里程碑
合并请求
40
合并请求
40
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
1752b6a1
编写于
8月 07, 2017
作者:
Q
qijun
浏览文件
操作
浏览文件
下载
差异文件
Merge remote-tracking branch 'baidu/develop' into port_blas
上级
6b12c697
50fe7abe
变更
15
隐藏空白更改
内联
并排
Showing
15 changed file
with
248 addition
and
97 deletion
+248
-97
cmake/cpplint.cmake
cmake/cpplint.cmake
+10
-18
cmake/flags.cmake
cmake/flags.cmake
+2
-1
doc/design/mkldnn/README.MD
doc/design/mkldnn/README.MD
+110
-0
doc/design/mkldnn/image/overview.png
doc/design/mkldnn/image/overview.png
+0
-0
paddle/framework/operator.h
paddle/framework/operator.h
+5
-1
paddle/gserver/tests/CMakeLists.txt
paddle/gserver/tests/CMakeLists.txt
+0
-5
paddle/operators/add_op.cc
paddle/operators/add_op.cc
+2
-2
paddle/operators/mul_op.cc
paddle/operators/mul_op.cc
+9
-5
paddle/operators/recurrent_op.cc
paddle/operators/recurrent_op.cc
+19
-7
paddle/operators/rnn/recurrent_op_utils.cc
paddle/operators/rnn/recurrent_op_utils.cc
+15
-12
paddle/operators/sigmoid_op.cc
paddle/operators/sigmoid_op.cc
+4
-4
paddle/operators/sigmoid_op.cu
paddle/operators/sigmoid_op.cu
+2
-0
paddle/operators/sigmoid_op.h
paddle/operators/sigmoid_op.h
+19
-0
python/paddle/v2/framework/tests/test_recurrent_op.py
python/paddle/v2/framework/tests/test_recurrent_op.py
+48
-42
python/paddle/v2/framework/tests/test_sigmoid_op.py
python/paddle/v2/framework/tests/test_sigmoid_op.py
+3
-0
未找到文件。
cmake/cpplint.cmake
浏览文件 @
1752b6a1
...
@@ -42,29 +42,21 @@ macro(add_style_check_target TARGET_NAME)
...
@@ -42,29 +42,21 @@ macro(add_style_check_target TARGET_NAME)
if
(
WITH_STYLE_CHECK
)
if
(
WITH_STYLE_CHECK
)
set
(
SOURCES_LIST
${
ARGN
}
)
set
(
SOURCES_LIST
${
ARGN
}
)
list
(
REMOVE_DUPLICATES SOURCES_LIST
)
list
(
REMOVE_DUPLICATES SOURCES_LIST
)
list
(
SORT SOURCES_LIST
)
foreach
(
filename
${
SOURCES_LIST
}
)
foreach
(
filename
${
SOURCES_LIST
}
)
set
(
LINT ON
)
foreach
(
pattern
${
IGNORE_PATTERN
}
)
foreach
(
pattern
${
IGNORE_PATTERN
}
)
if
(
filename MATCHES
${
pattern
}
)
if
(
filename MATCHES
${
pattern
}
)
message
(
STATUS
"DROP LINT
${
filename
}
"
)
list
(
REMOVE_ITEM SOURCES_LIST
${
filename
}
)
set
(
LINT OFF
)
endif
()
endif
()
endforeach
()
endforeach
()
if
(
LINT MATCHES ON
)
# cpplint code style
get_filename_component
(
base_filename
${
filename
}
NAME
)
set
(
CUR_GEN
${
CMAKE_CURRENT_BINARY_DIR
}
/
${
base_filename
}
.cpplint
)
add_custom_command
(
OUTPUT
${
CUR_GEN
}
PRE_BUILD
COMMAND
"
${
PYTHON_EXECUTABLE
}
"
"
${
PROJ_ROOT
}
/paddle/scripts/cpplint.py"
"--filter=
${
STYLE_FILTER
}
"
"--write-success=
${
CUR_GEN
}
"
${
filename
}
DEPENDS
${
filename
}
${
PROJ_ROOT
}
/paddle/scripts/cpplint.py
WORKING_DIRECTORY
${
CMAKE_CURRENT_SOURCE_DIR
}
)
add_custom_target
(
${
base_filename
}
.cpplint DEPENDS
${
CUR_GEN
}
)
add_dependencies
(
${
TARGET_NAME
}
${
base_filename
}
.cpplint
)
endif
()
endforeach
()
endforeach
()
if
(
SOURCES_LIST
)
add_custom_command
(
TARGET
${
TARGET_NAME
}
POST_BUILD
COMMAND
"
${
PYTHON_EXECUTABLE
}
"
"
${
PROJ_ROOT
}
/paddle/scripts/cpplint.py"
"--filter=
${
STYLE_FILTER
}
"
${
SOURCES_LIST
}
COMMENT
"cpplint: Checking source code style"
WORKING_DIRECTORY
${
CMAKE_CURRENT_SOURCE_DIR
}
)
endif
()
endif
()
endif
()
endmacro
()
endmacro
()
cmake/flags.cmake
浏览文件 @
1752b6a1
...
@@ -115,7 +115,7 @@ set(COMMON_FLAGS
...
