Merge pull request #1363 from cuicheng01/release/2.3
Merge new docs to release/2.3
Showing

763.0 KB

35.9 KB
5.5 KB


41.8 KB
142.7 KB

37.4 KB
docs/zh_CN/Makefile
已删除
100644 → 0
此差异已折叠。
文件已移动
docs/zh_CN/conf.py
已删除
100644 → 0
docs/zh_CN/faq_series.md
已删除
100644 → 0

448.4 KB
文件已移动
docs/zh_CN/images/10w_cls.png
0 → 100644

208.9 KB
211.5 KB
898.6 KB

74.3 KB
763.0 KB
35.9 KB

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

7.4 KB
{kind=link}
55.4 KB
docs/zh_CN/images/det/pssdet.png
0 → 100644
{kind=link}
70.7 KB
{kind=link}

1.7 MB
{kind=link}

124.1 KB
{kind=link}
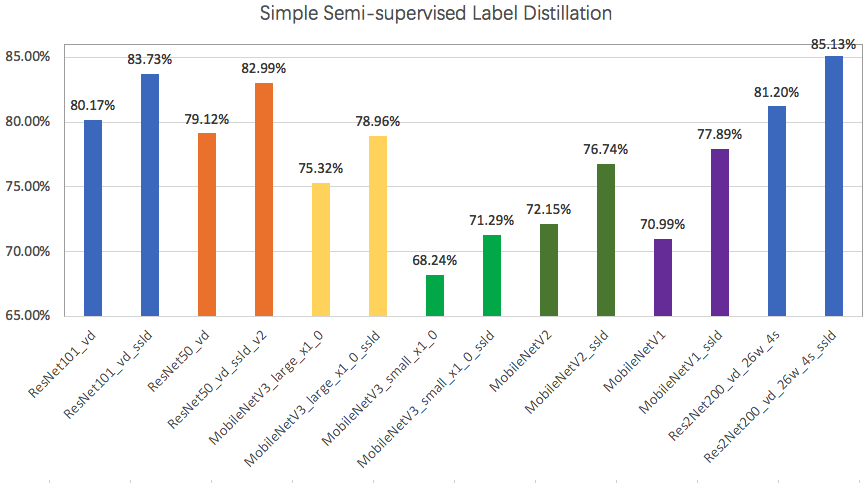
74.3 KB
{kind=link}
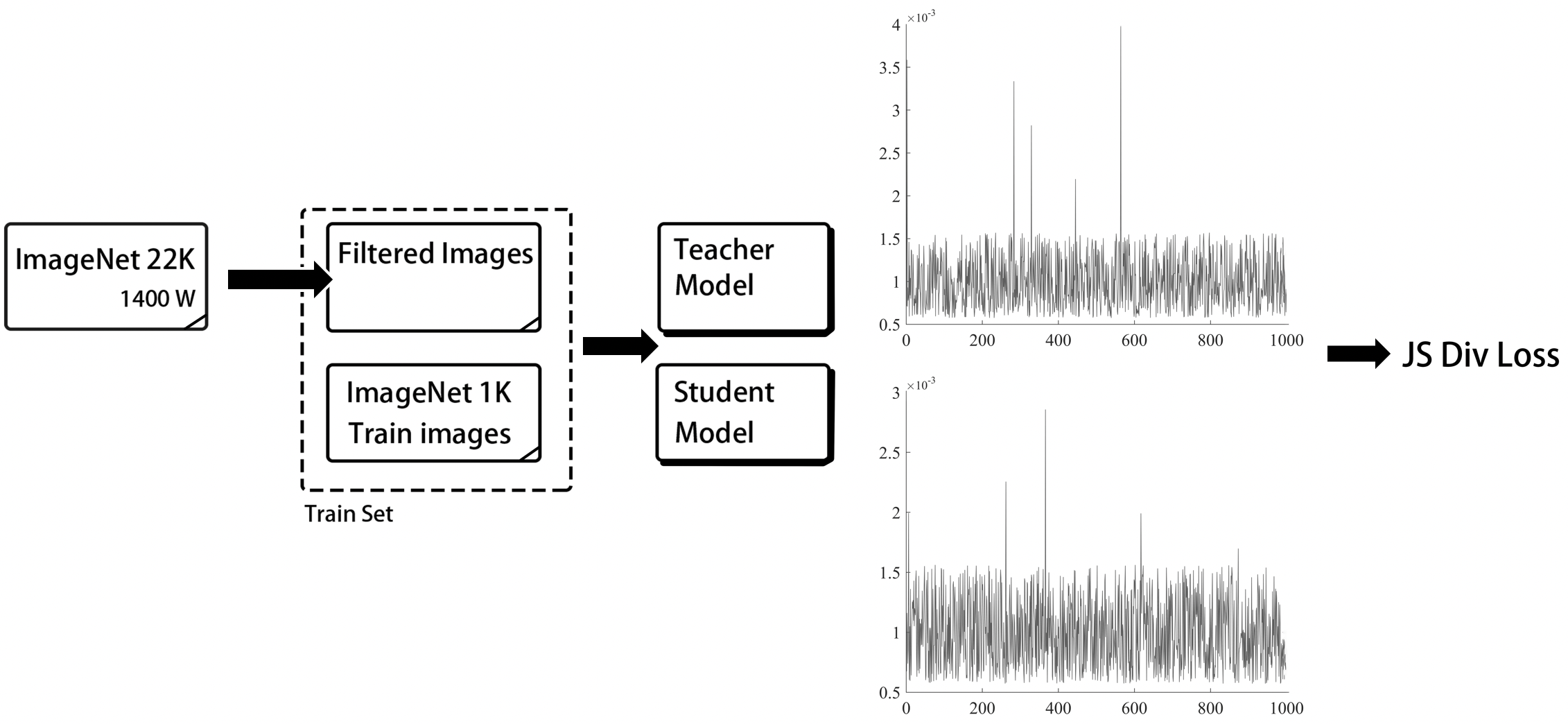
697.7 KB
{kind=link}
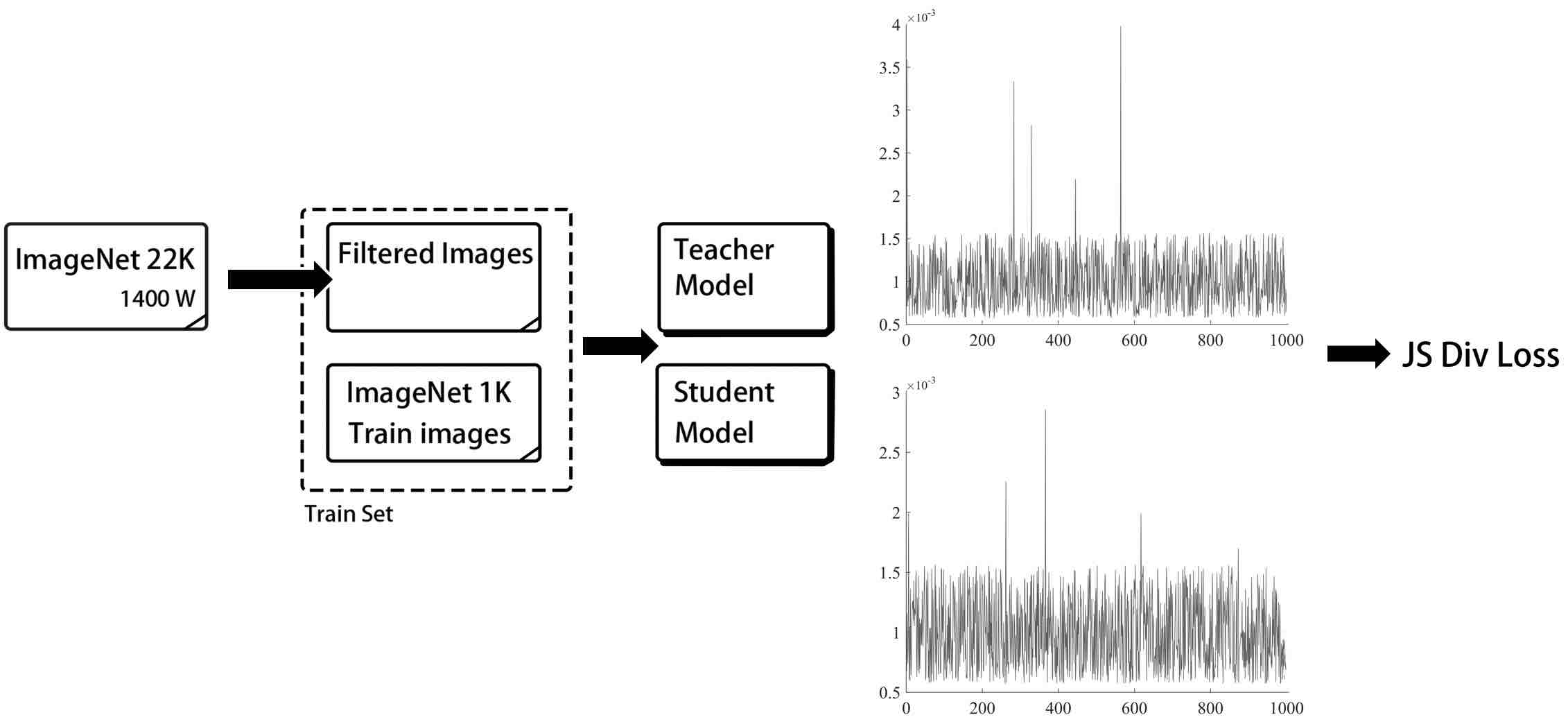
90.8 KB
{kind=link}
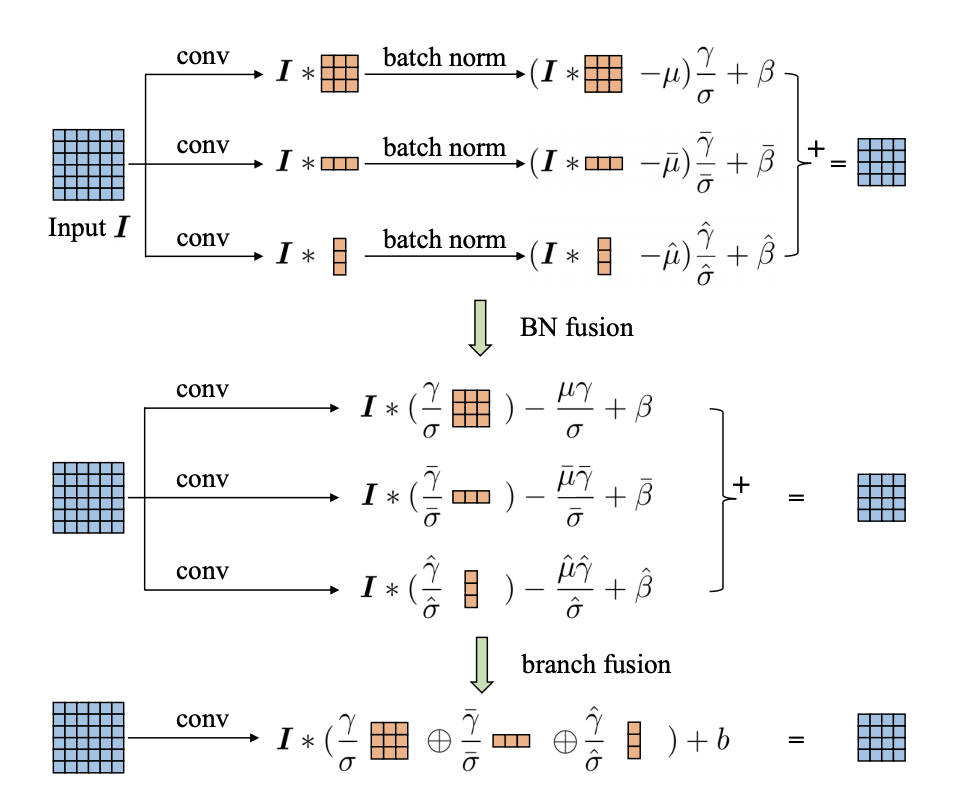
132.8 KB
{kind=link}

