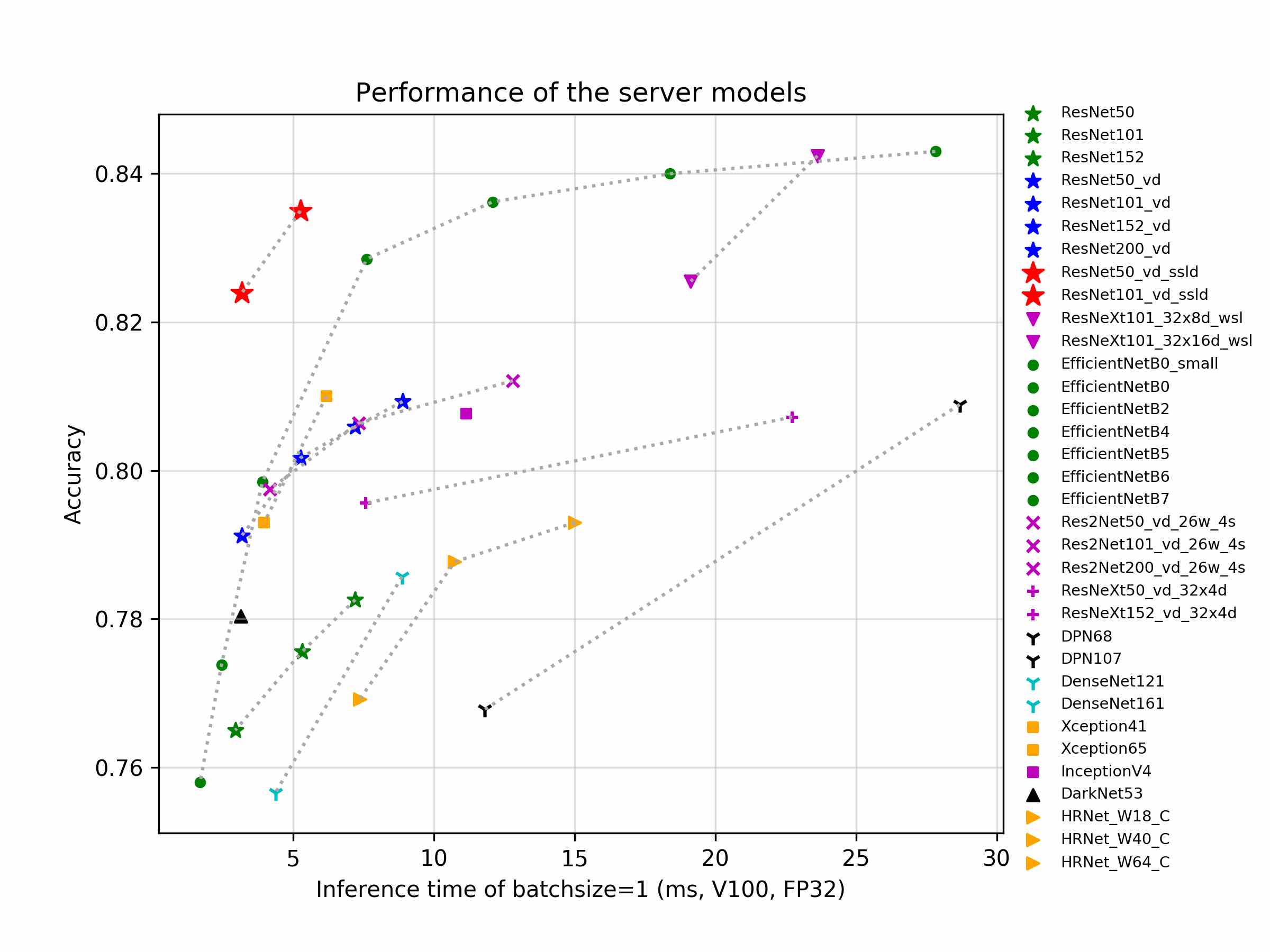
The above figure shows some of the latest server-side pretrained models. It can be seen from the figure that when using V100 GPU with FP32 and TensorRT, the `Top1` accuracy of the ResNet50_vd_ssld pretrained model on ImageNet1k-val dataset is **83.0%** and that of ResNet101_vd_ssld pretrained model is 83.7%. These pretained models are obtained from SSLD knowledge distillation solution provided by PaddleClas. The marks of the same color and symbol in the figure represent models of different model sizes in the same series. For the introduction of different models, FLOPS, Params and detailed GPU inference time (including the inference speed of T4 GPU with different batch size), please refer to the documentation tutorial for more details: [https://paddleclas-en.readthedocs.io/en/latest/models/models_intro_en.html](https://paddleclas-en.readthedocs.io/en/latest/models/models_intro_en.html)
The above figure shows some of the latest server-side pretrained models. It can be seen from the figure that when using V100 GPU with FP32 and TensorRT, the `Top1` accuracy of the ResNet50_vd_ssld pretrained model on ImageNet1k-val dataset is **83.0%** and that of ResNet101_vd_ssld pretrained model is 83.7%. These pretained models are obtained from SSLD knowledge distillation solution provided by PaddleClas. The marks of the same color and symbol in the figure represent models of different model sizes in the same series. For the introduction of different models, FLOPS, Params and detailed GPU inference time (including the inference speed of T4 GPU with different batch size), please refer to the documentation tutorial for more details: [https://paddleclas-en.readthedocs.io/en/latest/models/models_intro_en.html](https://paddleclas-en.readthedocs.io/en/latest/models/models_intro_en.html)
In recent years, deep neural networks have been proven to be an extremely effective method to solve problems in the fields of computer vision and natural language processing. The deep learning methods performs better than traditional methods with suitable network structure and training process.
In recent years, deep neural networks have been proven to be an extremely effective method to solve problems in the fields of computer vision and natural language processing. The deep learning methods performs better than traditional methods with suitable network structure and training process.
...
@@ -13,9 +13,9 @@ Parameter redundancy exists in deep neural networks. There are several methods t
...
@@ -13,9 +13,9 @@ Parameter redundancy exists in deep neural networks. There are several methods t
@@ -34,7 +34,7 @@ First, we select nearly 4 million images from ImageNet22k dataset, and integrate
...
@@ -34,7 +34,7 @@ First, we select nearly 4 million images from ImageNet22k dataset, and integrate
* ImageNet1k finetune. ImageNet1k training set is used for finetuning, which brings a 0.4% accuracy improvement (`75.8%-> 78.9%`).
* ImageNet1k finetune. ImageNet1k training set is used for finetuning, which brings a 0.4% accuracy improvement (`75.8%-> 78.9%`).
## 2.2 Data selection
## Data selection
* An important feature of the SSLD distillation scheme is no need for labeled images, so the dataset size can be arbitrarily expanded. Considering the limitation of computing resources, we here only expand the training set of the distillation task based on the ImageNet22k dataset. For SSLD, we used the `Top-k per class` data sampling scheme [3]. Specific steps are as follows.
* An important feature of the SSLD distillation scheme is no need for labeled images, so the dataset size can be arbitrarily expanded. Considering the limitation of computing resources, we here only expand the training set of the distillation task based on the ImageNet22k dataset. For SSLD, we used the `Top-k per class` data sampling scheme [3]. Specific steps are as follows.