@@ -115,7 +115,7 @@ set(COMMON_FLAGS
-Wno-error=literal-suffix
-Wno-error=literal-suffix
-Wno-error=sign-compare
-Wno-error=sign-compare
-Wno-error=unused-local-typedefs
-Wno-error=unused-local-typedefs
-Wno-error=parentheses-equality
# Warnings in
P
ybind11
-Wno-error=parentheses-equality
# Warnings in
p
ybind11
)
)
set
(
GPU_COMMON_FLAGS
set
(
GPU_COMMON_FLAGS
...
@@ -195,6 +195,7 @@ endif()
...
@@ -195,6 +195,7 @@ endif()
# Modern gpu architectures: Pascal
# Modern gpu architectures: Pascal
if
(
CUDA_VERSION VERSION_GREATER
"8.0"
OR CUDA_VERSION VERSION_EQUAL
"8.0"
)
if
(
CUDA_VERSION VERSION_GREATER
"8.0"
OR CUDA_VERSION VERSION_EQUAL
"8.0"
)
list
(
APPEND __arch_flags
" -gencode arch=compute_60,code=sm_60"
)
list
(
APPEND __arch_flags
" -gencode arch=compute_60,code=sm_60"
)
list
(
APPEND CUDA_NVCC_FLAGS --expt-relaxed-constexpr
)
endif
()
endif
()
# Custom gpu architecture
# Custom gpu architecture
...
...
doc/design/mkldnn/README.MD
0 → 100644
浏览文件 @
1752b6a1
# Intel® MKL-DNN on PaddlePaddle: Design Doc
我们计划将Intel深度神经网络数学库(
**MKL-DNN**
\[
[
1
](
#references
)
\]
)集成到PaddlePaddle,充分展现英特尔平台的优势,有效提升PaddlePaddle在英特尔架构上的性能。
我们短期内的基本目标是:
-
完成常用layer的MKL-DNN实现。
-
完成常见深度神经网络VGG,GoogLeNet 和 ResNet的MKL-DNN实现。
## Contents
-
[
Overview
](
#overview
)
-
[
Actions
](
#actions
)
-
[
CMake
](
#cmake
)
-
[
Layers
](
#layers
)
-
[
Activations
](
#activations
)
-
[
Unit Tests
](
#unit-tests
)
-
[
Protobuf Messages
](
#protobuf-messages
)
-
[
Python API
](
#python-api
)
-
[
Demos
](
#demos
)
-
[
Benchmarking
](
#benchmarking
)
-
[
Others
](
#others
)
-
[
Design Concerns
](
#design-concerns
)
## Overview
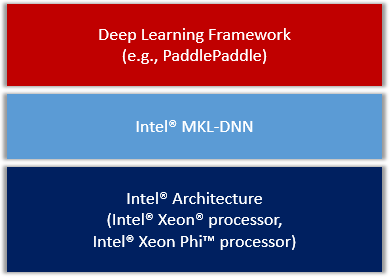
我们会把MKL-DNN作为第三方库集成进PaddlePaddle,整体框架图
<div
align=
"center"
>
<img
src=
"image/overview.png"
width=
350
><br/>
Figure 1. PaddlePaddle on IA.
</div>
## Actions
我们把集成方案大致分为了如下几个方面。
### CMake
我们会在
`CMakeLists.txt`
中会添加
`WITH_MKLDNN`
的选项,当设置这个值为
`ON`
的时候会启用编译MKL-DNN功能。同时会自动开启OpenMP用于提高MKL-DNN的性能。
同时,我们会引入
`WITH_MKLML`
选项,用于选择是否使用MKL-DNN自带的MKLML安装包。这个安装包可以独立于MKL-DNN使用,但是建议在开启MKL-DNN的同时也打开MKLML的开关,这样才能发挥最好的性能。
所以,我们会在
`cmake/external`
目录新建
`mkldnn.cmake`
和
`mklml.cmake`
文件,它们会在编译PaddlePaddle的时候下载对应的软件包,并放到PaddlePaddle的third party目录中。
**备注**
:当
`WITH_MKLML=ON`
的时候,会优先使用这个包作为PaddlePaddle的CBLAS和LAPACK库,所以会稍微改动
`cmake/cblas.cmake`
中的逻辑。
### Layers
所有MKL-DNN相关的C++ layers,都会按照PaddlePaddle的目录结构存放在
`paddle/gserver/layers`
中,并且文件名都会一以
*Mkldnn*
开头。
所有MKL-DNN的layers都会继承于一个叫做
`MkldnnLayer`
的父类,该父类继承于PaddlePaddle的基类
`Layer`
。
### Activations
由于在PaddlePaddle中,激活函数是独立于layer概念的,所以会在
`paddle/gserver/activations`
目录下添加一个
`MkldnnActivation.h`
文件定义一些用于MKL-DNN的接口,实现方法还是会在
`ActivationFunction.cpp`
文件。
### Unit Tests
会在
`paddle/gserver/test`
目录下添加
`test_Mkldnn.cpp`
和
`MkldnnTester.*`
用于MKL-DNN的测试。
Activation的测试,计划在PaddlePaddle原有的测试文件上直接添加新的测试type。
### Protobuf Messages
根据具体layer的需求可能会在
`proto/ModelConfig.proto`
里面添加必要的选项。
### Python API
目前只考虑
**v1 API**
。
计划在
`python/paddle/trainer/config_parser.py`
里面添加
`use_mkldnn`
这个选择,方便用户选择使用MKL-DNN的layers。
具体实现方式比如:
```
python
use_mkldnn
=
bool
(
int
(
g_command_config_args
.
get
(
"use_mkldnn"
,
0
)))
if
use_mkldnn
self
.
layer_type
=
mkldnn_
*
```
所有MKL-DNN的layer type会以
*mkldnn_*
开头,以示区分。
并且可能在
`python/paddle/trainer_config_helper`
目录下的
`activations.py `
和
`layers.py`
里面添加必要的MKL-DNN的接口。
### Demos
会在
`v1_api_demo`
目录下添加一个
`mkldnn`
的文件夹,里面放入一些用于MKL-DNN测试的demo脚本。
### Benchmarking
会考虑添加部分逻辑在
`benchmark/paddle/image/run.sh`
,添加使用MKL-DNN的测试。
### Others
1.