53.5 KB
{kind=link}
132.6 KB
docs/zh_CN/images/faq/HRNet.png
0 → 100644
{kind=link}
30.3 KB
{kind=link}

144.6 KB
{kind=link}
33.7 KB
{kind=link}

56.6 KB
docs/zh_CN/images/faq/RepVGG.png
0 → 100644
{kind=link}

106.3 KB
{kind=link}
161.9 KB
{kind=link}

89.3 KB
{kind=link}
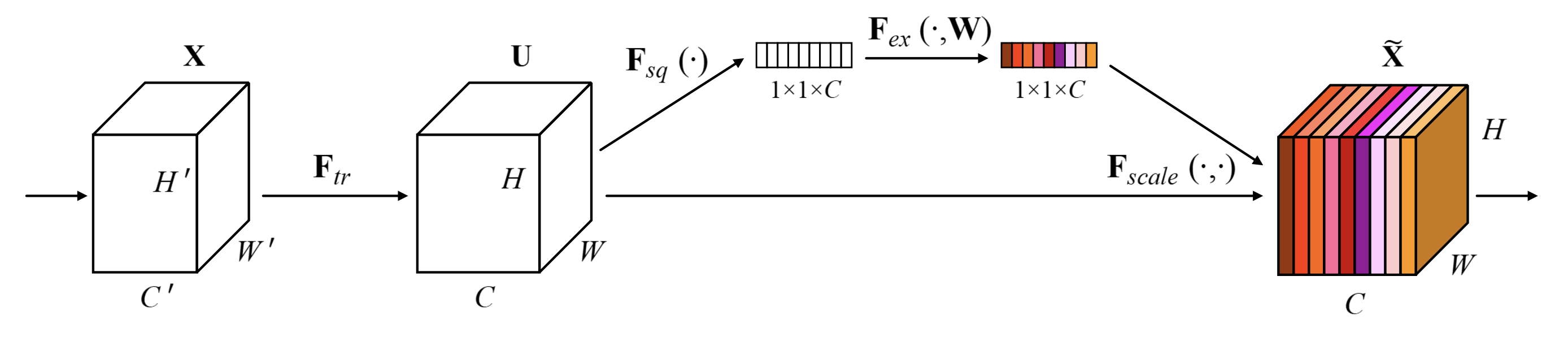
131.6 KB
{kind=link}

119.6 KB
{kind=link}
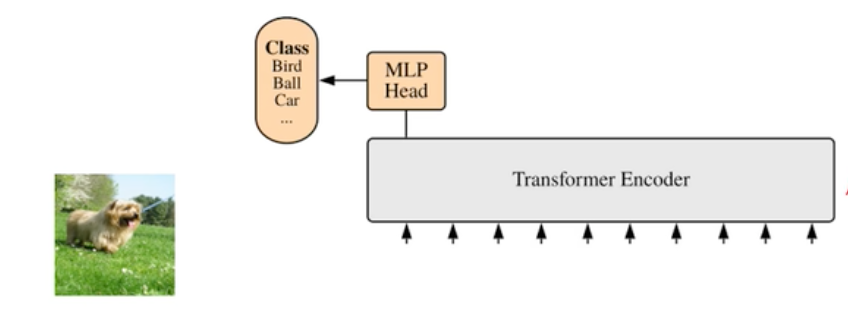
96.4 KB
docs/zh_CN/images/faq/ViT.png
0 → 100644
{kind=link}