* Deduplication of training set. We first deduplicate the ImageNet22k dataset and the ImageNet1k validation set based on the SIFT feature similarity matching method to prevent the added ImageNet22k training set from containing the ImageNet1k validation set images. Finally we removed 4511 similar images. Similar pictures with partial filtering are shown below.
* Deduplication of training set. We first deduplicate the ImageNet22k dataset and the ImageNet1k validation set based on the SIFT feature similarity matching method to prevent the added ImageNet22k training set from containing the ImageNet1k validation set images. Finally we removed 4511 similar images. Similar pictures with partial filtering are shown below.
...
@@ -45,11 +45,11 @@ First, we select nearly 4 million images from ImageNet22k dataset, and integrate
...
@@ -45,11 +45,11 @@ First, we select nearly 4 million images from ImageNet22k dataset, and integrate
* Top-k data selection. There contains 1000 categories in ImageNet1k dataset. For each category, we find out images in the category with Top-k highest score, and finally generate a dataset whose image number does not exceed `1000 * k` (For some categories, there may contain less than k images).
* Top-k data selection. There contains 1000 categories in ImageNet1k dataset. For each category, we find out images in the category with Top-k highest score, and finally generate a dataset whose image number does not exceed `1000 * k` (For some categories, there may contain less than k images).
* The selected images are merged with the ImageNet1k training set to form the new dataset used for the final distillation model training, which contains 5 million images in all.
* The selected images are merged with the ImageNet1k training set to form the new dataset used for the final distillation model training, which contains 5 million images in all.
# 3. Experiments
# Experiments
The distillation solution that PaddleClas provides is combining common training with finetuning. Given a suitable teacher model, the large dataset(5 million) is used for common training and the ImageNet1k dataset is used for finetuning.
The distillation solution that PaddleClas provides is combining common training with finetuning. Given a suitable teacher model, the large dataset(5 million) is used for common training and the ImageNet1k dataset is used for finetuning.
## 3.1 Choice of teacher model
## Choice of teacher model
In order to verify the influence of the model size difference between the teacher model and the student model on the distillation results as well as the teacher model accuracy, we conducted several experiments. The training strategy is unified as follows: `cosine_decay_warmup, lr = 1.3, epoch = 120, bs = 2048`, and the student models are all trained from scratch.
In order to verify the influence of the model size difference between the teacher model and the student model on the distillation results as well as the teacher model accuracy, we conducted several experiments. The training strategy is unified as follows: `cosine_decay_warmup, lr = 1.3, epoch = 120, bs = 2048`, and the student models are all trained from scratch.
...
@@ -70,7 +70,7 @@ It can be shown from the table that:
...
@@ -70,7 +70,7 @@ It can be shown from the table that:
Therefore, during distillation, for the ResNet series student model, we use `ResNeXt101_32x16d_wsl` as the teacher model; for the MobileNet series student model, we use` ResNet50_vd_SSLD` as the teacher model.
Therefore, during distillation, for the ResNet series student model, we use `ResNeXt101_32x16d_wsl` as the teacher model; for the MobileNet series student model, we use` ResNet50_vd_SSLD` as the teacher model.
## 3.2 Distillation using large-scale dataset
## Distillation using large-scale dataset
Training process is carried out on the large-scale dataset with 5 million images. Specifically, the following table shows more details of different models.
Training process is carried out on the large-scale dataset with 5 million images. Specifically, the following table shows more details of different models.
...
@@ -83,7 +83,7 @@ Training process is carried out on the large-scale dataset with 5 million images
...
@@ -83,7 +83,7 @@ Training process is carried out on the large-scale dataset with 5 million images
Finetuning is carried out on ImageNet1k dataset to restore distribution between training set and test set. the following table shows more details of finetuning.
Finetuning is carried out on ImageNet1k dataset to restore distribution between training set and test set. the following table shows more details of finetuning.
...
@@ -97,16 +97,16 @@ Finetuning is carried out on ImageNet1k dataset to restore distribution between
...
@@ -97,16 +97,16 @@ Finetuning is carried out on ImageNet1k dataset to restore distribution between
* Based on experiments mentioned above, we add AutoAugment [4] during training process, and reduced l2_decay from 4e-5 t 2e-5. Finally, the Top-1 accuracy on ImageNet1k dataset can reach 82.99%, with 0.6% improvement compared to the standard SSLD distillation strategy.
* Based on experiments mentioned above, we add AutoAugment [4] during training process, and reduced l2_decay from 4e-5 t 2e-5. Finally, the Top-1 accuracy on ImageNet1k dataset can reach 82.99%, with 0.6% improvement compared to the standard SSLD distillation strategy.
* For image classsification tasks, The model accuracy can be further improved when the test scale is 1.15 times that of training[5]. For the 82.99% ResNet50_vd pretrained model, it comes to 83.7% using 320x320 for the evaluation. We use Fix strategy to finetune the model with the training scale set as 320x320. During the process, the pre-preocessing pipeline is same for both training and test. All the weights except the fully connected layer are freezed. Finally the top-1 accuracy comes to **84.0%**.
* For image classsification tasks, The model accuracy can be further improved when the test scale is 1.15 times that of training[5]. For the 82.99% ResNet50_vd pretrained model, it comes to 83.7% using 320x320 for the evaluation. We use Fix strategy to finetune the model with the training scale set as 320x320. During the process, the pre-preocessing pipeline is same for both training and test. All the weights except the fully connected layer are freezed. Finally the top-1 accuracy comes to **84.0%**.
# 4. Application of the distillation model
# Application of the distillation model
## 4.1 Instructions
## Instructions
* Adjust the learning rate of the middle layer. The middle layer feature map of the model obtained by distillation is more refined. Therefore, when the distillation model is used as the pretrained model in other tasks, if the same learning rate as before is adopted, it is easy to destroy the features. If the learning rate of the overall model training is reduced, it will bring about the problem of slow convergence. Therefore, we use the strategy of adjusting the learning rate of the middle layer. specifically:
* Adjust the learning rate of the middle layer. The middle layer feature map of the model obtained by distillation is more refined. Therefore, when the distillation model is used as the pretrained model in other tasks, if the same learning rate as before is adopted, it is easy to destroy the features. If the learning rate of the overall model training is reduced, it will bring about the problem of slow convergence. Therefore, we use the strategy of adjusting the learning rate of the middle layer. specifically:
* For ResNet50_vd, we set up a learning rate list. The three conv2d convolution parameters before the resiual block have a uniform learning rate multiple, and the four resiual block conv2d have theirs own learning rate parameters, respectively. 5 values need to be set in the list. By the experiment, we find that when used for transfer learning finetune classification model, the learning rate list with `[0.1,0.1,0.2,0.2,0.3]` performs better in most tasks; while in the object detection tasks, `[0.05, 0.05, 0.05, 0.1, 0.15]` can bring greater accuracy gains.
* For ResNet50_vd, we set up a learning rate list. The three conv2d convolution parameters before the resiual block have a uniform learning rate multiple, and the four resiual block conv2d have theirs own learning rate parameters, respectively. 5 values need to be set in the list. By the experiment, we find that when used for transfer learning finetune classification model, the learning rate list with `[0.1,0.1,0.2,0.2,0.3]` performs better in most tasks; while in the object detection tasks, `[0.05, 0.05, 0.05, 0.1, 0.15]` can bring greater accuracy gains.
...
@@ -114,7 +114,7 @@ Finetuning is carried out on ImageNet1k dataset to restore distribution between
...