如果在使用MKL-DNN的情况下,会把CPU的Buffer对齐为64。
2.
深入PaddlePaddle,寻找有没有其他可以优化的可能,进一步优化。比如可能会用OpenMP改进SGD的更新性能。
## Design Concerns
为了更好的符合PaddlePaddle的代码风格
\[
[
2
](
#references
)
\]
,同时又尽可能少的牺牲MKL-DNN的性能
\[
[
3
](
#references
)
\]
。
我们总结出一些特别需要注意的点:
1.
使用
**deviceId_**
。为了尽可能少的在父类Layer中添加变量或者函数,我们决定使用已有的
`deviceId_`
变量来区分layer的属性,定义
`-2`
为
`MkldnnLayer`
特有的设备ID。
2.
重写父类Layer的
**init**
函数,修改
`deviceId_`
为
`-2`
,代表这个layer是用于跑在MKL-DNN的环境下。
3.
创建
`MkldnnMatrix`
,用于管理MKL-DNN会用到的相关memory函数、接口以及会用的到格式信息。
4.
创建
`MkldnnBase`
,定义一些除了layer和memory相关的类和函数。包括MKL-DNN会用到
`MkldnnStream`
和
`CpuEngine`
,和未来可能还会用到
`FPGAEngine`
等。
5.
在
**Argument**
里添加两个
`MkldnnMatrixPtr`
,取名为
`mkldnnValue`
和
`mkldnnGrad`
,用于存放
`MkldnnLayer`
会用到的memory buffer。 并且添加函数cvt(会修改为一个更加合适的函数名),用于处理"CPU device"和"MKL-DNN device"之间memory的相互转化。
6.
在父类
`Layer`
中的
`getOutput`
函数中添加一段逻辑,用于判断
`deviceId`
,并针对device在MKL-DNN和CPU之间不统一的情况,做一个前期转换。 也就是调用
`Argument`
的cvt函数把output统一到需要的device上。
7.
在原来的
`FLAGS`
中添加一个
`use_mkldnn`
的flag,用于选择是否使用MKL-DNN的相关功能。
## References
1.
[
Intel Math Kernel Library for Deep Neural Networks (Intel MKL-DNN)
](
https://github.com/01org/mkl-dnn
"Intel MKL-DNN"
)
2.
[
原来的方案
](
https://github.com/PaddlePaddle/Paddle/pull/3096
)
会引入
**nextLayer**
的信息。但是在PaddlePaddle中,无论是重构前的layer还是重构后的op,都不会想要知道next layer/op的信息。
3.
MKL-DNN的高性能格式与PaddlePaddle原有的
`NCHW`
不同(PaddlePaddle中的CUDNN部分使用的也是
`NCHW`
,所以不存在这个问题),所以需要引入一个转换方法,并且只需要在必要的时候转换这种格式,才能更好的发挥MKL-DNN的性能。
doc/design/mkldnn/image/overview.png
0 → 100644
浏览文件 @
1752b6a1
9.7 KB
paddle/framework/operator.h
浏览文件 @
1752b6a1
...
@@ -174,7 +174,11 @@ class OperatorContext {
...
@@ -174,7 +174,11 @@ class OperatorContext {
template
<
typename
T
>
template
<
typename
T
>
T
*
Output
(
const
size_t
index
)
const
{
T
*
Output
(
const
size_t
index
)
const
{
auto
var
=
OutputVar
(
index
);
auto
var
=
OutputVar
(
index
);
PADDLE_ENFORCE
(
var
!=
nullptr
,
"Output(%d) should not be nullptr"
,
index
);
PADDLE_ENFORCE
(
var
!=
nullptr
,
"Output(%d) not be nullptr, which means variable [%s] does not "
"exist in scope"
,
index
,
op_
.
outputs_
[
index
]);
return
var
->
GetMutable
<
T
>
();
return
var
->
GetMutable
<
T
>
();
}
}
...
...
paddle/gserver/tests/CMakeLists.txt
浏览文件 @
1752b6a1
# gserver pacakge unittests
# gserver pacakge unittests
file
(
GLOB_RECURSE GSERVER_HEADER RELATIVE
"
${
CMAKE_CURRENT_SOURCE_DIR
}
"
"*.h"
)
file
(
GLOB_RECURSE GSERVER_SOURCES RELATIVE
"
${
CMAKE_CURRENT_SOURCE_DIR
}
"
"*.cpp"
)
add_style_check_target
(
paddle_gserver
${
GSERVER_SOURCES
}
)
add_style_check_target
(
paddle_gserver
${
GSERVER_HEADER
}
)
################### test_ProtoDataProvider ############
################### test_ProtoDataProvider ############
add_unittest_without_exec
(
test_ProtoDataProvider
add_unittest_without_exec
(
test_ProtoDataProvider
test_ProtoDataProvider.cpp
)
test_ProtoDataProvider.cpp
)
...
