Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleClas
提交
e956ac88
P
PaddleClas
项目概览
PaddlePaddle
/
PaddleClas
大约 2 年 前同步成功
通知
118
Star
4999
Fork
1114
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
19
列表
看板
标记
里程碑
合并请求
6
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleClas
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
19
Issue
19
列表
看板
标记
里程碑
合并请求
6
合并请求
6
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
e956ac88
编写于
6月 10, 2022
作者:
C
cuicheng01
提交者:
GitHub
6月 10, 2022
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #1980 from RainFrost1/deploy_doc
update python inference doc
上级
f4020359
abfced46
变更
4
显示空白变更内容
内联
并排
Showing
4 changed file
with
97 addition
and
51 deletion
+97
-51
docs/images/algorithm_introduction/hnsw.png
docs/images/algorithm_introduction/hnsw.png
+0
-0
docs/zh_CN/image_recognition_pipeline/mainbody_detection.md
docs/zh_CN/image_recognition_pipeline/mainbody_detection.md
+26
-14
docs/zh_CN/image_recognition_pipeline/vector_search.md
docs/zh_CN/image_recognition_pipeline/vector_search.md
+56
-28
docs/zh_CN/inference_deployment/python_deploy.md
docs/zh_CN/inference_deployment/python_deploy.md
+15
-9
未找到文件。
docs/images/algorithm_introduction/hnsw.png
0 → 100644
浏览文件 @
e956ac88
72.5 KB
docs/zh_CN/image_recognition_pipeline/mainbody_detection.md
浏览文件 @
e956ac88
...
...
@@ -19,7 +19,11 @@
-
[
3.3 配置文件改动和说明
](
#3.3
)
-
[
3.4 启动训练
](
#3.4
)
-
[
3.5 模型预测与调试
](
#3.5
)
-
[
3.6 模型导出与预测部署
](
#3.6
)
-
[
4. 模型推理部署
](
#4
)
-
[
4.1 推理模型准备
](
#4.1
)
-
[
4.2 基于python预测引擎推理
](
#4.2
)
-
[
4.3 其他推理方式
](
#4.3
)
<a
name=
"1"
></a>
...
...
@@ -211,9 +215,11 @@ python tools/infer.py -c configs/ppyolo/ppyolov2_r50vd_dcn_365e_coco.yml --infer
`--draw_threshold`
是个可选参数. 根据
[
NMS
](
https://ieeexplore.ieee.org/document/1699659
)
的计算,不同阈值会产生不同的结果
`keep_top_k`
表示设置输出目标的最大数量,默认值为 100,用户可以根据自己的实际情况进行设定。
<a
name=
"3.6"
></a>
<a
name=
"4"
></a>
## 4. 模型推理部署
### 3.6 模型导出与预测部署。
<a
name=
"4.1"
></a>
### 4.1 推理模型准备
执行导出模型脚本:
...
...
@@ -225,15 +231,21 @@ python tools/export_model.py -c configs/ppyolo/ppyolov2_r50vd_dcn_365e_coco.yml
注意:
`PaddleDetection`
导出的 inference 模型的文件格式为
`model.xxx`
,这里如果希望与 PaddleClas 的 inference 模型文件格式保持一致,需要将其
`model.xxx`
文件修改为
`inference.xxx`
文件,用于后续主体检测的预测部署。
更多模型导出教程,请参考:
[
EXPORT_MODEL
](
https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.
1
/deploy/EXPORT_MODEL.md
)
更多模型导出教程,请参考:
[
EXPORT_MODEL
](
https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.
4
/deploy/EXPORT_MODEL.md
)
最终,目录
`inference/ppyolov2_r50vd_dcn_365e_coco`
中包含
`inference.pdiparams`
,
`inference.pdiparams.info`
以及
`inference.pdmodel`
文件,其中
`inference.pdiparams`
为保存的 inference 模型权重文件,
`inference.pdmodel`
为保存的 inference 模型结构文件。
<a
name=
"4.2"
></a>
### 4.2 基于python预测引擎推理
导出模型之后,在主体检测与识别任务中,就可以将检测模型的路径更改为该 inference 模型路径,完成预测。
以商品识别为例,其配置文件为
[
inference_product.yaml
](
../../../deploy/configs/inference_product.yaml
)
,修改其中的
`Global.det_inference_model_dir`
字段为导出的主体检测 inference 模型目录,参考
[
图像识别快速开始教程
](
../quick_start/quick_start_recognition.md
)
,即可完成商品检测与识别过程。
<a
name=
"4.3"
></a>
### 4.3 其他推理方式
其他推理方法,如C++推理部署、PaddleServing部署等请参考
[
检测模型推理部署
](
https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.4/deploy/README.md
)
。
### FAQ
...