@@ -114,7 +114,7 @@ Finetuning is carried out on ImageNet1k dataset to restore distribution between
* Appropriate l2 decay. Different l2 decay values are set for different models during training. In order to prevent overfitting, l2 decay is ofen set as large for large models. L2 decay is set as `1e-4` for ResNet50, and `1e-5 ~ 4e-5` for MobileNet series models. L2 decay needs also to be adjusted when applied in other tasks. Taking Faster_RCNN_MobiletNetV3_FPN as an example, we found that only modifying l2 decay can bring up to 0.5% accuracy (mAP) improvement on the COCO2017 dataset.
* Appropriate l2 decay. Different l2 decay values are set for different models during training. In order to prevent overfitting, l2 decay is ofen set as large for large models. L2 decay is set as `1e-4` for ResNet50, and `1e-5 ~ 4e-5` for MobileNet series models. L2 decay needs also to be adjusted when applied in other tasks. Taking Faster_RCNN_MobiletNetV3_FPN as an example, we found that only modifying l2 decay can bring up to 0.5% accuracy (mAP) improvement on the COCO2017 dataset.
## 4.2 Transfer learning
## Transfer learning
* To verify the effect of the SSLD pretrained model in transfer learning, we carried out experiments on 10 small datasets. Here, in order to ensure the comparability of the experiment, we use the standard preprocessing process trained by the ImageNet1k dataset. For the distillation model, we also add a simple search method for the learning rate of the middle layers of the distillation pretrained model.
* To verify the effect of the SSLD pretrained model in transfer learning, we carried out experiments on 10 small datasets. Here, in order to ensure the comparability of the experiment, we use the standard preprocessing process trained by the ImageNet1k dataset. For the distillation model, we also add a simple search method for the learning rate of the middle layers of the distillation pretrained model.
* For ResNet50_vd, the baseline pretrained model Top-1 Acc is 79.12%, the other parameters are got by grid search. For distillation pretrained model, we add learning rate of the middle layers into the search space. The following table shows the results.
* For ResNet50_vd, the baseline pretrained model Top-1 Acc is 79.12%, the other parameters are got by grid search. For distillation pretrained model, we add learning rate of the middle layers into the search space. The following table shows the results.
...
@@ -134,9 +134,8 @@ Finetuning is carried out on ImageNet1k dataset to restore distribution between
...
@@ -134,9 +134,8 @@ Finetuning is carried out on ImageNet1k dataset to restore distribution between
* It can be seen that on the above 10 datasets, combined with the appropriate middle layer learning rate, the distillation pretrained model can bring an average accuracy improvement of more than 1%.
* It can be seen that on the above 10 datasets, combined with the appropriate middle layer learning rate, the distillation pretrained model can bring an average accuracy improvement of more than 1%.
## 4.3 Object detection
## Object detection
## 4.3 目标检测
Based on the two-stage Faster/Cascade RCNN model, we verify the effect of the pretrained model obtained by distillation.
Based on the two-stage Faster/Cascade RCNN model, we verify the effect of the pretrained model obtained by distillation.
...
@@ -152,16 +151,16 @@ Training scale and test scale are set as 640x640, and some of the ablationstudie
...
@@ -152,16 +151,16 @@ Training scale and test scale are set as 640x640, and some of the ablationstudie
It can be seen here that for the baseline pretrained model, excessive adjustment of the middle-layer learning rate actually reduces the performance of the detection model. Based on this distillation model, we also provide a practical server-side detection solution. The detailed configuration and training code are open source, more details can be refer to [PaddleDetection] (https://github.com/PaddlePaddle/PaddleDetection/tree/master/configs/rcnn_server_side_det).
It can be seen here that for the baseline pretrained model, excessive adjustment of the middle-layer learning rate actually reduces the performance of the detection model. Based on this distillation model, we also provide a practical server-side detection solution. The detailed configuration and training code are open source, more details can be refer to [PaddleDetection] (https://github.com/PaddlePaddle/PaddleDetection/tree/master/configs/rcnn_enhance).
# 五、Practice
# Practice
This section will introduce the SSLD distillation experiments in detail based on the ImageNet-1K dataset. If you want to experience this method quickly, you can refer to [** Quick start PaddleClas in 30 minutes**] (../../tutorials/quick_start.md), whose dataset is set as Flowers102.
This section will introduce the SSLD distillation experiments in detail based on the ImageNet-1K dataset. If you want to experience this method quickly, you can refer to [** Quick start PaddleClas in 30 minutes**] (../../tutorials/quick_start.md), whose dataset is set as Flowers102.
* Before using SSLD, users need to train a teacher model on the target dataset firstly. The teacher model is used to guide the training of the student model.
* Before using SSLD, users need to train a teacher model on the target dataset firstly. The teacher model is used to guide the training of the student model.
Image augmentation is a commonly used regularization method in image classification task, which is often used in scenarios with insufficient data or large model. In this chapter, we mainly introduce 8 image augmentation methods besides standard augmentation methods. Users can apply these methods in their own tasks for better model performance. Under the same conditions, These augmentation methods' performance on ImageNet1k dataset is shown as follows.
Image augmentation is a commonly used regularization method in image classification task, which is often used in scenarios with insufficient data or large model. In this chapter, we mainly introduce 8 image augmentation methods besides standard augmentation methods. Users can apply these methods in their own tasks for better model performance. Under the same conditions, These augmentation methods' performance on ImageNet1k dataset is shown as follows.
...
@@ -6,7 +6,7 @@ Image augmentation is a commonly used regularization method in image classificat
...
@@ -6,7 +6,7 @@ Image augmentation is a commonly used regularization method in image classificat


# 2. Common image augmentation methods
# Common image augmentation methods
If without special explanation, all the examples and experiments in this chapter are based on ImageNet1k dataset with the network input image size set as 224.
If without special explanation, all the examples and experiments in this chapter are based on ImageNet1k dataset with the network input image size set as 224.
...
@@ -49,11 +49,11 @@ PaddleClas integrates all the above data augmentation strategies. More details i
...
@@ -49,11 +49,11 @@ PaddleClas integrates all the above data augmentation strategies. More details i


# 3. Image Transformation
# Image Transformation
Transformation means performing some transformations on the image after `RandCrop`. It mainly contains AutoAugment and RandAugment.
Transformation means performing some transformations on the image after `RandCrop`. It mainly contains AutoAugment and RandAugment.
@@ -128,7 +128,7 @@ The images after `RandAugment` are as follows.
...
@@ -128,7 +128,7 @@ The images after `RandAugment` are as follows.
![][test_randaugment]
![][test_randaugment]
# 4. Image Cropping
# Image Cropping
Cropping means performing some transformations on the image after `Transpose`, setting pixels of the cropped area as certain constant. It mainly contains CutOut, RandErasing, HideAndSeek and GridMask.
Cropping means performing some transformations on the image after `Transpose`, setting pixels of the cropped area as certain constant. It mainly contains CutOut, RandErasing, HideAndSeek and GridMask.
...
@@ -137,7 +137,7 @@ Image cropping methods can be operated before or after normalization. The differ
...
@@ -137,7 +137,7 @@ Image cropping methods can be operated before or after normalization. The differ
The above-mentioned cropping transformation ideas are the similar, all to solve the problem of poor generalization ability of the trained model on occlusion images, the difference lies in that their cropping details.
The above-mentioned cropping transformation ideas are the similar, all to solve the problem of poor generalization ability of the trained model on occlusion images, the difference lies in that their cropping details.
