Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleClas
提交
dbbfbbe0
P
PaddleClas
项目概览
PaddlePaddle
/
PaddleClas
大约 2 年 前同步成功
通知
118
Star
4999
Fork
1114
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
19
列表
看板
标记
里程碑
合并请求
6
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleClas
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
19
Issue
19
列表
看板
标记
里程碑
合并请求
6
合并请求
6
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
dbbfbbe0
编写于
6月 17, 2021
作者:
D
dongshuilong
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
modify feature learning docs
上级
3a304fc0
变更
11
隐藏空白更改
内联
并排
Showing
11 changed file
with
181 addition
and
258 deletion
+181
-258
docs/images/recognition/rec_pipeline.png
docs/images/recognition/rec_pipeline.png
+0
-0
docs/images/recognition/vehicle/CompCars.png
docs/images/recognition/vehicle/CompCars.png
+0
-0
docs/images/recognition/vehicle/cars.JPG
docs/images/recognition/vehicle/cars.JPG
+0
-0
docs/zh_CN/application/cartoon_character_recognition.md
docs/zh_CN/application/cartoon_character_recognition.md
+22
-17
docs/zh_CN/application/feature_learning.md
docs/zh_CN/application/feature_learning.md
+8
-157
docs/zh_CN/application/logo_recognition.md
docs/zh_CN/application/logo_recognition.md
+24
-24
docs/zh_CN/application/product_recognition.md
docs/zh_CN/application/product_recognition.md
+11
-6
docs/zh_CN/application/vehicle_fine_grained_classfication.md
docs/zh_CN/application/vehicle_fine_grained_classfication.md
+0
-19
docs/zh_CN/application/vehicle_recognition.md
docs/zh_CN/application/vehicle_recognition.md
+103
-0
docs/zh_CN/application/vehicle_reid.md
docs/zh_CN/application/vehicle_reid.md
+0
-34
docs/zh_CN/tutorials/config.md
docs/zh_CN/tutorials/config.md
+13
-1
未找到文件。
docs/images/recognition/rec_pipeline.png
0 → 100644
浏览文件 @
dbbfbbe0
83.3 KB
docs/images/recogn
o
tion/vehicle/CompCars.png
→
docs/images/recogn
i
tion/vehicle/CompCars.png
浏览文件 @
dbbfbbe0
文件已移动
docs/images/recogn
o
tion/vehicle/cars.JPG
→
docs/images/recogn
i
tion/vehicle/cars.JPG
浏览文件 @
dbbfbbe0
文件已移动
docs/zh_CN/application/cartoon_character_recognition.md
浏览文件 @