...
paddle/operators/add_op.cc
浏览文件 @
1752b6a1
...
@@ -20,8 +20,8 @@ namespace operators {
...
@@ -20,8 +20,8 @@ namespace operators {
class
AddOp
:
public
OperatorWithKernel
{
class
AddOp
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
PADDLE_ENFORCE
(
ctx
.
InputSize
()
==
2
,
"Input size of AddOp must be two"
);
PADDLE_ENFORCE
_EQ
(
ctx
.
InputSize
(),
2
);
PADDLE_ENFORCE
(
ctx
.
OutputSize
()
==
1
,
"Output size of AddOp must be one"
);
PADDLE_ENFORCE
_EQ
(
ctx
.
OutputSize
(),
1
);
PADDLE_ENFORCE
(
ctx
.
InputVar
(
0
)
!=
nullptr
&&
ctx
.
InputVar
(
1
)
!=
nullptr
,
PADDLE_ENFORCE
(
ctx
.
InputVar
(
0
)
!=
nullptr
&&
ctx
.
InputVar
(
1
)
!=
nullptr
,
"Inputs of AddOp must all be set"
);
"Inputs of AddOp must all be set"
);
PADDLE_ENFORCE
(
ctx
.
OutputVar
(
0
)
!=
nullptr
,
PADDLE_ENFORCE
(
ctx
.
OutputVar
(
0
)
!=
nullptr
,
...
...
paddle/operators/mul_op.cc
浏览文件 @
1752b6a1
...
@@ -24,12 +24,16 @@ class MulOp : public OperatorWithKernel {
...
@@ -24,12 +24,16 @@ class MulOp : public OperatorWithKernel {
PADDLE_ENFORCE
(
ctx
.
InputSize
()
==
2
,
"The mul op must take two inputs"
);
PADDLE_ENFORCE
(
ctx
.
InputSize
()
==
2
,
"The mul op must take two inputs"
);
auto
dim0
=
ctx
.
Input
<
Tensor
>
(
0
)
->
dims
();
auto
dim0
=
ctx
.
Input
<
Tensor
>
(
0
)
->
dims
();
auto
dim1
=
ctx
.
Input
<
Tensor
>
(
1
)
->
dims
();
auto
dim1
=
ctx
.
Input
<
Tensor
>
(
1
)
->
dims
();
PADDLE_ENFORCE
(
dim0
.
size
()
==
2
&&
dim1
.
size
()
==
2
,
PADDLE_ENFORCE_EQ
(
dim0
.
size
(),
2
,
"The input of mul op must be matrix"
);
"input X(%s) should be a tensor with 2 dims, a matrix"
,
PADDLE_ENFORCE
(
ctx
.
op_
.
Input
(
"X"
));
dim0
[
1
]
==
dim1
[
0
],
PADDLE_ENFORCE_EQ
(
dim1
.
size
(),
2
,
"input Y(%s) should be a tensor with 2 dims, a matrix"
,
ctx
.
op_
.
Input
(
"Y"
));
PADDLE_ENFORCE_EQ
(
dim0
[
1
],
dim1
[
0
],
"First matrix's width must be equal with second matrix's height."
);
"First matrix's width must be equal with second matrix's height."
);
PADDLE_ENFORCE
(
ctx
.
OutputSize
()
==
1
,
"The mul op must take
one output"
);
PADDLE_ENFORCE
_EQ
(
ctx
.
OutputSize
(),
1
,
"The mul op takes only
one output"
);
ctx
.
Output
<
Tensor
>
(
0
)
->
Resize
({
dim0
[
0
],
dim1
[
1
]});
ctx
.
Output
<
Tensor
>
(
0
)
->
Resize
({
dim0
[
0
],
dim1
[
1
]});
}
}
};
};
...
...
paddle/operators/recurrent_op.cc
浏览文件 @
1752b6a1
...
@@ -36,6 +36,7 @@ void RecurrentAlgorithm::InferShape(const Scope& scope) const {
...
@@ -36,6 +36,7 @@ void RecurrentAlgorithm::InferShape(const Scope& scope) const {
InitMemories
(
step_scopes
[
0
],
true
/*infer_shape_mode*/
);
InitMemories
(
step_scopes
[
0
],
true
/*infer_shape_mode*/
);
Variable
*
net
=
scope
.
FindVar
(
arg_
->
step_net
);
Variable
*
net
=
scope
.
FindVar
(
arg_
->
step_net
);
PADDLE_ENFORCE
(
net
!=
nullptr
,
"failed to get step net"
);
PADDLE_ENFORCE
(
net
!=
nullptr
,
"failed to get step net"
);
for
(
size_t
i
=
0
;
i
<
seq_len_
;
i
++
)
{
for
(
size_t
i
=
0
;
i
<
seq_len_
;
i
++
)
{
if
(
i
>
0
)
{
if
(
i
>
0
)
{
rnn
::
LinkMemories
(
step_scopes
,
arg_
->
memories
,
i
,
-
1
,
rnn
::
LinkMemories
(
step_scopes
,
arg_
->
memories
,
i
,
-
1
,
...
@@ -56,6 +57,7 @@ void RecurrentAlgorithm::Run(const Scope& scope,
...
@@ -56,6 +57,7 @@ void RecurrentAlgorithm::Run(const Scope& scope,
Variable
*
net
=
scope
.