@@ -402,7 +402,7 @@ The images after `Cutmix` are as follows.
...
@@ -402,7 +402,7 @@ The images after `Cutmix` are as follows.
![][test_cutmix]
![][test_cutmix]
# 6. Experiments
# Experiments
Based on PaddleClas, Metrics of different augmentation methods on ImageNet1k dataset are as follows.
Based on PaddleClas, Metrics of different augmentation methods on ImageNet1k dataset are as follows.
...
@@ -426,15 +426,15 @@ Based on PaddleClas, Metrics of different augmentation methods on ImageNet1k dat
...
@@ -426,15 +426,15 @@ Based on PaddleClas, Metrics of different augmentation methods on ImageNet1k dat
## 7. Data augmentation practice
## Data augmentation practice
Experiments about data augmentation will be introduced in detail in this section. If you want to quickly experience these methods, please refer to [**Quick start PaddleClas in 30 miniutes**](../../tutorials/quick_start_en.md).
Experiments about data augmentation will be introduced in detail in this section. If you want to quickly experience these methods, please refer to [**Quick start PaddleClas in 30 miniutes**](../../tutorials/quick_start_en.md).
## 7.1 Configurations
## Configurations
Since hyperparameters differ from different augmentation methods. For better understanding, we list 8 augmentation configuration files in `configs/DataAugment` based on ResNet50. Users can train the model with `tools/run.sh`. The following are 3 of them.
Since hyperparameters differ from different augmentation methods. For better understanding, we list 8 augmentation configuration files in `configs/DataAugment` based on ResNet50. Users can train the model with `tools/run.sh`. The following are 3 of them.
### 7.1.1 RandAugment
### RandAugment
Configuration of `RandAugment` is shown as follows. `Num_layers`(default as 2) and `magnitude`(default as 5) are two hyperparameters.
Configuration of `RandAugment` is shown as follows. `Num_layers`(default as 2) and `magnitude`(default as 5) are two hyperparameters.
...
@@ -460,7 +460,7 @@ Configuration of `RandAugment` is shown as follows. `Num_layers`(default as 2) a
...
@@ -460,7 +460,7 @@ Configuration of `RandAugment` is shown as follows. `Num_layers`(default as 2) a
-ToCHWImage:
-ToCHWImage:
```
```
### 7.1.2 Cutout
### Cutout
Configuration of `Cutout` is shown as follows. `n_holes`(default as 1) and `n_holes`(default as 112) are two hyperparameters.
Configuration of `Cutout` is shown as follows. `n_holes`(default as 1) and `n_holes`(default as 112) are two hyperparameters.
...
@@ -485,7 +485,7 @@ Configuration of `Cutout` is shown as follows. `n_holes`(default as 1) and `n_ho
...
@@ -485,7 +485,7 @@ Configuration of `Cutout` is shown as follows. `n_holes`(default as 1) and `n_ho
-ToCHWImage:
-ToCHWImage:
```
```
### 7.1.3 Mixup
### Mixup
Configuration of `Mixup` is shown as follows. `alpha`(default as 0.2) is hyperparameter which users need to care about. What's more, `use_mix` need to be set as `True` in the root of the configuration.
Configuration of `Mixup` is shown as follows. `alpha`(default as 0.2) is hyperparameter which users need to care about. What's more, `use_mix` need to be set as `True` in the root of the configuration.
...
@@ -511,7 +511,7 @@ Configuration of `Mixup` is shown as follows. `alpha`(default as 0.2) is hyperpa
...
@@ -511,7 +511,7 @@ Configuration of `Mixup` is shown as follows. `alpha`(default as 0.2) is hyperpa
alpha:0.2
alpha:0.2
```
```
## 7.2 启动命令
## 启动命令
Users can use the following command to start the training process, which can also be referred to `tools/run.sh`.
Users can use the following command to start the training process, which can also be referred to `tools/run.sh`.
* When using augmentation methods based on image aliasing, users need to set `use_mix` in the configuration file as `True`. In addition, because the label needs to be aliased when the image is aliased, the accuracy of the training data cannot be calculated. The training accuracy rate was not printed during the training process.
* When using augmentation methods based on image aliasing, users need to set `use_mix` in the configuration file as `True`. In addition, because the label needs to be aliased when the image is aliased, the accuracy of the training data cannot be calculated. The training accuracy rate was not printed during the training process.
Transfer learning is an important part of machine learning, which is widely used in various fields such as text and images. Here we mainly introduce transfer learning in the field of image classification, which is often called domain transfer, such as migration of the ImageNet classification model to the specified image classification task, such as flower classification.
Transfer learning is an important part of machine learning, which is widely used in various fields such as text and images. Here we mainly introduce transfer learning in the field of image classification, which is often called domain transfer, such as migration of the ImageNet classification model to the specified image classification task, such as flower classification.
## 1. Hyperparameter search
## Hyperparameter search
ImageNet is the widely used dataset for image classification. A series of empirical hyperparameters have been summarized. High accuracy can be got using the hyperparameters. However, when applied in the specified dataset, the hyperparameters may not be optimal. There are two commonly used hyperparameter search methods that can be used to help us obtain better model hyperparameters.
ImageNet is the widely used dataset for image classification. A series of empirical hyperparameters have been summarized. High accuracy can be got using the hyperparameters. However, when applied in the specified dataset, the hyperparameters may not be optimal. There are two commonly used hyperparameter search methods that can be used to help us obtain better model hyperparameters.
### 1.1 Grid search
### Grid search
For grid search, which is also called exhaustive search, the optimal value is determined by finding the best solution from all solutions in the search space. The method is simple and effective, but when the search space is large, it takes huge computing resource.
For grid search, which is also called exhaustive search, the optimal value is determined by finding the best solution from all solutions in the search space. The method is simple and effective, but when the search space is large, it takes huge computing resource.
### 1.2 Bayesian search
### Bayesian search
Bayesian search, which is also called Bayesian optimization, is realized by randomly selecting a group of hyperparameters in the search space. Gaussian process is used to update the hyperparameters, compute their expected mean and variance according to the performance of the previous hyperparameters. The larger the expected mean, the greater the probability of being close to the optimal solution. The larger the expected variance, the greater the uncertainty. Usually, the hyperparameter point with large expected mean is called `exporitation`, and the hyperparameter point with large variance is called `exploration`. Acquisition function is defined to balance the expected mean and variance. The currently selected hyperparameter point is viewed as the optimal position with maximum probability.
Bayesian search, which is also called Bayesian optimization, is realized by randomly selecting a group of hyperparameters in the search space. Gaussian process is used to update the hyperparameters, compute their expected mean and variance according to the performance of the previous hyperparameters. The larger the expected mean, the greater the probability of being close to the optimal solution. The larger the expected variance, the greater the uncertainty. Usually, the hyperparameter point with large expected mean is called `exporitation`, and the hyperparameter point with large variance is called `exploration`. Acquisition function is defined to balance the expected mean and variance. The currently selected hyperparameter point is viewed as the optimal position with maximum probability.
...
@@ -55,7 +55,7 @@ It takes 196 times for grid search, and takes 10 times less for Bayesian search.
...
@@ -55,7 +55,7 @@ It takes 196 times for grid search, and takes 10 times less for Bayesian search.
- The above experiments verify that Bayesian search only reduces the accuracy by 0% to 0.4% under the condition of reducing the number of searches by about 10 times compared to grid search.