dbbfbbe0
# 动漫人物识别
# 动漫人物识别
## 简介
自七十年代以来,人脸识别已经成为了计算机视觉和生物识别领域研究最多的主题之一。近年来,传统的人脸识别方法已经被基于卷积神经网络(CNN)的深度学习方法代替。目前,人脸识别技术广泛应用于安防、商业、金融、智慧自助终端、娱乐等各个领域。而在行业应用强烈需求的推动下,动漫媒体越来越受到关注,动漫人物的人脸识别也成为一个新的研究领域。
自七十年代以来,人脸识别已经成为了计算机视觉和生物识别领域研究最多的主题之一。近年来,传统的人脸识别方法已经被基于卷积神经网络(CNN)的深度学习方法代替。目前,人脸识别技术广泛应用于安防、商业、金融、智慧自助终端、娱乐等各个领域。而在行业应用强烈需求的推动下,动漫媒体越来越受到关注,动漫人物的人脸识别也成为一个新的研究领域。
## 数据集
## 1 算法介绍
### iCartoonFace数据集
近日,来自爱奇艺的一项新研究提出了一个新的基准数据集,名为iCartoonFace。该数据集由 5013 个动漫角色的 389678 张图像组成,并带有 ID、边界框、姿势和其他辅助属性。 iCartoonFace 是目前图像识别领域规模最大的卡通媒体数据集,而且质量高、注释丰富、内容全面,其中包含相似图像、有遮挡的图像以及外观有变化的图像。
与其他数据集相比,iCartoonFace无论在图像数量还是实体数量上,均具有明显领先的优势:

算法整体流程,详见
[
特征学习
](
./feature_learning.md
)
整体流程。值得注意的是,本流程没有使用
`Neck`
模块。
论文地址:https://arxiv.org/pdf/1907.1339
具体配置信息详见
[
配置文件
](
../../../ppcls/configs/Cartoonface/ResNet50_icartoon.yaml
)
。
### 数据预处理
具体模块如下所示,
### 1.1 数据增强
相比于人脸识别任务,动漫人物头像的配饰、道具、发型等因素可以显著提升识别的准确率,因此在原数据集标注框的基础上,长、宽各expand为之前的2倍,并做截断处理,得到了目前训练所有的数据集。
训练集: 5013类,389678张图像; 验证集: query2500张,gallery20000张。训练时,对数据所做的预处理如下:
-
图像
`Resize`
到224
-
图像
`Resize`
到224
-
随机水平翻转
-
随机水平翻转
-
Normalize:归一化到0~1
-
Normalize:归一化到0~1
### 1.2 Backbone的具体设置
## 模型
采用ResNet50作为backbone。并采用大模型进行蒸馏
采用ResNet50作为backbone, 主要的提升策略包括:
-
加载预训练模型
-
分布式训练,更大的batch_size
-
采用大模型进行蒸馏
具体配置信息详见
[
配置文件
](
../../../ppcls/configs/Cartoonface/ResNet50_icartoon.yaml
)
。
### 1.3 Metric Learning相关Loss设置
在动漫人物识别中,只使用了
`CELoss`
## 2 实验结果
本方法使用iCartoonFace数据集进行验证。该数据集由 5013 个动漫角色的 389678 张图像组成,并带有 ID、边界框、姿势和其他辅助属性。 iCartoonFace 是目前图像识别领域规模最大的卡通媒体数据集,而且质量高、注释丰富、内容全面,其中包含相似图像、有遮挡的图像以及外观有变化的图像。
与其他数据集相比,iCartoonFace无论在图像数量还是实体数量上,均具有明显领先的优势。其中训练集: 5013类,389678张图像; 验证集: query2500张,gallery20000张。

论文地址:https://arxiv.org/pdf/1907.1339
值得注意的是,相比于人脸识别任务,动漫人物头像的配饰、道具、发型等因素可以显著提升识别的准确率,因此在原数据集标注框的基础上,长、宽各expand为之前的2倍,并做截断处理,得到了目前训练所有的数据集。
在此数据集上,此方法Recall1 达到83.24%。
docs/zh_CN/application/feature_learning.md
浏览文件 @
dbbfbbe0
# 特征学习
# 特征学习
此部分主要是针对
`RecModel`
的训练模式进行说明。
`RecModel`
的训练模式,主要是为了支持车辆识别(车辆细分类、ReID)、Logo识别、动漫人物识别、商品识别等特征学习的应用。与在
`ImageNet`
上训练普通的分类网络不同的是,此训练模式
,主要有以下特征
此部分主要是针对
特征学习的训练模式进行说明,即
`RecModel`
的训练模式。主要是为了支持车辆识别(车辆细分类、ReID)、Logo识别、动漫人物识别、商品识别等特征学习的应用。与在