FindVar
(
arg_
->
step_net
);
Variable
*
net
=
scope
.
FindVar
(
arg_
->
step_net
);
for
(
size_t
step_id
=
0
;
step_id
<
seq_len_
;
step_id
++
)
{
for
(
size_t
step_id
=
0
;
step_id
<
seq_len_
;
step_id
++
)
{
// create output alias variables
if
(
step_id
>
0
)
{
if
(
step_id
>
0
)
{
rnn
::
LinkMemories
(
step_scopes
,
arg_
->
memories
,
step_id
,
-
1
,
rnn
::
LinkMemories
(
step_scopes
,
arg_
->
memories
,
step_id
,
-
1
,
false
/*infer_shape_mode*/
);
false
/*infer_shape_mode*/
);
...
@@ -67,22 +69,31 @@ void RecurrentAlgorithm::Run(const Scope& scope,
...
@@ -67,22 +69,31 @@ void RecurrentAlgorithm::Run(const Scope& scope,
}
}
void
RecurrentAlgorithm
::
CreateScopes
(
const
Scope
&
scope
)
const
{
void
RecurrentAlgorithm
::
CreateScopes
(
const
Scope
&
scope
)
const
{
// TODO(
xxx
) Only two scopes are needed for inference, this case will be
// TODO(
superjom
) Only two scopes are needed for inference, this case will be
// supported later.
// supported later.
auto
step_scopes
=
auto
step_scopes_var
=
scope
.
FindVar
(
arg_
->
step_scopes
);
scope
.
FindVar
(
arg_
->
step_scopes
)
->
GetMutable
<
std
::
vector
<
Scope
*>>
();
PADDLE_ENFORCE
(
step_scopes_var
!=
nullptr
,
""
);
auto
step_scopes
=
step_scopes_var
->
GetMutable
<
std
::
vector
<
Scope
*>>
();
// Now all variables in scope must be created outside of op.
auto
net_var
=
scope
.
FindVar
(
arg_
->
step_net
);
PADDLE_ENFORCE
(
net_var
!=
nullptr
,
"no stepnet called %s in scope"
,
arg_
->
step_net
);
auto
net_op
=
net_var
->
GetMutable
<
NetOp
>
();
PADDLE_ENFORCE
(
!
net_op
->
outputs_
.
empty
(),
"net_op has no outputs"
);
if
(
seq_len_
>
step_scopes
->
size
())
{
if
(
seq_len_
>
step_scopes
->
size
())
{
for
(
size_t
i
=
step_scopes
->
size
();
i
<
seq_len_
;
++
i
)
{
for
(
size_t
i
=
step_scopes
->
size
();
i
<
seq_len_
;
++
i
)
{
auto
&
step_scope
=
scope
.
NewScope
();
auto
&
step_scope
=
scope
.
NewScope
();
// Now all variables in scope must be created outside of op.
// create step net's temp inputs
auto
net_op
=
scope
.
FindVar
(
arg_
->
step_net
)
->
GetMutable
<
NetOp
>
();
for
(
auto
&
input
:
net_op
->
inputs_
)
{
for
(
auto
&
input
:
net_op
->
inputs_
)
{
// the weight are located in parent scope
// the weight are located in parent scope
if
(
!
step_scope
.
FindVar
(
input
))
step_scope
.
NewVar
(
input
);
if
(
!
step_scope
.
FindVar
(
input
))
step_scope
.
NewVar
(
input
)
->
GetMutable
<
Tensor
>
();
}
}
for
(
auto
&
output
:
net_op
->
outputs_
)
{
// create stepnet's outputs
for
(
const
auto
&
output
:
net_op
->
outputs_
)
{
step_scope
.
NewVar
(
output
);
step_scope
.
NewVar
(
output
);
}
}
step_scopes
->
emplace_back
(
&
step_scope
);
step_scopes
->
emplace_back
(
&
step_scope
);
...
@@ -100,6 +111,7 @@ void RecurrentAlgorithm::InitMemories(Scope* step_scope,
...
@@ -100,6 +111,7 @@ void RecurrentAlgorithm::InitMemories(Scope* step_scope,
Tensor
*
boot_mem
=
step_scope
->
FindVar
(
attr
.
boot_var
)
->
GetMutable
<
Tensor
>
();
Tensor
*
boot_mem
=
step_scope
->
FindVar
(
attr
.
boot_var
)
->
GetMutable
<
Tensor
>
();
if
(
infer_shape_mode
)
{
if
(
infer_shape_mode
)
{
pre_mem
->
Resize
(
boot_mem
->
dims
());
pre_mem
->
Resize
(
boot_mem
->
dims
());
PADDLE_ENFORCE_EQ
(
pre_mem
->
dims
().
size
(),
2
);
}
else
{
}
else
{
pre_mem
->
ShareDataWith
<
float
>
(
*
boot_mem
);
pre_mem
->
ShareDataWith
<
float
>
(
*
boot_mem
);
}
}
...
...
paddle/operators/rnn/recurrent_op_utils.cc
浏览文件 @
1752b6a1
...
@@ -53,11 +53,13 @@ void ConcatOutputs(const std::vector<Scope*>& step_scopes,
...
@@ -53,11 +53,13 @@ void ConcatOutputs(const std::vector<Scope*>& step_scopes,
PADDLE_ENFORCE
(
output_var
!=
nullptr
,
"output link [%s] is not in scope."