- The above experiments verify that Bayesian search only reduces the accuracy by 0% to 0.4% under the condition of reducing the number of searches by about 10 times compared to grid search.
- The search space can be expaned easily using Bayesian search.
- The search space can be expaned easily using Bayesian search.
## 二、 Large-scale image classification
## Large-scale image classification
In practical applications, due to the lack of training data, the classification model trained on the ImageNet1k data set is often used as the pretrained model for other image classification tasks. In order to further help solve practical problems, based on ResNet50_vd, Baidu open sourced a self-developed large-scale classification pretrained model, in which the training data contains 100,000 categories and 43 million pictures.
In practical applications, due to the lack of training data, the classification model trained on the ImageNet1k data set is often used as the pretrained model for other image classification tasks. In order to further help solve practical problems, based on ResNet50_vd, Baidu open sourced a self-developed large-scale classification pretrained model, in which the training data contains 100,000 categories and 43 million pictures.
Models for Paddle are stored in many different forms, which can be roughly divided into two categories:
Models for Paddle are stored in many different forms, which can be roughly divided into two categories:
1. persistable model(the models saved by fluid.save_persistables)
1. persistable model(the models saved by fluid.save_persistables)
...
@@ -54,7 +54,7 @@ Regardless of the inference method, it basically includes the following main ste
...
@@ -54,7 +54,7 @@ Regardless of the inference method, it basically includes the following main ste
There are two main differences in different inference methods: building the engine and executing the forecast. The following sections will be introduced in detail
There are two main differences in different inference methods: building the engine and executing the forecast. The following sections will be introduced in detail
## II. Model Transformation
## Model Transformation
During training, we usually save some checkpoints (persistable models). These are just model weight files and cannot be directly loaded by the prediction engine to predict, so we usually find suitable checkpoints after the training and convert them to inference model. There are two main steps: 1. Build a training engine, 2. Save the inference model, as shown below.
During training, we usually save some checkpoints (persistable models). These are just model weight files and cannot be directly loaded by the prediction engine to predict, so we usually find suitable checkpoints after the training and convert them to inference model. There are two main steps: 1. Build a training engine, 2. Save the inference model, as shown below.
...
@@ -95,7 +95,7 @@ python tools/export_model.py \
...
@@ -95,7 +95,7 @@ python tools/export_model.py \
--o=thesavedpathofmodelandparams
--o=thesavedpathofmodelandparams
```
```
## III. prediction engine + inference model
## Prediction engine + inference model
The complete example is provided in the `tools/infer/predict.py`,just execute the following command to complete the prediction:
The complete example is provided in the `tools/infer/predict.py`,just execute the following command to complete the prediction:
...
@@ -161,7 +161,7 @@ More parameters information can be refered in [Paddle Python prediction API](htt
...
@@ -161,7 +161,7 @@ More parameters information can be refered in [Paddle Python prediction API](htt
By default, Paddle's wheel package does not include the TensorRT prediction engine. If you need to use TensorRT for prediction optimization, you need to compile the corresponding wheel package yourself. For the compilation method, please refer to Paddle's compilation guide. [Paddle compilation](https://www.paddlepaddle.org.cn/documentation/docs/zh/install/compile/fromsource.html)。
By default, Paddle's wheel package does not include the TensorRT prediction engine. If you need to use TensorRT for prediction optimization, you need to compile the corresponding wheel package yourself. For the compilation method, please refer to Paddle's compilation guide. [Paddle compilation](https://www.paddlepaddle.org.cn/documentation/docs/zh/install/compile/fromsource.html)。
## IV、Training engine + persistable model prediction
## Training engine + persistable model prediction
A complete example is provided in the `tools/infer/infer.py`, just execute the following command to complete the prediction:
A complete example is provided in the `tools/infer/infer.py`, just execute the following command to complete the prediction:
...
@@ -212,7 +212,7 @@ outputs = exe.run(infer_prog,
...
@@ -212,7 +212,7 @@ outputs = exe.run(infer_prog,
For the above parameter descriptions, please refer to the official website [fluid.Executor](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/executor_cn/Executor_cn.html)
For the above parameter descriptions, please refer to the official website [fluid.Executor](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/executor_cn/Executor_cn.html)
## V、training engine + inference model prediction
## Training engine + inference model prediction
A complete example is provided in `tools/infer/py_infer.py`, just execute the following command to complete the prediction:
A complete example is provided in `tools/infer/py_infer.py`, just execute the following command to complete the prediction:
[Paddle-Lite](https://github.com/PaddlePaddle/Paddle-Lite) is a set of lightweight inference engine which is fully functional, easy to use and then performs well. Lightweighting is reflected in the use of fewer bits to represent the weight and activation of the neural network, which can greatly reduce the size of the model, solve the problem of limited storage space of the mobile device, and the inference speed is better than other frameworks on the whole.
[Paddle-Lite](https://github.com/PaddlePaddle/Paddle-Lite) is a set of lightweight inference engine which is fully functional, easy to use and then performs well. Lightweighting is reflected in the use of fewer bits to represent the weight and activation of the neural network, which can greatly reduce the size of the model, solve the problem of limited storage space of the mobile device, and the inference speed is better than other frameworks on the whole.
In [PaddleClas](https://github.com/PaddlePaddle/PaddleClas), we uses Paddle-Lite to [evaluate the performance on the mobile device](../models/Mobile.md), in this section we uses the `MobileNetV1` model trained on the `ImageNet1k` dataset as an example to introduce how to use `Paddle-Lite` to evaluate the model speed on the mobile terminal (evaluated on SD855)
In [PaddleClas](https://github.com/PaddlePaddle/PaddleClas), we uses Paddle-Lite to [evaluate the performance on the mobile device](../models/Mobile.md), in this section we uses the `MobileNetV1` model trained on the `ImageNet1k` dataset as an example to introduce how to use `Paddle-Lite` to evaluate the model speed on the mobile terminal (evaluated on SD855)
## II. Evaluation Steps
## Evaluation Steps
### I. Export the Inference Model
### Export the Inference Model
* First you should transform the saved model during training to the special model which can be used to inference, the special model can be exported by `tools/export_model.py`, the specific way of transform is as follows.
* First you should transform the saved model during training to the special model which can be used to inference, the special model can be exported by `tools/export_model.py`, the specific way of transform is as follows.
Finally the `model` and `parmas` can be saved in `inference/MobileNetV1`.
Finally the `model` and `parmas` can be saved in `inference/MobileNetV1`.
### II. Download Benchmark Binary File
### Download Benchmark Binary File
* Use the adb (Android Debug Bridge) tool to connect the Android phone and the PC, then develop and debug. After installing adb and ensuring that the PC and the phone are successfully connected, use the following command to view the ARM version of the phone and select the pre-compiled library based on ARM version.
* Use the adb (Android Debug Bridge) tool to connect the Android phone and the PC, then develop and debug. After installing adb and ensuring that the PC and the phone are successfully connected, use the following command to view the ARM version of the phone and select the pre-compiled library based on ARM version.
...
@@ -39,7 +39,7 @@ If the ARM version is v7, the v7 benchmark_bin file should be downloaded, the co
...
@@ -39,7 +39,7 @@ If the ARM version is v7, the v7 benchmark_bin file should be downloaded, the co
After the PC and mobile phone are successfully connected, use the following command to start the model evaluation.
After the PC and mobile phone are successfully connected, use the following command to start the model evaluation.
...