`ImageNet`
上训练普通的分类网络不同的是,此特征学习部分
,主要有以下特征
-
支持对
`backbone`
的输出进行截断,即支持提取任意中间层的特征信息
-
支持对
`backbone`
的输出进行截断,即支持提取任意中间层的特征信息
-
支持在
`backbone`
的feature输出层后,添加可配置的网络层,即
`Neck`
部分
-
支持在
`backbone`
的feature输出层后,添加可配置的网络层,即
`Neck`
部分
-
支持
`Arc
Margin
`
等
`metric learning`
相关loss函数,提升特征学习能力
-
支持
`Arc
Face Loss
`
等
`metric learning`
相关loss函数,提升特征学习能力
##
yaml文件说明
##
整体流程
`RecModel`
的训练模式与普通分类训练的配置类似,配置文件主要分为以下几个部分:

### 1 全局设置部分
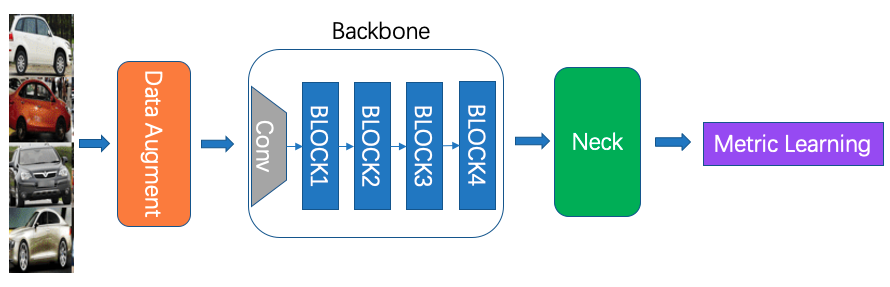
特征学习的整体结构如上图所示,主要包括:数据增强、Backbone的设置、Neck、Metric Learning等几大部分。其中
`Neck`
部分为自由添加的网络层,如添加的embedding层等,当然也可以不用此模块。训练时,利用
`Metric Learning`
部分的Loss对模型进行优化。预测时,一般来说,默认以
`Neck`
部分的输出作为特征输出。
```
yaml
针对不同的应用,可以根据需要,对每一部分自由选择。每一部分的具体配置,如数据增强、Backbone、Neck、Metric Learning相关Loss等设置,详见具体应用:
[
车辆识别
](
./vehicle_recognition.md
)
、
[
Logo识别
](
./logo_recognition.md
)
、
[
动漫人物识别
](
./cartoon_character_recognition.md
)
、
[
商品识别
](
./product_recognition.md
)
Global
:
# 如为null则从头开始训练。若指定中间训练保存的状态地址,则继续训练
checkpoints
:
null
# pretrained model路径或者 bool类型
pretrained_model
:
null
# 模型保存路径
output_dir
:
"
./output/"
device
:
"
gpu"
class_num
:
30671
# 保存模型的粒度,每个epoch保存一次
save_interval
:
1
eval_during_train
:
True
eval_interval
:
1
# 训练的epoch数
epochs
:
160
# log输出频率
print_batch_step
:
10
# 是否使用visualdl库
use_visualdl
:
False
# used for static mode and model export
image_shape
:
[
3
,
224
,
224
]
save_inference_dir
:
"
./inference"
# 使用retrival的方式进行评测
eval_mode
:
"
retrieval"
```
##
# 2 数据部分
##
配置文件说明
```
yaml
配置文件说明详见
[
yaml配置文件说明文档
](
../tutorials/config.md
)
。其中模型结构配置,详见文档中
**识别模型结构配置**
部分。
DataLoader
:
Train
:
dataset
:
# 具体使用的Dataset的的名称
name
:
"
VeriWild"
# 使用此数据集的具体参数
image_root
:
"
./dataset/VeRI-Wild/images/"
cls_label_path
:
"
./dataset/VeRI-Wild/train_test_split/train_list_start0.txt"
# 图像增广策略:ResizeImage、RandFlipImage等
transform_ops
:
-
ResizeImage
:
size
:
224
-
RandFlipImage
:
flip_code
:
1
-
AugMix
:
prob
:
0.5
-
NormalizeImage
:
scale
:
0.00392157
mean
:
[
0.485
,
0.456
,
0.406
]
std
:
[
0.229
,
0.224
,
0.225
]
order
:
'
'
-
RandomErasing
:
EPSILON
:
0.5
sl
:
0.02
sh
:
0.4
r1
:
0.3
mean
:
[
0.
,
0.
,
0.