,
PADDLE_ENFORCE
(
output_var
!=
nullptr
,
"output link [%s] is not in scope."
,
outlinks
[
i
].
external
);
outlinks
[
i
].
external
);
Tensor
*
output
=
output_var
->
GetMutable
<
Tensor
>
();
Tensor
*
output
=
output_var
->
GetMutable
<
Tensor
>
();
if
(
infer_shape_mode
)
{
if
(
infer_shape_mode
)
{
fmw
::
DDim
step_dims
=
step_scopes
[
0
]
auto
step_scope_var
=
step_scopes
[
0
]
->
FindVar
(
outlinks
[
i
].
internal
);
->
FindVar
(
outlinks
[
i
].
internal
)
PADDLE_ENFORCE
(
step_scope_var
!=
nullptr
,
"%s not in scope"
,
->
GetMutable
<
Tensor
>
()
outlinks
[
i
].
internal
);
->
dims
();
fmw
::
DDim
step_dims
=
step_scope_var
->
template
GetMutable
<
Tensor
>()
->
dims
();
std
::
vector
<
int
>
dims_vec
=
vectorize
(
step_dims
);
std
::
vector
<
int
>
dims_vec
=
vectorize
(
step_dims
);
dims_vec
.
insert
(
dims_vec
.
begin
(),
seq_len
);
dims_vec
.
insert
(
dims_vec
.
begin
(),
seq_len
);
output
->
Resize
(
fmw
::
make_ddim
(
dims_vec
));
output
->
Resize
(
fmw
::
make_ddim
(
dims_vec
));
...
@@ -79,14 +81,15 @@ void LinkMemories(const std::vector<Scope*>& scopes,
...
@@ -79,14 +81,15 @@ void LinkMemories(const std::vector<Scope*>& scopes,
const
std
::
vector
<
rnn
::
MemoryAttr
>&
memories
,
const
std
::
vector
<
rnn
::
MemoryAttr
>&
memories
,
const
size_t
step_id
,
const
int
offset
,
const
size_t
step_id
,
const
int
offset
,
bool
infer_shape_mode
)
{
bool
infer_shape_mode
)
{
PADDLE_ENFORCE
(
step_id
<
scopes
.
size
(),
PADDLE_ENFORCE_LT
(
step_id
,
scopes
.
size
(),
"step [%d] is out of range of step scopes' size [%d]"
,
step_id
,
"step [%d] is out of range of step scopes' size [%d]"
,
scopes
.
size
());
step_id
,
scopes
.
size
());
PADDLE_ENFORCE
(
static_cast
<
int
>
(
step_id
)
+
offset
>=
0
,
PADDLE_ENFORCE_GE
(
static_cast
<
int
>
(
step_id
)
+
offset
,
0
,
"offset [%d] must be large than -[%d]"
,
offset
,
step_id
);
"offset [%d] must be large than -[%d]"
,
offset
,
step_id
);
PADDLE_ENFORCE
(
step_id
+
offset
<
scopes
.
size
(),
PADDLE_ENFORCE_LT
(
"offset [%d] is out of range, it must be less than (%d - %d)"
,
step_id
+
offset
,
scopes
.
size
(),
offset
,
scopes
.
size
(),
step_id
);
"offset [%d] is out of range, it must be less than (%d - %d)"
,
offset
,
scopes
.
size
(),
step_id
);
auto
scope
=
scopes
[
step_id
];
auto
scope
=
scopes
[
step_id
];
auto
linked_scope
=
scopes
[
step_id
+
offset
];
auto
linked_scope
=
scopes
[
step_id
+
offset
];
for
(
auto
&
attr
:
memories
)
{
for
(
auto
&
attr
:
memories
)
{
...
...
paddle/operators/sigmoid_op.cc
浏览文件 @
1752b6a1
...
@@ -37,10 +37,8 @@ class SigmoidOpMaker : public OpProtoAndCheckerMaker {
...
@@ -37,10 +37,8 @@ class SigmoidOpMaker : public OpProtoAndCheckerMaker {
class
SigmoidOpGrad
:
public
OperatorWithKernel
{
class
SigmoidOpGrad
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{}
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
std
::
string
DebugString
()
const
override
{
ctx
.
Output
<
Tensor
>
(
0
)
->
Resize
(
ctx
.
Input
<
Tensor
>
(
0
)
->
dims
());
LOG
(
INFO
)
<<
"SigmoidGrad"
;
return
""
;
}
}
};
};
...
@@ -51,3 +49,5 @@ REGISTER_OP(sigmoid, ops::SigmoidOp, ops::SigmoidOpMaker);
...
@@ -51,3 +49,5 @@ REGISTER_OP(sigmoid, ops::SigmoidOp, ops::SigmoidOpMaker);
REGISTER_GRADIENT_OP
(
sigmoid
,
sigmoid_grad
,
ops
::
SigmoidOpGrad
);
REGISTER_GRADIENT_OP
(
sigmoid
,
sigmoid_grad
,
ops
::
SigmoidOpGrad
);
REGISTER_OP_CPU_KERNEL
(
sigmoid
,
ops
::
SigmoidKernel
<
ops
::
CPUPlace
,
float
>
);
REGISTER_OP_CPU_KERNEL
(
sigmoid
,
ops
::
SigmoidKernel
<
ops
::
CPUPlace
,
float
>
);
REGISTER_OP_CPU_KERNEL
(
sigmoid_grad
,
ops
::
SigmoidGradKernel
<
ops
::
CPUPlace
,
float
>
);
paddle/operators/sigmoid_op.cu
浏览文件 @
1752b6a1
...