@@ -63,7 +63,7 @@ MobileNetV1 min = 10.03200 max = 9.94300 averag
...
@@ -63,7 +63,7 @@ MobileNetV1 min = 10.03200 max = 9.94300 averag
Here is the model inference speed under different number of threads, the unit is FPS, taking model on one threads as an example, the average speed of MobileNetV1 on SD855 is `30.79750FPS`.
Here is the model inference speed under different number of threads, the unit is FPS, taking model on one threads as an example, the average speed of MobileNetV1 on SD855 is `30.79750FPS`.
### IV. Model Optimization and Speed Evaluation
### Model Optimization and Speed Evaluation
* In II.III section, we mention that the model will be optimized before evaluation, here you can first optimize the model, and then directly load the optimized model for speed evaluation
* In II.III section, we mention that the model will be optimized before evaluation, here you can first optimize the model, and then directly load the optimized model for speed evaluation
[Paddle Serving](https://github.com/PaddlePaddle/Serving) aims to help deep-learning researchers to easily deploy online inference services, supporting one-click deployment of industry, high concurrency and efficient communication between client and server and supporting multiple programming languages to develop clients.
[Paddle Serving](https://github.com/PaddlePaddle/Serving) aims to help deep-learning researchers to easily deploy online inference services, supporting one-click deployment of industry, high concurrency and efficient communication between client and server and supporting multiple programming languages to develop clients.
Taking HTTP inference service deployment as an example to introduce how to use PaddleServing to deploy model services in PaddleClas.
Taking HTTP inference service deployment as an example to introduce how to use PaddleServing to deploy model services in PaddleClas.
## II. Serving Install
## Serving Install
It is recommends to use docker to install and deploy the Serving environment in the Serving official website, first, you need to pull the docker environment and create Serving-based docker.
It is recommends to use docker to install and deploy the Serving environment in the Serving official website, first, you need to pull the docker environment and create Serving-based docker.
`9292` is the port for sending the request, which is consistent with the Serving starting port, and `./docs/images/logo.png` is the test image, the final top1 label and probability are returned.
`9292` is the port for sending the request, which is consistent with the Serving starting port, and `./docs/images/logo.png` is the test image, the final top1 label and probability are returned.
* For more Serving deployment, such RPC inference service, you can refer to the Serving official website: [https://github.com/PaddlePaddle/Serving/tree/develop/python/examples/imagenet](https://github.com/PaddlePaddle/Serving/tree/develop/python/examples/imagenet)
* For more Serving deployment, such RPC inference service, you can refer to the Serving official website: [https://github.com/PaddlePaddle/Serving/tree/develop/python/examples/imagenet](https://github.com/PaddlePaddle/Serving/tree/develop/python/examples/imagenet)
Since the development of deep learning, there have been many researchers working on the optimizer. The purpose of the optimizer is to make the loss function as small as possible, so as to find suitable parameters to complete a certain task. At present, the main optimizers used in model training are SGD, RMSProp, Adam, AdaDelt and so on. The SGD optimizers with momentum is widely used in academia and industry, so most of models we release are trained by SGD optimizer with momentum. But the SGD optimizer with momentum has two disadvantages, one is that the convergence speed is slow, the other is that the initial learning rate is difficult to set, however, if the initial learning rate is set properly and the models are trained in sufficient iterations, the models trained by SGD with momentum can reach higher accuracy compared with the models trained by other optimizers. Some other optimizers with adaptive learning rate such as Adam, RMSProp and so on tent to converge faster, but the final convergence accuracy will be slightly worse. If you want to train a model in faster convergence speed, we recommend you use the optimizers with adaptive learning rate, but if you want to train a model with higher accuracy, we recommend you to use SGD optimizer with momentum.
Since the development of deep learning, there have been many researchers working on the optimizer. The purpose of the optimizer is to make the loss function as small as possible, so as to find suitable parameters to complete a certain task. At present, the main optimizers used in model training are SGD, RMSProp, Adam, AdaDelt and so on. The SGD optimizers with momentum is widely used in academia and industry, so most of models we release are trained by SGD optimizer with momentum. But the SGD optimizer with momentum has two disadvantages, one is that the convergence speed is slow, the other is that the initial learning rate is difficult to set, however, if the initial learning rate is set properly and the models are trained in sufficient iterations, the models trained by SGD with momentum can reach higher accuracy compared with the models trained by other optimizers. Some other optimizers with adaptive learning rate such as Adam, RMSProp and so on tent to converge faster, but the final convergence accuracy will be slightly worse. If you want to train a model in faster convergence speed, we recommend you use the optimizers with adaptive learning rate, but if you want to train a model with higher accuracy, we recommend you to use SGD optimizer with momentum.
## 2.the Choice of Learning Rate and Learning Rate Declining Strategy:
## Choice of Learning Rate and Learning Rate Declining Strategy:
The choice of learning rate is related to the optimizer, data set and tasks. Here we mainly introduce the learning rate of training ImageNet-1K with momentum + SGD as the optimizer and the choice of learning rate decline.
The choice of learning rate is related to the optimizer, data set and tasks. Here we mainly introduce the learning rate of training ImageNet-1K with momentum + SGD as the optimizer and the choice of learning rate decline.
### the Concept of Learning Rate:
### Concept of Learning Rate:
the learning rate is the hyperparameter to control the learning speed, the lower the learning rate, the slower the change of the loss value, though using a low learning rate can ensure that you will not miss any local minimum, but it also means that the convergence speed is slow, especially when the gradient is trapped in a gradient plateau area.
the learning rate is the hyperparameter to control the learning speed, the lower the learning rate, the slower the change of the loss value, though using a low learning rate can ensure that you will not miss any local minimum, but it also means that the convergence speed is slow, especially when the gradient is trapped in a gradient plateau area.
### Learning Rate Decline Strategy:
### Learning Rate Decline Strategy:
...
@@ -19,10 +19,10 @@ In addition, we can also see from the figures that the number of epoches with a
...
@@ -19,10 +19,10 @@ In addition, we can also see from the figures that the number of epoches with a
### Warmup Strategy
### Warmup Strategy
If a large batch_size is adopted to train nerual network, we recommend you to adopt warmup strategy. as the name suggests, the warmup strategy is to let model learning first warm up, we do not directly use the initial learning rate at the begining of training, instead, we use a gradually increasing learning rate to train the model, when the increasing learning rate reaches the initial learning rate, the learning rate reduction method mentioned in the learning rate reduction strategy is then used to decay the learning rate. Experiments show that when the batch size is large, warmup strategy can improve the accuracy. Some model training with large batch_size such as MobileNetV3 training, we set the epoch in warmup to 5 by default, that is, first in 5 epoches, the learning rate increases from 0 to initial learning rate, then learning rate decay begins.
If a large batch_size is adopted to train nerual network, we recommend you to adopt warmup strategy. as the name suggests, the warmup strategy is to let model learning first warm up, we do not directly use the initial learning rate at the begining of training, instead, we use a gradually increasing learning rate to train the model, when the increasing learning rate reaches the initial learning rate, the learning rate reduction method mentioned in the learning rate reduction strategy is then used to decay the learning rate. Experiments show that when the batch size is large, warmup strategy can improve the accuracy. Some model training with large batch_size such as MobileNetV3 training, we set the epoch in warmup to 5 by default, that is, first in 5 epoches, the learning rate increases from 0 to initial learning rate, then learning rate decay begins.