]
sampler
:
name
:
DistributedRandomIdentitySampler
batch_size
:
128
num_instances
:
2
drop_last
:
False
shuffle
:
True
loader
:
num_workers
:
6
use_shared_memory
:
False
```
`val dataset`
设置与
`train dataset`
除图像增广策略外,设置基本一致
### 3 Backbone的具体设置
```
yaml
Arch
:
# 使用RecModel模式进行训练
name
:
"
RecModel"
# 导出inference model的具体配置
infer_output_key
:
"
features"
infer_add_softmax
:
False
# 使用的Backbone
Backbone
:
name
:
"
ResNet50"
pretrained
:
True
# 使用此层作为Backbone的feature输出,name为ResNet50的full_name
BackboneStopLayer
:
name
:
"
adaptive_avg_pool2d_0"
# Backbone的基础上,新增网络层。此模型添加1x1的卷积层(embedding)
Neck
:
name
:
"
VehicleNeck"
in_channels
:
2048
out_channels
:
512
# 增加ArcMargin, 即ArcLoss的具体实现
Head
:
name
:
"
ArcMargin"
embedding_size
:
512
class_num
:
431
margin
:
0.15
scale
:
32
```
`Neck`
部分为在
`bacbone`
基础上,添加的网络层,可根据需求添加。 如在ReID任务中,添加一个输出长度为512的
`embedding`
层,可由此部分实现。需注意的是,
`Neck`
部分需对应好
`BackboneStopLayer`
层的输出维度。一般来说,
`Neck`
部分为网络的最终特征输出层。
`Head`
部分主要是为了支持
`metric learning`
等具体loss函数,如
`ArcMargin`
(
[
ArcFace Loss
](
https://arxiv.org/abs/1801.07698
)
的fc层的具体实现),在完成训练后,一般将此部分剔除。
### 4 Loss的设置
```
yaml
Loss
:
Train
:
-
CELoss
:
weight
:
1.0
-
SupConLoss
:
weight
:
1.0
# SupConLoss的具体参数
views
:
2
Eval
:
-
CELoss
:
weight
:
1.0
```
训练时同时使用
`CELoss`
和
`SupConLoss`
,权重比例为
`1:1`
,测试时只使用
`CELoss`
### 5 优化器设置
```
yaml
Optimizer
:
# 使用的优化器名称
name
:
Momentum
# 优化器具体参数
momentum
:
0.9
lr
:
# 使用的学习率调节具体名称
name
:
MultiStepDecay
# 学习率调节算法具体参数
learning_rate
:
0.01
milestones
:
[
30
,
60
,
70
,
80
,
90
,
100
,
120
,
140
]
gamma
:
0.5
verbose
:
False
last_epoch
:
-1
regularizer
:
name
:
'
L2'
coeff
:
0.0005
```
### 6 Eval Metric设置
```
yaml
Metric
:
Eval
:
# 使用Recallk和mAP两种评价指标
-
Recallk
:
topk
:
[
1
,
5
]
-
mAP
:
{}
```
docs/zh_CN/application/logo_recognition.md
浏览文件 @
dbbfbbe0
# Logo识别
# Logo识别
Logo识别技术,是现实生活中应用很广的一个领域,比如一张照片中是否出现了Adidas或者Nike的商标Logo,或者一个杯子上是否出现了星巴克或者可口可乐的商标Logo。通常Logo类别数量较多时,往往采用检测+识别两阶段方式,检测模块负责检测出潜在的Logo区域,根据检测区域抠图后输入识别模块进行识别。识别模块多采用检索的方式,根据查询图片和底库图片进行相似度排序获得预测类别。此文档主要对Logo图片的特征提取部分进行相关介绍
,内容包括:
Logo识别技术,是现实生活中应用很广的一个领域,比如一张照片中是否出现了Adidas或者Nike的商标Logo,或者一个杯子上是否出现了星巴克或者可口可乐的商标Logo。通常Logo类别数量较多时,往往采用检测+识别两阶段方式,检测模块负责检测出潜在的Logo区域,根据检测区域抠图后输入识别模块进行识别。识别模块多采用检索的方式,根据查询图片和底库图片进行相似度排序获得预测类别。此文档主要对Logo图片的特征提取部分进行相关介绍