23.3 KB
{kind=link}
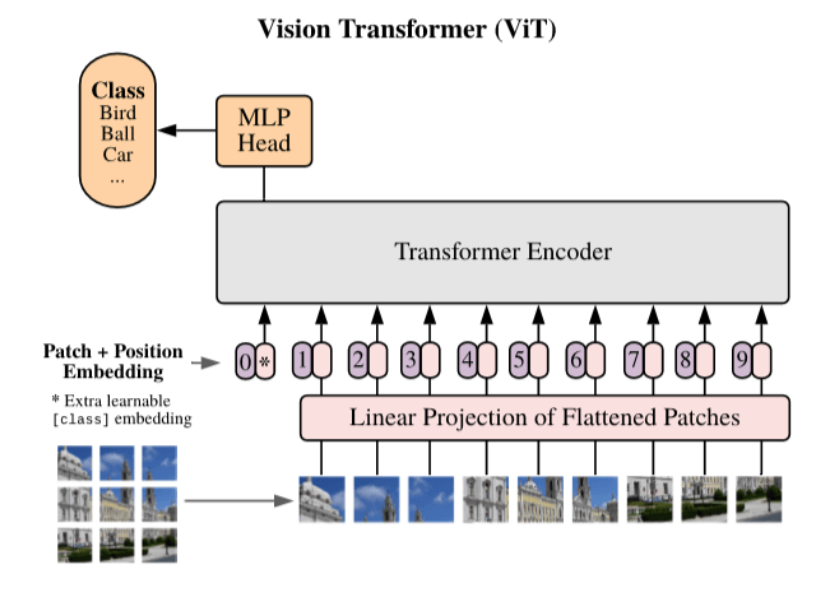
200.1 KB
{kind=link}

1.1 MB
{kind=link}

24.3 KB
{kind=link}

94.9 KB
docs/zh_CN/images/icartoon1.png
0 → 100644
{kind=link}

463.0 KB
docs/zh_CN/images/icartoon2.jpeg
0 → 100644
{kind=link}

21.0 KB
{kind=link}

288.9 KB
{kind=link}

336.4 KB
{kind=link}

313.3 KB
{kind=link}

86.9 KB
{kind=link}

1.3 MB
{kind=link}
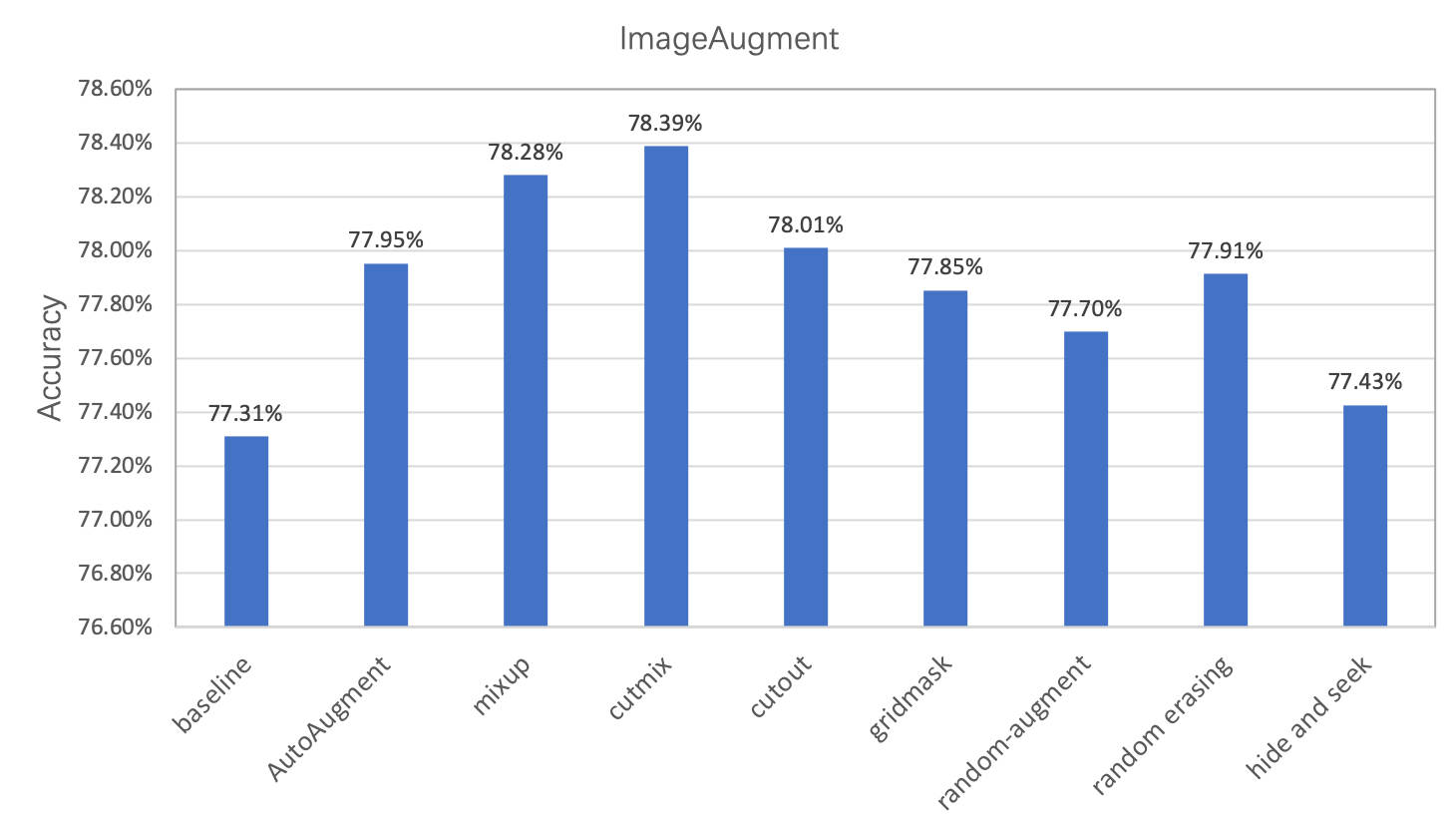
106.3 KB
{kind=link}

48.8 KB
{kind=link}

330.1 KB
{kind=link}

274.3 KB
{kind=link}

972.8 KB
{kind=link}

234.7 KB
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs/zh_CN/images/joinus.png
0 → 100644
{kind=link}
此差异已折叠。
docs/zh_CN/images/logo.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs/zh_CN/images/ml_pipeline.jpg
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs/zh_CN/images/qq_group.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs/zh_CN/images/recognition.gif
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs/zh_CN/images/structure.png
0 → 100644
{kind=link}
此差异已折叠。
docs/zh_CN/images/whl/demo.jpg
0 → 100644
{kind=link}
此差异已折叠。
docs/zh_CN/images/wx_group.png
0 → 100644
{kind=link}
此差异已折叠。
docs/zh_CN/index.rst
已删除
100644 → 0
此差异已折叠。
docs/zh_CN/inference.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
docs/zh_CN/make.bat
已删除
100644 → 0
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/zh_CN/others/versions.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/zh_CN/tutorials/data.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/zh_CN/whl.md
已删除
100644 → 0
此差异已折叠。