## 3.the Choice of Batch_size
## Choice of Batch_size
Batch_size is an important hyperparameter in training neural networks, batch_size determines how much data is sent to the neural network to for training at a time. In the paper [1], the author found in experiments that when batch_size is linearly related to the learning rate, the convergence accuracy is hardly affected. When training ImageNet data, an initial learning rate of 0.1 are commonly chosen for training, and batch_size is 256, so according to the actual model size and memory, you can set the learning rate to 0.1\*k, batch_size to 256\*k.
Batch_size is an important hyperparameter in training neural networks, batch_size determines how much data is sent to the neural network to for training at a time. In the paper [1], the author found in experiments that when batch_size is linearly related to the learning rate, the convergence accuracy is hardly affected. When training ImageNet data, an initial learning rate of 0.1 are commonly chosen for training, and batch_size is 256, so according to the actual model size and memory, you can set the learning rate to 0.1\*k, batch_size to 256\*k.
## 4.the Choice of Weight_decay
## Choice of Weight_decay
Overfitting is a common term in machine learning. A simple understanding is that the model performs well on the training data, but it performs poorly on the test data. In the convolutional neural network, there also exists the problem of overfitting. To avoid overfitting, many regular ways have been proposed. Among them, weight_decay is one of the widely used ways to avoid overfitting. After the final loss function, L2 regularization(weight_decay) is added to the loss function, with the help of L2 regularization, the weight of the network tend to choose a smaller value, and finally the parameters in the entire network tends to 0, and the generalization performance of the model is improved accordingly. In different kinds of Deep learning frame, the meaning of L2_decay is the coefficient of L2 regularization, on paddle, the name of this value is L2_decay, so in the following the value is called L2_decay. the larger the coefficient, the more the model tends to be underfitting. In the task of training ImageNet, this parameter is set to 1e-4 in most network. In some small networks such as MobileNet networks, in order to avoid network underfitting, the value is set to 1e-5 ~ 4e-5. Of course, the setting of this value is also related to the specific data set, When the data set is large, the network itself tends to be under-fitted, and the value can be appropriately reduced. When the data set is small, the network tends to overfit itself, so the value can be increased appropriately. The following table shows the accuracy of MobileNetV1_x0_25 using different l2_decay on ImageNet-1k. Since MobileNetV1_x0_25 is a relatively small network, the large l2_decay will make the network tend to be underfitting, so in this network, 3e-5 are better choices compared with 1e-4.
Overfitting is a common term in machine learning. A simple understanding is that the model performs well on the training data, but it performs poorly on the test data. In the convolutional neural network, there also exists the problem of overfitting. To avoid overfitting, many regular ways have been proposed. Among them, weight_decay is one of the widely used ways to avoid overfitting. After the final loss function, L2 regularization(weight_decay) is added to the loss function, with the help of L2 regularization, the weight of the network tend to choose a smaller value, and finally the parameters in the entire network tends to 0, and the generalization performance of the model is improved accordingly. In different kinds of Deep learning frame, the meaning of L2_decay is the coefficient of L2 regularization, on paddle, the name of this value is L2_decay, so in the following the value is called L2_decay. the larger the coefficient, the more the model tends to be underfitting. In the task of training ImageNet, this parameter is set to 1e-4 in most network. In some small networks such as MobileNet networks, in order to avoid network underfitting, the value is set to 1e-5 ~ 4e-5. Of course, the setting of this value is also related to the specific data set, When the data set is large, the network itself tends to be under-fitted, and the value can be appropriately reduced. When the data set is small, the network tends to overfit itself, so the value can be increased appropriately. The following table shows the accuracy of MobileNetV1_x0_25 using different l2_decay on ImageNet-1k. Since MobileNetV1_x0_25 is a relatively small network, the large l2_decay will make the network tend to be underfitting, so in this network, 3e-5 are better choices compared with 1e-4.
| Model | L2_decay | Train acc1/acc5 | Test acc1/acc5 |
| Model | L2_decay | Train acc1/acc5 | Test acc1/acc5 |
...
@@ -39,7 +39,7 @@ In addition, the setting of L2_decay is also related to whether other regulariza
...
@@ -39,7 +39,7 @@ In addition, the setting of L2_decay is also related to whether other regulariza
In summary, l2_decay can be adjusted according to specific tasks and models. Usually simple tasks or larger models are recommended to use Larger l2_decay, complex tasks or smaller models are recommended to use smaller l2_decay.
In summary, l2_decay can be adjusted according to specific tasks and models. Usually simple tasks or larger models are recommended to use Larger l2_decay, complex tasks or smaller models are recommended to use smaller l2_decay.
## 5. the Choice of Label_smoothing
## Choice of Label_smoothing
Label_smoothing is a regularization method in deep learning. Its full name is Label Smoothing Regularization (LSR), that is, label smoothing regularization. In the traditional classification task, when calculating the loss function, the real one hot label and the output of the neural network are calculated in cross-entropy formula, the label smoothing aims to make the real one hot label become smooth label, which makes the neural network no longer learn from the hard labels, but the soft labels with a probability value, where the probability of the position corresponding to the category is the largest and the probability of other positions are very small value, specific calculation method can be seen in the paper[2]. In label-smoothing, there is an epsilon parameter describing the degree of softening the label. The larger epsilon, the smaller the probability and smoother the label, on the contrary, the label tends to be hard label. during training on ImageNet-1K, the parameter is usually set to 0.1. In the experiments of training ResNet50, when using label_smoothing, the accuracy is higher than the one without label_smoothing, the following table shows the performance of ResNet50_vd with label smoothing and without label smoothing.
Label_smoothing is a regularization method in deep learning. Its full name is Label Smoothing Regularization (LSR), that is, label smoothing regularization. In the traditional classification task, when calculating the loss function, the real one hot label and the output of the neural network are calculated in cross-entropy formula, the label smoothing aims to make the real one hot label become smooth label, which makes the neural network no longer learn from the hard labels, but the soft labels with a probability value, where the probability of the position corresponding to the category is the largest and the probability of other positions are very small value, specific calculation method can be seen in the paper[2]. In label-smoothing, there is an epsilon parameter describing the degree of softening the label. The larger epsilon, the smaller the probability and smoother the label, on the contrary, the label tends to be hard label. during training on ImageNet-1K, the parameter is usually set to 0.1. In the experiments of training ResNet50, when using label_smoothing, the accuracy is higher than the one without label_smoothing, the following table shows the performance of ResNet50_vd with label smoothing and without label smoothing.
| Model | Use_label_smoothing | Test acc1 |
| Model | Use_label_smoothing | Test acc1 |
...
@@ -57,7 +57,7 @@ But, because label smoothing can be regarded as a regular way, on relatively sma
...
@@ -57,7 +57,7 @@ But, because label smoothing can be regarded as a regular way, on relatively sma
In summary, the use of label_smoohing for larger models can effectively improve the accuracy of the model, and the use of label_smoohing for smaller models may reduce the accuracy of the model, so before deciding whether to use label_smoohing, you need to evaluate the size of the model and the difficulty of the task.
In summary, the use of label_smoohing for larger models can effectively improve the accuracy of the model, and the use of label_smoohing for smaller models may reduce the accuracy of the model, so before deciding whether to use label_smoohing, you need to evaluate the size of the model and the difficulty of the task.