。
-
数据集及预处理方式
## 1 算法介绍
-
Backbone的具体设置
-
Loss函数的相关设置
全部的超参数及具体配置:
[
ResNet50_ReID.yaml
](
../../../ppcls/configs/Logo/ResNet50_ReID.yaml
)
算法整体流程,详见
[
特征学习
](
./feature_learning.md
)
整体流程。
## 1 数据集及预处理
整体设置详见:
[
ResNet50_ReID.yaml
](
../../../ppcls/configs/Logo/ResNet50_ReID.yaml
)
。
### 1.1 LogoDet-3K数据集
具体模块如下所示
<img
src=
"../../images/logo/logodet3k.jpg"
style=
"zoom:50%;"
/>
### 1.1数据增强
LogoDet-3K数据集是具有完整标注的Logo数据集,有3000个标识类别,约20万个高质量的人工标注的标识对象和158652张图片。相关数据介绍参考
[
原论文
](
https://arxiv.org/abs/2008.05359
)
与普通训练分类不同,此部分主要使用如下图像增强方式:
### 1.2 数据预处理
-
图像
`Resize`
到224。对于Logo而言,使用的图像,直接为检测器crop之后的图像,因此直接resize到224
-
[
AugMix
](
https://arxiv.org/abs/1912.02781v1
)
:模拟Logo图像形变变化等实际场景
-
[
RandomErasing
](
https://arxiv.org/pdf/1708.04896v2.pdf
)
:模拟遮挡等实际情况
由于原始的数据集中,图像包含标注的检测框,在识别阶段只考虑检测器抠图后的logo区域,因此采用原始的标注框抠出Logo区域图像构成训练集,排除背景在识别阶段的影响。对数据集进行划分,产生155427张训练集,覆盖3000个logo类别(同时作为测试时gallery图库),3225张测试集,用于作为查询集。抠图后的训练集可
[
在此下载
](
https://arxiv.org/abs/2008.05359
)
### 1.2 Backbone的具体设置
-
图像
`Resize`
到224
-
随机水平翻转
-
[
AugMix
](
https://arxiv.org/abs/1912.02781v1
)
-
Normlize:归一化到0~1
-
[
RandomErasing
](
https://arxiv.org/pdf/1708.04896v2.pdf
)
## 2 Backbone的具体设置
使用
`ResNet50`
作为backbone,同时做了如下修改:
具体是用
`ResNet50`
作为backbone,主要做了如下修改:
-
last stage stride=1, 保持最后输出特征图尺寸14x14。计算量增加较小,但显著提高模型特征提取能力
-
使用ImageNet预训练模型
-
last stage stride=1, 保持最后输出特征图尺寸14x14
具体代码:
[
ResNet50_last_stage_stride1
](
../../../ppcls/arch/backbone/variant_models/resnet_variant.py
)
-
在最后加入一个embedding 卷积层,特征维度为512
### 1.3 Neck部分
具体代码:
[
ResNet50_last_stage_stride1
](
../../../ppcls/arch/backbone/variant_models/resnet_variant.py
)
为了降低inferecne时计算特征距离的复杂度,添加一个embedding 卷积层,特征维度为512。
##
3
Loss的设置
##
# 1.4 Metric Learning相关
Loss的设置
在Logo识别中,使用了
[
Pairwise Cosface + CircleMargin
](
https://arxiv.org/abs/2002.10857
)
联合训练,其中权重比例为1:1
在Logo识别中,使用了
[
Pairwise Cosface + CircleMargin
](
https://arxiv.org/abs/2002.10857
)
联合训练,其中权重比例为1:1
具体代码详见:
[
PairwiseCosface
](
../../../ppcls/loss/pairwisecosface.py
)
、
[
CircleMargin
](
../../../ppcls/arch/gears/circlemargin.py
)
具体代码详见:
[
PairwiseCosface
](
../../../ppcls/loss/pairwisecosface.py
)
、
[
CircleMargin
