Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into config_helper_test
Showing
{kind=link}
179.1 KB
{kind=link}

33.1 KB
{kind=link}
76.7 KB
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已添加
{kind=link}
141.7 KB
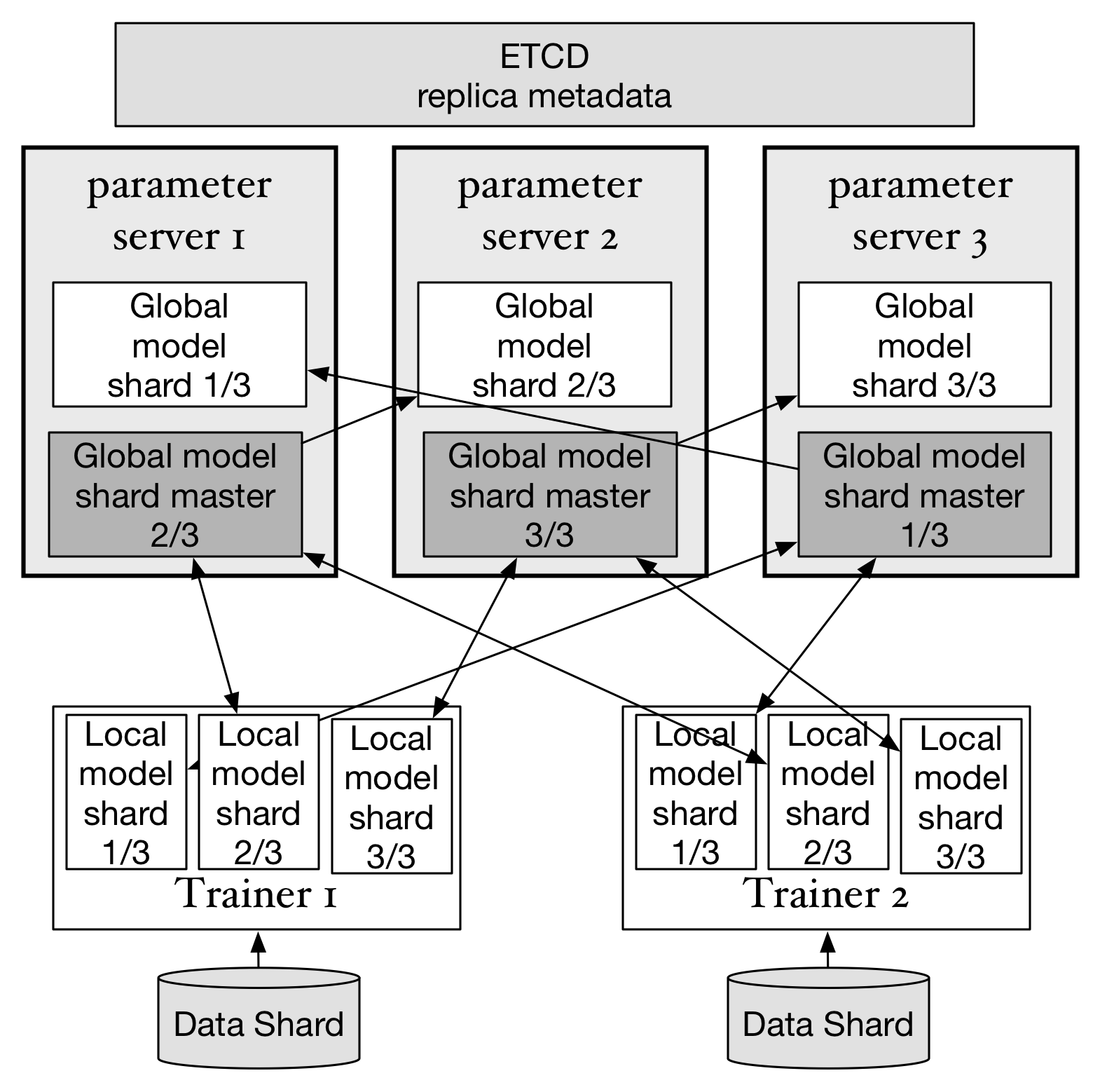
doc/design/images/replica.png
0 → 100644
{kind=link}
174.9 KB
{kind=link}
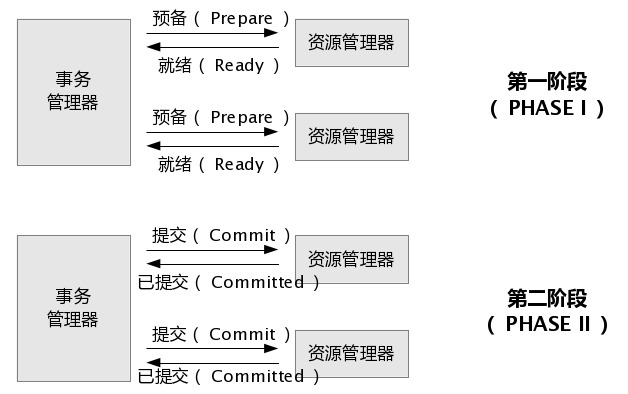
48.0 KB