...
docs/zh_CN/image_recognition_pipeline/vector_search.md
浏览文件 @
e956ac88
# 向量检索
## 目录
-
[
1. 向量检索应用场景介绍
](
#1
)
-
[
2. 向量检索算法介绍
](
#2
)
-
[
2.1 HNSW
](
#2.1
)
-
[
2.2 IVF
](
#2.2
)
-
[
2.3 FLAT
](
#2.3
)
-
[
3. 检索库安装
](
#3
)
-
[
4. 使用及配置文档介绍
](
#4
)
-
[
4.1 建库及配置文件参数
](
#4.1
)
-
[
4.2 检索配置文件参数
](
#4.2
)
<a
name=
"1"
></a>
## 1. 向量检索应用场景介绍
向量检索技术在图像识别、图像检索中应用比较广泛。其主要目标是,对于给定的查询向量,在已经建立好的向量库中,与库中所有的待查询向量,进行特征向量的相似度或距离计算,得到相似度排序。在图像识别系统中,我们使用
[
Faiss
](
https://github.com/facebookresearch/faiss
)
对此部分进行支持,具体信息请详查
[
Faiss 官网
](
https://github.com/facebookresearch/faiss
)
。
`Faiss`
主要有以下优势
-
适配性好:支持 Windos、Linux、MacOS 系统
...
...
@@ -20,17 +36,33 @@
--------------------------
## 目录
<a
name=
"2"
></a>
## 2. 使用的检索算法
-
[
1. 检索库安装
](
#1
)
-
[
2. 使用的检索算法
](
#2
)
-
[
3. 使用及配置文档介绍
](
#3
)
-
[
3.1 建库及配置文件参数
](
#3.1
)
-
[
3.2 检索配置文件参数
](
#3.2
)
目前
`PaddleClas`
中检索模块,支持三种检索算法
**HNSW32**
、
**IVF**
、
**FLAT**
。每种检索算法,满足不同场景。其中
`HNSW32`
为默认方法,此方法的检索精度、检索速度可以取得一个较好的平衡,具体算法介绍可以查看
[
官方文档
](
https://github.com/facebookresearch/faiss/wiki
)
。
<a
name=
"1"
></a>
<a
name=
"2.1"
></a>
### 2.1 HNSW方法
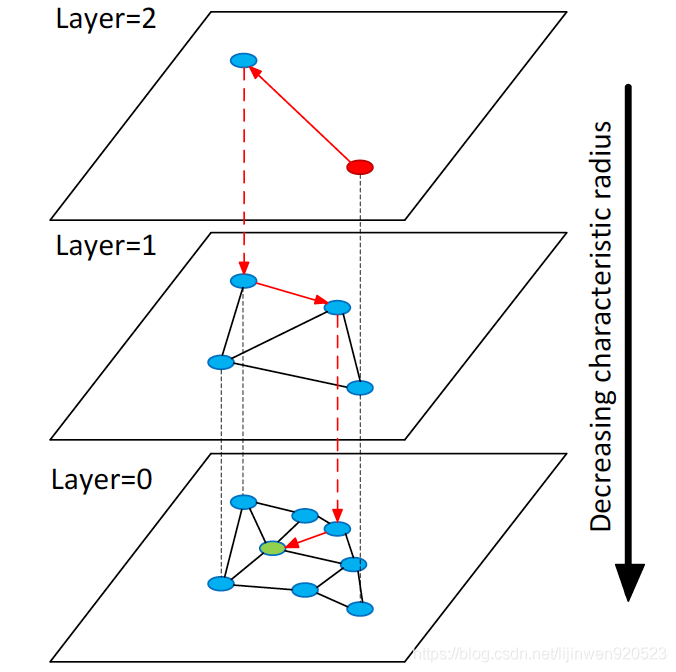
此方法为图索引方法,如下图所示,在建立索引的时候,分为不同的层,所以检索精度较高,速度较快,但是特征库只支持添加图像功能,不支持删除图像特征功能。基于图的向量检索算法在向量检索的评测中性能都是比较优异的。如果比较在乎检索算法的效率,而且可以容忍一定的空间成本,多数场景下比较推荐基于图的检索算法。而HNSW是一种典型的,应用广泛的图算法,很多分布式检索引擎都对HNSW算法进行了分布式改造,以应用于高并发,大数据量的线上查询。此方法为默认方法。
<div
align=
"center"
>
<img
src=
"../../images/algorithm_introduction/hnsw.png"
width =
"400"
/>
</div>
<a
name=
"2.2"
></a>
### 2.2 IVF
一种倒排索引检索方法。速度较快,但是精度略低。特征库支持增加、删除图像特征功能。IVF主要利用倒排的思想保存每个聚类中心下的向量,每次查询向量的时候找到最近的几个中心,分别搜索这几个中心下的向量。通过减小搜索范围,大大提升搜索效率。
<a
name=
"2.3"
></a>
### 2.3 FLAT
## 1. 检索库安装
暴力检索算法。精度最高,但是数据量大时,检索速度较慢。特征库支持增加、删除图像特征功能。
<a
name=
"3"
></a>
## 3. 检索库安装
`Faiss`
具体安装方法如下:
...