](
../../../ppcls/arch/gears/circlemargin.py
)
## 2 实验结果
<img
src=
"../../images/logo/logodet3k.jpg"
style=
"zoom:50%;"
/>
使用LogoDet-3K数据集进行实验,此数据集是具有完整标注的Logo数据集,有3000个标识类别,约20万个高质量的人工标注的标识对象和158652张图片。相关数据介绍参考
[
原论文
](
https://arxiv.org/abs/2008.05359
)
由于原始的数据集中,图像包含标注的检测框,在识别阶段只考虑检测器抠图后的logo区域,因此采用原始的标注框抠出Logo区域图像构成训练集,排除背景在识别阶段的影响。对数据集进行划分,产生155427张训练集,覆盖3000个logo类别(同时作为测试时gallery图库),3225张测试集,用于作为查询集。抠图后的训练集可
[
在此下载
](
https://arxiv.org/abs/2008.05359
)
其他部分参数,详见
[
配置文件
](
../../../ppcls/configs/Logo/ResNet50_ReID.yaml
)
。
在此数据集上,recall1 达到89.8%
。
docs/zh_CN/application/product_recognition.md
浏览文件 @
dbbfbbe0
# 商品识别
# 商品识别
商品识别技术,是现如今应用非常广的一个领域。拍照购物的方式已经被很多人所采纳,无人结算台已经走入各大超市,无人超市更是如火如荼,这背后都是以商品识别技术作为支撑。商品识别技术大概是"商品检测+商品识别"这样的流程,商品检测模块负责检测出潜在的商品区域,商品识别模型负责将商品检测模块检测出的主体进行识别。识别模块多采用检索的方式,根据查询图片和底库图片进行相似度排序获得预测类别。此文档主要对商品图片的特征提取部分进行相关介绍
,内容包括:
商品识别技术,是现如今应用非常广的一个领域。拍照购物的方式已经被很多人所采纳,无人结算台已经走入各大超市,无人超市更是如火如荼,这背后都是以商品识别技术作为支撑。商品识别技术大概是"商品检测+商品识别"这样的流程,商品检测模块负责检测出潜在的商品区域,商品识别模型负责将商品检测模块检测出的主体进行识别。识别模块多采用检索的方式,根据查询图片和底库图片进行相似度排序获得预测类别。此文档主要对商品图片的特征提取部分进行相关介绍
。
-
数据集及预处理方式
## 1 算法介绍
-
Backbone的具体设置
-
Loss函数的相关设置
算法整体流程,详见
[
特征学习
](
./feature_learning.md
)
整体流程。此方案在不同的数据集
车辆ReID整体设置详见:
[
ResNet50_ReID.yaml
](
../../../ppcls/configs/Vehicle/ResNet50_ReID.yaml
)
。
车辆细分类整体设置详见:
[
ResNet50.yaml
](
../../../ppcls/configs/Vehicle/ResNet50.yaml
)
具体细节如下所示。
## 1 Aliproduct
## 1 Aliproduct
...
@@ -60,9 +66,8 @@ Inshop数据集是DeepFashion的子集,其是香港中文大学开放的一个
...
@@ -60,9 +66,8 @@ Inshop数据集是DeepFashion的子集,其是香港中文大学开放的一个
-
使用ImageNet预训练模型
-
使用ImageNet预训练模型
-
在GAP后、分类层前加入一个512维的embedding FC层,没有做BatchNorm和激活。
-
在GAP后、分类层前加入一个512维的embedding FC层,没有做BatchNorm和激活。
-
分类层采用
[
Arcmargin Head
](
../../../ppcls/arch/gears/arcmargin.py
)
,具体原理可参考
[
原论文
](
https://arxiv.org/pdf/1801.07698.pdf
)
。
-
分类层采用
[
Arcmargin Head
](
../../../ppcls/arch/gears/arcmargin.py
)
,具体原理可参考
[
原论文
](
https://arxiv.org/pdf/1801.07698.pdf
)
。
### 4 Loss的设置
### 4 Loss的设置
在Inshop商品识别中,使用了
[
CELoss
](
../../../ppcls/loss/celoss.py
)
和
[
TripletLossV2
](
../../../ppcls/loss/triplet.py
)
联合训练。
在Inshop商品识别中,使用了
[
CELoss
](
../../../ppcls/loss/celoss.py
)
和
[
TripletLossV2
](
../../../ppcls/loss/triplet.py
)
联合训练。
...