## 6.Change the Crop Area and Stretch Transformation Degree of the Images for Small Models
## Change the Crop Area and Stretch Transformation Degree of the Images for Small Models
In the standard preprocessing of ImageNet-1k data, two values of scale and ratio are defined in the random_crop function. These two values respectively determine the size of the image crop and the degree of stretching of the image. The default value of scale is 0.08-1(lower_scale-upper_scale), the default value range of ratio is 3/4-4/3(lower_ratio-upper_ratio). In small network training, such data argument will make the network underfitting, resulting in a decrease in accuracy. In order to improve the accuracy of the network, you can make the data argument weaker, that is, increase the crop area of the images or weaken the degree of stretching and transformation of the images, we can achieve weaker image transformation by increasing the value of lower_scale or narrowing the gap between lower_ratio and upper_scale. The following table lists the accuracy of training MobileNetV2_x0_25 with different lower_scale. It can be seen that the training accuracy and validation accuracy are improved after increasing the crop area of the images
In the standard preprocessing of ImageNet-1k data, two values of scale and ratio are defined in the random_crop function. These two values respectively determine the size of the image crop and the degree of stretching of the image. The default value of scale is 0.08-1(lower_scale-upper_scale), the default value range of ratio is 3/4-4/3(lower_ratio-upper_ratio). In small network training, such data argument will make the network underfitting, resulting in a decrease in accuracy. In order to improve the accuracy of the network, you can make the data argument weaker, that is, increase the crop area of the images or weaken the degree of stretching and transformation of the images, we can achieve weaker image transformation by increasing the value of lower_scale or narrowing the gap between lower_ratio and upper_scale. The following table lists the accuracy of training MobileNetV2_x0_25 with different lower_scale. It can be seen that the training accuracy and validation accuracy are improved after increasing the crop area of the images
| Model | Scale Range | Train_acc1/acc5 | Test_acc1/acc5 |
| Model | Scale Range | Train_acc1/acc5 | Test_acc1/acc5 |
...
@@ -65,7 +65,7 @@ In the standard preprocessing of ImageNet-1k data, two values of scale and ratio
...
@@ -65,7 +65,7 @@ In the standard preprocessing of ImageNet-1k data, two values of scale and ratio
In general, the size of the data set is critical to the performances, but the annotation of images are often more expensive, so the number of annotated images are often scarce. In this case, the data argument is particularly important. In the standard data augmentation for training on ImageNet-1k, two data augmentation methods which are random_crop and random_flip are mainly used. However, in recent years, more and more data augmentation methods have been proposed, such as cutout, mixup, cutmix, AutoAugment, etc. Experiments show that these data augmentation methods can effectively improve the accuracy of the model. The following table lists the performance of ResNet50 in 8 different data augmentation methods. It can be seen that compared to the baseline, all data augmentation methods can be useful for the accuracy of ResNet50, among them cutmix is currently the most effective data argument. More data argument can be seen here[**Data Argument**](https://paddleclas.readthedocs.io/zh_CN/latest/advanced_tutorials/image_augmentation/ImageAugment.html).
In general, the size of the data set is critical to the performances, but the annotation of images are often more expensive, so the number of annotated images are often scarce. In this case, the data argument is particularly important. In the standard data augmentation for training on ImageNet-1k, two data augmentation methods which are random_crop and random_flip are mainly used. However, in recent years, more and more data augmentation methods have been proposed, such as cutout, mixup, cutmix, AutoAugment, etc. Experiments show that these data augmentation methods can effectively improve the accuracy of the model. The following table lists the performance of ResNet50 in 8 different data augmentation methods. It can be seen that compared to the baseline, all data augmentation methods can be useful for the accuracy of ResNet50, among them cutmix is currently the most effective data argument. More data argument can be seen here[**Data Argument**](https://paddleclas.readthedocs.io/zh_CN/latest/advanced_tutorials/image_augmentation/ImageAugment.html).
| Model | Data Argument | Test top-1 |
| Model | Data Argument | Test top-1 |
...
@@ -80,10 +80,10 @@ In general, the size of the data set is critical to the performances, but the an
...
@@ -80,10 +80,10 @@ In general, the size of the data set is critical to the performances, but the an
| ResNet50 | Random-Erasing | 77.91% |
| ResNet50 | Random-Erasing | 77.91% |
| ResNet50 | Hide-and-Seek | 77.43% |
| ResNet50 | Hide-and-Seek | 77.43% |
## 8. Determine the Tuning Strategy by Train_acc and Test_acc
## Determine the Tuning Strategy by Train_acc and Test_acc
In the process of training the network, the training set accuracy rate and validation set accuracy rate of each epoch are usually printed. Generally speaking, the accuracy of the training set is slightly higher than the accuracy of the validation set or the same are good state in training, but if you find that the accuracy of training set is much higher than the one of validation set, it means that overfitting happens in your task, which need more regularization, such as increase the value of L2_decay, using more data argument or label smoothing and so on. If you find that the accuracy of training set is lower than the one of validation set, it means that underfitting happens in your task, which recommend you to decrease the value of L2_decay, using fewer data argument, increase the area of the crop area of the images, weaken the stretching transformation of the images, remove label_smoothing, etc.
In the process of training the network, the training set accuracy rate and validation set accuracy rate of each epoch are usually printed. Generally speaking, the accuracy of the training set is slightly higher than the accuracy of the validation set or the same are good state in training, but if you find that the accuracy of training set is much higher than the one of validation set, it means that overfitting happens in your task, which need more regularization, such as increase the value of L2_decay, using more data argument or label smoothing and so on. If you find that the accuracy of training set is lower than the one of validation set, it means that underfitting happens in your task, which recommend you to decrease the value of L2_decay, using fewer data argument, increase the area of the crop area of the images, weaken the stretching transformation of the images, remove label_smoothing, etc.
## 9.Improve the Accuracy of Your Own Data Set with Existing Pre-trained Models
## Improve the Accuracy of Your Own Data Set with Existing Pre-trained Models
In the field of computer vision, it has become common to load pre-trained models to train one's own tasks. Compared with starting training from random initialization, loading pre-trained models can often improve the accuracy of specific tasks. In general, the pre-trained model widely used in the industry is obtained from the ImageNet-1k dataset. The fc layer weight of the pre-trained model is a matrix of k\*1000, where k is The number of neurons before, and the weights of the fc layer is not need to load because of the different tasks. In terms of learning rate, if your training data set is particularly small (such as less than 1,000), we recommend that you use a smaller initial learning rate, such as 0.001 (batch_size: 256, the same below), to avoid a large learning rate undermine pre-training weights, if your training data set is relatively large (greater than 100,000), we recommend that you try a larger initial learning rate, such as 0.01 or greater.
In the field of computer vision, it has become common to load pre-trained models to train one's own tasks. Compared with starting training from random initialization, loading pre-trained models can often improve the accuracy of specific tasks. In general, the pre-trained model widely used in the industry is obtained from the ImageNet-1k dataset. The fc layer weight of the pre-trained model is a matrix of k\*1000, where k is The number of neurons before, and the weights of the fc layer is not need to load because of the different tasks. In terms of learning rate, if your training data set is particularly small (such as less than 1,000), we recommend that you use a smaller initial learning rate, such as 0.001 (batch_size: 256, the same below), to avoid a large learning rate undermine pre-training weights, if your training data set is relatively large (greater than 100,000), we recommend that you try a larger initial learning rate, such as 0.01 or greater.
{kind=link}
{kind=link}


{kind=link}
{kind=link}