...
@@ -40,27 +72,16 @@ pip install faiss-cpu==1.7.1post2
若使用时,不能正常引用,则
`uninstall`
之后,重新
`install`
,尤其是
`windows`
下。
<a
name=
"2"
></a>
## 2. 使用的检索算法
<a
name=
"4"
></a>
目前
`PaddleClas`
中检索模块,支持如下三种检索算法
## 4. 使用及配置文档介绍
-
**HNSW32**
: 一种图索引方法。检索精度较高,速度较快。但是特征库只支持添加图像功能,不支持删除图像特征功能。(默认方法)
-
**IVF**
:倒排索引检索方法。速度较快,但是精度略低。特征库支持增加、删除图像特征功能。
-
**FLAT**
: 暴力检索算法。精度最高,但是数据量大时,检索速度较慢。特征库支持增加、删除图像特征功能。
涉及检索模块配置文件位于:
`deploy/configs/`
下,其中
`inference_*.yaml`
是检索或者分类的推理配置文件,同时也是建立特征库的相关配置文件。
每种检索算法,满足不同场景。其中
`HNSW32`
为默认方法,此方法的检索精度、检索速度可以取得一个较好的平衡,具体算法介绍可以查看
[
官方文档
](
https://github.com/facebookresearch/faiss/wiki
)
。
<a
name=
"4.1"
></a>
<a
name=
"3"
></a>
## 3. 使用及配置文档介绍
涉及检索模块配置文件位于:
`deploy/configs/`
下,其中
`build_*.yaml`
是建立特征库的相关配置文件,
`inference_*.yaml`
是检索或者分类的推理配置文件。
<a
name=
"3.1"
></a>
### 3.1 建库及配置文件参数
### 4.1 建库及配置文件参数
建库的具体操作如下:
...
...
@@ -68,14 +89,14 @@ pip install faiss-cpu==1.7.1post2
# 进入 deploy 目录
cd
deploy
# yaml 文件根据需要改成自己所需的具体 yaml 文件
python python/build_gallery.py
-c
configs/
build
_
***
.yaml
python python/build_gallery.py
-c
configs/
inference
_
***
.yaml
```
其中
`yaml`
文件的建库的配置如下,在运行时,请根据实际情况进行修改。建库操作会将根据
`data_file`
的图像列表,将
`image_root`
下的图像进行特征提取,并在
`index_dir`
下进行存储,以待后续检索使用。
其中
`data_file`
文件存储的是图像文件的路径和标签,每一行的格式为:
`image_path label`
。中间间隔以
`yaml`
文件中
`delimiter`
参数作为间隔。
关于特征提取的具体模型参数,可查看
`yaml`
文件。
关于特征提取的具体模型参数,可查看
`yaml`
文件。
注意下面的配置参数只列举了建立索引库相关部分。
```
yaml
# indexing engine config
...
...
@@ -88,6 +109,7 @@ IndexProcess:
delimiter
:
"
\t
"
dist_type
:
"
IP"
embedding_size
:
512
batch_size
:
32
```
-
**index_method**
:使用的检索算法。目前支持三种,HNSW32、IVF、Flat
...
...