@@ -16,3 +16,5 @@
...
@@ -16,3 +16,5 @@
#include "paddle/operators/sigmoid_op.h"
#include "paddle/operators/sigmoid_op.h"
REGISTER_OP_GPU_KERNEL
(
sigmoid
,
ops
::
SigmoidKernel
<
ops
::
GPUPlace
,
float
>
);
REGISTER_OP_GPU_KERNEL
(
sigmoid
,
ops
::
SigmoidKernel
<
ops
::
GPUPlace
,
float
>
);
REGISTER_OP_GPU_KERNEL
(
sigmoid_grad
,
ops
::
SigmoidGradKernel
<
ops
::
GPUPlace
,
float
>
);
paddle/operators/sigmoid_op.h
浏览文件 @
1752b6a1
...
@@ -27,6 +27,7 @@ class SigmoidKernel : public OpKernel {
...
@@ -27,6 +27,7 @@ class SigmoidKernel : public OpKernel {
auto
output
=
context
.
Output
<
Tensor
>
(
0
);
auto
output
=
context
.
Output
<
Tensor
>
(
0
);
output
->
mutable_data
<
T
>
(
context
.
GetPlace
());
output
->
mutable_data
<
T
>
(
context
.
GetPlace
());
// The clipping is used in Paddle's raw implenmention
auto
X
=
EigenVector
<
T
>::
Flatten
(
*
input
);
auto
X
=
EigenVector
<
T
>::
Flatten
(
*
input
);
auto
Y
=
EigenVector
<
T
>::
Flatten
(
*
output
);
auto
Y
=
EigenVector
<
T
>::
Flatten
(
*
output
);
auto
place
=
context
.
GetEigenDevice
<
Place
>
();
auto
place
=
context
.
GetEigenDevice
<
Place
>
();
...
@@ -34,5 +35,23 @@ class SigmoidKernel : public OpKernel {
...
@@ -34,5 +35,23 @@ class SigmoidKernel : public OpKernel {
Y
.
device
(
place
)
=
1.0
/
(
1.0
+
(
-
1.0
*
X
).
exp
());
Y
.
device
(
place
)
=
1.0
/
(
1.0
+
(
-
1.0
*
X
).
exp
());
}
}
};
};
template
<
typename
Place
,
typename
T
>
class
SigmoidGradKernel
:
public
OpKernel
{
public:
void
Compute
(
const
ExecutionContext
&
context
)
const
override
{
auto
Y_t
=
context
.
Input
<
Tensor
>
(
"Y"
);
auto
dY_t
=
context
.
Input
<
Tensor
>
(
framework
::
GradVarName
(
"Y"
));
auto
dX_t
=
context
.
Output
<
Tensor
>
(
framework
::
GradVarName
(
"X"
));
dX_t
->
mutable_data
<
T
>
(
context
.
GetPlace
());
auto
dX
=
EigenVector
<
T
>::
Flatten
(
*
dX_t
);
auto
Y
=
EigenVector
<
T
>::
Flatten
(
*
Y_t
);
auto
dY
=
EigenVector
<
T
>::
Flatten
(
*
dY_t
);
dX
.
device
(
context
.
GetEigenDevice
<
Place
>
())
=
dY
*
Y
*
(
1.
-
Y
);
}
};
}
// namespace operators
}
// namespace operators
}
// namespace paddle
}
// namespace paddle
python/paddle/v2/framework/tests/test_recurrent_op.py
浏览文件 @
1752b6a1
import
logging
import
paddle.v2.framework.core
as
core
import
paddle.v2.framework.core
as
core
import
unittest
import
unittest
import
numpy
as
np
import
numpy
as
np
...
@@ -7,10 +8,9 @@ ops = creation.op_creations
...
@@ -7,10 +8,9 @@ ops = creation.op_creations
def
create_tensor
(
scope
,
name
,
shape
):
def
create_tensor
(
scope
,
name
,
shape
):
tensor
=
scope
.
create
_var
(
name
).
get_tensor
()
tensor
=
scope
.
new
_var
(
name
).
get_tensor
()
tensor
.
set_dims
(
shape
)
tensor
.
set_dims
(
shape
)
tensor
.
alloc_float
()
tensor
.
set
(
np
.
random
.
random
(
shape
),
core
.
CPUPlace
())
tensor
.
set
(
np
.
random
.
random
(
shape
))
return
tensor
return
tensor
...
@@ -31,40 +31,36 @@ class TestRNN(unittest.TestCase):
...
@@ -31,40 +31,36 @@ class TestRNN(unittest.TestCase):
- h
- h
'''
'''
input_dim
=
30
batch_size
=
50
weight_dim
=
15
sent_len
=
11
def
init
(
self
):
def
init
(
self
):
input_dim
=
30
batch_size
=
50
weight_dim
=
15
self
.
scope
=
core
.