...
docs/zh_CN/application/vehicle_fine_grained_classfication.md
已删除
100644 → 0
浏览文件 @
3a304fc0
# 车辆细粒度分类
细粒度分类,是对属于某一类基础类别的图像进行子类别的细粉,如各种鸟、各种花、各种矿石之间。顾名思义,车辆细粒度分类是对车辆的不同子类别进行分类。
其训练过程与车辆ReID相比,有以下不同:
-
数据集不同
-
Loss设置不同
其他部分请详见
[
车辆ReID
](
./vehicle_reid.md
)
整体配置文件:
[
ResNet50.yaml
](
../../../ppcls/configs/Vehicle/ResNet50.yaml
)
## 1 数据集
在此demo中,使用
[
CompCars
](
http://mmlab.ie.cuhk.edu.hk/datasets/comp_cars/index.html
)
作为训练数据集。

图像主要来自网络和监控数据,其中网络数据包含163个汽车制造商、1716个汽车型号的汽车。共
**136,726**
张全车图像,
**27,618**
张部分车图像。其中网络汽车数据包含bounding box、视角、5个属性(最大速度、排量、车门数、车座数、汽车类型)。监控数据包含
**50,000**
张前视角图像。
值得注意的是,此数据集中需要根据自己的需要生成不同的label,如本demo中,将不同年份生产的相同型号的车辆视为同一类,因此,类别总数为:431类。
## 2 Loss设置
与车辆ReID不同,在此分类中,Loss使用的是
[
TtripLet Loss
](
../../../ppcls/loss/triplet.py
)
+
[
ArcLoss
](
../../../ppcls/arch/gears/arcmargin.py
)
,权重比例1:1。
docs/zh_CN/application/vehicle_recognition.md
0 → 100644
浏览文件 @
dbbfbbe0
# 车辆识别
此部分主要包含两部分:车辆细粒度分类、车辆ReID。
细粒度分类,是对属于某一类基础类别的图像进行子类别的细粉,如各种鸟、各种花、各种矿石之间。顾名思义,车辆细粒度分类是对车辆的不同子类别进行分类。
ReID,也就是 Re-identification,其定义是利用算法,在图像库中找到要搜索的目标的技术,所以它是属于图像检索的一个子问题。而车辆ReID就是给定一张车辆图像,找出同一摄像头不同的拍摄图像,或者不同摄像头下拍摄的同一车辆图像的过程。在此过程中,如何提取鲁棒特征,尤为重要。
此文档中,使用同一套训练方案对两个细方向分别做了尝试。
## 1 算法介绍
算法整体流程,详见
[
特征学习
](
./feature_learning.md
)
整体流程。
车辆ReID整体设置详见:
[
ResNet50_ReID.yaml
](
../../../ppcls/configs/Vehicle/ResNet50_ReID.yaml
)
。
车辆细分类整体设置详见:
[
ResNet50.yaml
](
../../../ppcls/configs/Vehicle/ResNet50.yaml
)
具体细节如下所示。
### 1.1数据增强
与普通训练分类不同,此部分主要使用如下图像增强方式:
-
图像
`Resize`
到224。尤其对于ReID而言,车辆图像已经是由检测器检测后crop出的车辆图像,因此若再使用crop图像增强,会丢失更多的车辆信息
-
[
AugMix
](
https://arxiv.org/abs/1912.02781v1
)
:模拟光照变化、摄像头位置变化等实际场景
-
[
RandomErasing
](
https://arxiv.org/pdf/1708.04896v2.pdf
)
:模拟遮挡等实际情况
### 1.2 Backbone的具体设置
使用
`ResNet50`
作为backbone,同时做了如下修改:
-
last stage stride=1, 保持最后输出特征图尺寸14x14。计算量增加较小,但显著提高模型特征提取能力
具体代码:
[
ResNet50_last_stage_stride1
](
../../../ppcls/arch/backbone/variant_models/resnet_variant.py
)
### 1.3 Neck部分
为了降低inferecne时计算特征距离的复杂度,添加一个embedding 卷积层,特征维度为512。
### 1.4 Metric Learning相关Loss的设置
-
车辆ReID中,使用了
[
SupConLoss
](
../../../ppcls/loss/supconloss.py
)
+
[
ArcLoss
](
../../../ppcls/arch/gears/arcmargin.py
)
,其中权重比例为1:1
-
车辆细分类,使用
[
TtripLet Loss
](
../../../ppcls/loss/triplet.py
)
+
[
ArcLoss
](
../../../ppcls/arch/gears/arcmargin.py
)
,其中权重比例为1:1
## 2 实验结果
### 2.1 车辆ReID
<img
src=
"../../images/recognition/vehicle/cars.JPG"
style=
"zoom:50%;"
/>
此方法在VERI-Wild数据集上进行了实验。此数据集是在一个大型闭路电视监控系统,在无约束的场景下,一个月内(30