@@ -98,23 +120,29 @@ IndexProcess:
-
**delimiter**
:
**data_file**
中每一行的间隔符
-
**dist_type**
: 特征匹配过程中使用的相似度计算方式。例如
`IP`
内积相似度计算方式,
`L2`
欧式距离计算方法
-
**embedding_size**
:特征维度
-
**batch_size**
:建立特征库时,特征提取的
`batch_size`
<a
name=
"4.2"
></a>
<a
name=
"3.2"
></a>
### 4.2 检索配置文件参数
### 3.2 检索配置文件参数
将检索的过程融合到
`PP-ShiTu`
的整体流程中,请参考
[
README
](
../../../README_ch.md
)
中
`PP-ShiTu 图像识别系统介绍`
部分。检索具体使用操作请参考
[
识别快速开始文档
](
../quick_start/quick_start_recognition.md
)
。
其中,检索部分配置如下,整体检索配置文件,请参考
`deploy/configs/inference_*.yaml`
文件。
注意:此部分参数只是列举了离线检索相关部分参数。
```
yaml
IndexProcess
:
index_dir
:
"
./recognition_demo_data_v1.1/gallery_logo/index/"
return_k
:
5
score_thres
:
0.5
hamming_radius
:
100
```
与建库配置文件不同,新参数主要如下:
-
`return_k`
: 检索结果返回
`k`
个结果
-
`score_thres`
: 检索匹配的阈值
-
`hamming_radius`
: 汉明距离半径。此参数只有在使用二值特征模型,
`dist_type`
设置为
`hamming`
时才能生效。具体二值特征模型使用方法请参考
[
哈希编码
](
./deep_hashing.md
)
docs/zh_CN/inference_deployment/python_deploy.md
浏览文件 @
e956ac88
...
...
@@ -6,10 +6,11 @@
## 目录
-
[
1. 图像分类推理
](
#1
)
-
[
2. 主体检测模型推理
](
#2
)
-
[
3. 特征提取模型推理
](
#3
)
-
[
4. 主体检测、特征提取和向量检索串联
](
#4
)
-
[
1. 图像分类模型推理
](
#1
)
-
[
2. PP-ShiTu模型推理
](
#2
)
-
[
2.1 主体检测模型推理
](
#2.1
)
-
[
2.2 特征提取模型推理
](
#2.2
)
-
[
2.3 PP-ShiTu PipeLine推理
](
#2.3
)
<a
name=
"1"
></a>
## 1. 图像分类推理
...
...
@@ -42,7 +43,12 @@ python python/predict_cls.py -c configs/inference_cls.yaml
*
如果你希望提升评测模型速度,使用 GPU 评测时,建议开启 TensorRT 加速预测,使用 CPU 评测时,建议开启 MKL-DNN 加速预测。
<a
name=
"2"
></a>
## 2. 主体检测模型推理
## 2. PP-ShiTu模型推理
PP-ShiTu整个Pipeline包含三部分:主体检测、特提取模型、特征检索。其中主体检测、特征模型可以单独推理使用。单独主体检测详见
[
2.1
](
#2.1
)
,特征提取模型单独推理详见
[
2.2
](
#2.2
)
, PP-ShiTu整体推理详见
[
2.3
](
#2.3
)
。
<a
name=
"2.1"
></a>
### 2.1 主体检测模型推理
进入 PaddleClas 的
`deploy`
目录下:
...
...
@@ -70,8 +76,8 @@ python python/predict_det.py -c configs/inference_det.yaml
*
`Global.use_gpu`
: 是否使用 GPU 预测,默认为
`True`
。
<a
name=
"
3
"
></a>
##
3.
特征提取模型推理
<a
name=
"
2.2
"
></a>
##
# 2.2
特征提取模型推理
下面以商品特征提取为例,介绍特征提取模型推理。首先进入 PaddleClas 的
`deploy`
目录下:
...
...
@@ -90,7 +96,7 @@ tar -xf ./models/product_ResNet50_vd_aliproduct_v1.0_infer.tar -C ./models/
上述预测命令可以得到一个 512 维的特征向量,直接输出在在命令行中。
<a
name=
"
4
"
></a>
##
4. 主体检测、特征提取和向量检索串联
<a
name=
"
2.3
"
></a>
##
# 2.3. PP-ShiTu PipeLine推理
主体检测、特征提取和向量检索的串联预测,可以参考图像识别
[
快速体验
](
../quick_start/quick_start_recognition.md
)
。
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}