Scope
(
None
)
# create vars
create_tensor
(
self
.
scope
,
"x"
,
[
batch_size
,
input_dim
])
create_tensor
(
self
.
scope
,
"W"
,
[
input_dim
,
weight_dim
])
create_tensor
(
self
.
scope
,
"U"
,
[
weight_dim
,
weight_dim
])
create_tensor
(
self
.
scope
,
"h_boot"
,
[
batch_size
,
weight_dim
])
x_alias
=
"x@alias"
y_alias
=
"y@alias"
memory
=
"h@alias"
prememory
=
"h@pre"
output
=
"rnn_out"
output_alias
=
"rnn_out@alias"
# create step net
stepnet_var
=
self
.
scope
.
create_var
(
"stepnet"
)
stepnet
=
stepnet_var
.
get_net
()
# stepnet = core.Net.create()
x_fc_op
=
ops
.
fc
(
X
=
x_alias
,
W
=
"W"
,
Y
=
"Wx"
)
h_fc_op
=
ops
.
fc
(
X
=
prememory
,
W
=
"U"
,
Y
=
"Uh"
)
sum_op
=
ops
.
add_two
(
X
=
"Wx"
,
Y
=
"Uh"
,
Out
=
"sum"
)
sig_op
=
ops
.
sigmoid
(
X
=
"sum"
,
Y
=
memory
)
stepnet
.
add_op
(
x_fc_op
)
stepnet
.
add_op
(
h_fc_op
)
stepnet
.
add_op
(
sum_op
)
stepnet
.
add_op
(
sig_op
)
stepnet
.
complete_add_op
(
True
)
self
.
scope
=
core
.
Scope
()
self
.
create_global_variables
()
self
.
create_step_net
()
rnn_op
=
self
.
create_rnn_op
()
ctx
=
core
.
DeviceContext
.
create
(
core
.
CPUPlace
())
print
'infer_shape'
rnn_op
.
infer_shape
(
self
.
scope
)
rnn_op
.
run
(
self
.
scope
,
ctx
)
def
create_global_variables
(
self
):
# create inlink
create_tensor
(
self
.
scope
,
"x"
,
[
self
.
sent_len
,
self
.
batch_size
,
self
.
input_dim
])
create_tensor
(
self
.
scope
,
"W"
,
[
self
.
input_dim
,
self
.
input_dim
])
create_tensor
(
self
.
scope
,
"U"
,
[
self
.
input_dim
,
self
.
input_dim
])
create_tensor
(
self
.
scope
,
"h_boot"
,
[
self
.
batch_size
,
self
.
input_dim
])
self
.
scope
.
new_var
(
"step_scopes"
)
self
.
scope
.
new_var
(
"h@alias"
)
self
.
scope
.
new_var
(
"h"
)
def
create_rnn_op
(
self
):
# create RNNOp
# create RNNOp
rnnop
=
ops
.
recurrent_op
(
rnnop
=
ops
.
recurrent_op
(
# inputs
# inputs
...
@@ -72,17 +68,27 @@ class TestRNN(unittest.TestCase):
...
@@ -72,17 +68,27 @@ class TestRNN(unittest.TestCase):
boot_memories
=
[
"h_boot"
],
boot_memories
=
[
"h_boot"
],
step_net
=
"stepnet"
,
step_net
=
"stepnet"
,
# outputs
# outputs
outlinks
=
[
output
],
outlinks
=
[
"h"
],
step_scopes
=
"step_scopes"
,
step_scopes
=
"step_scopes"
,
# attributes
# attributes
inlink_alias
=
[
"x@alias"
],
inlink_alias
=
[
"x@alias"
],
outlink_alias
=
[
output_alias
],
outlink_alias
=
[
"h@alias"
],
pre_memories
=
[
prememory
],
pre_memories
=
[
"h@pre"
],
memories
=
[
memory
])
memories
=
[
"h@alias"
])
return
rnnop
def
create_step_net
(
self
):
var
=
self
.
scope
.
new_var
(
"stepnet"
)
stepnet
=
var
.
get_net
()
ctx
=
core
.
DeviceContext
.
cpu_context
()
x_fc_op
=
ops
.
fc
(
X
=
"x@alias"
,
W
=
"W"
,
Y
=
"Wx"
)
rnnop
.
infer_shape
(
self
.
scope
)
h_fc_op
=
ops
.
fc
(
X
=
"h@pre"
,
W
=
"U"
,
Y
=
"Uh"
)
rnnop
.
run
(
self
.
scope
,
ctx
)
sum_op
=
ops
.
add_two
(
X
=
"Wx"
,
Y
=
"Uh"
,
Out
=
"sum"
)
sig_op
=
ops
.
sigmoid
(
X
=
"sum"
,
Y
=
"h@alias"
)
for
op
in
[
x_fc_op
,
h_fc_op
,
sum_op
,
sig_op
]:
stepnet
.
add_op
(
op
)
stepnet
.
complete_add_op
(
True
)
def
test_recurrent
(
self
):
def
test_recurrent
(
self
):
self
.
init
()
self
.
init
()
...
...
python/paddle/v2/framework/tests/test_sigmoid_op.py
浏览文件 @
1752b6a1
...
@@ -12,5 +12,8 @@ class TestSigmoidOp(unittest.TestCase):
...
@@ -12,5 +12,8 @@ class TestSigmoidOp(unittest.TestCase):
self
.
outputs
=
{
'Y'
:
1
/
(
1
+
np
.
exp
(
-
self
.
inputs
[
'X'
]))}
self
.
outputs
=
{
'Y'
:
1
/
(
1
+
np
.
exp
(
-
self
.
inputs
[
'X'
]))}
#class TestSigmoidGradOp(unittest.TestCase):
#TODO(qingqing) add unit test
if
__name__
==
'__main__'
:
if
__name__
==
'__main__'
:
unittest
.
main
()
unittest
.
main
()
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}