*
24小时)中捕获的。该系统由174个摄像头组成,其摄像机分布在200多平方公里的大型区域。原始车辆图像集包含1200万个车辆图像,经过数据清理和标注,采集了416314张40671个不同的车辆图像。
[
具体详见论文
](
https://github.com/PKU-IMRE/VERI-Wild
)
|
**Methods**
|
**Small**
| | |
| :--------------------------: | :-------: | :-------: | :-------: |
| | mAP | Top1 | Top5 |
| Strong baesline(Resnet50)[1] | 76.61 | 90.83 | 97.29 |
| HPGN(Resnet50+PGN)[2] | 80.42 | 91.37 | - |
| GLAMOR(Resnet50+PGN)[3] | 77.15 | 92.13 | 97.43 |
| PVEN(Resnet50)[4] | 79.8 | 94.01 | 98.06 |
| SAVER(VAE+Resnet50)[5] | 80.9 | 93.78 | 97.93 |
| PaddleClas baseline1 | 65.6 | 92.37 | 97.23 |
| PaddleClas baseline2 | 80.09 |
**93.81**
|
**98.26**
|
注:baseline1 为目前的开源模型,baseline2即将开源
### 2.2 车辆细分类
车辆细分类中,使用
[
CompCars
](
http://mmlab.ie.cuhk.edu.hk/datasets/comp_cars/index.html
)
作为训练数据集。

数据集中图像主要来自网络和监控数据,其中网络数据包含163个汽车制造商、1716个汽车型号的汽车。共
**136,726**
张全车图像,
**27,618**
张部分车图像。其中网络汽车数据包含bounding box、视角、5个属性(最大速度、排量、车门数、车座数、汽车类型)。监控数据包含
**50,000**
张前视角图像。
值得注意的是,此数据集中需要根据自己的需要生成不同的label,如本demo中,将不同年份生产的相同型号的车辆视为同一类,因此,类别总数为:431类。
|
**Methods**
| Top1 Acc |
| :-----------------------------: | :-------: |
| ResNet101-swp[6] | 97.6% |
| Fine-Tuning DARTS[7] | 95.9% |
| Resnet50 + COOC[8] | 95.6% |
| A3M[9] | 95.4% |
| PaddleClas baseline (ResNet50) |
**97.1**
% |
## 3 参考文献
[1] Bag of Tricks and a Strong Baseline for Deep Person Re-Identification.CVPR workshop 2019.
[2] Exploring Spatial Significance via Hybrid Pyramidal Graph Network for Vehicle Re-identification. In arXiv preprint arXiv:2005.14684
[3] GLAMORous: Vehicle Re-Id in Heterogeneous Cameras Networks with Global and Local Attention. In arXiv preprint arXiv:2002.02256
[4] Parsing-based view-aware embedding network for vehicle re-identification. CVPR 2020.
[5] The Devil is in the Details: Self-Supervised Attention for Vehicle Re-Identification. In ECCV 2020.
[6] Deep CNNs With Spatially Weighted Pooling for Fine-Grained Car Recognition. IEEE Transactions on Intelligent Transportation Systems, 2017.
[7] Fine-Tuning DARTS for Image Classification. 2020.
[8] Fine-Grained Vehicle Classification with Unsupervised Parts Co-occurrence Learning. 2018
[9] Attribute-Aware Attention Model for Fine-grained Representation Learning. 2019.
docs/zh_CN/application/vehicle_reid.md
已删除
100644 → 0
浏览文件 @
3a304fc0
# 车辆ReID
ReID,也就是 Re-identification,其定义是利用算法,在图像库中找到要搜索的目标的技术,所以它是属于图像检索的一个子问题。而车辆ReID就是给定一张车辆图像,找出同一摄像头不同的拍摄图像,或者不同摄像头下拍摄的同一车辆图像的过程。在此过程中,如何提取鲁棒特征,尤为重要。因此,此文档主要对车辆ReID中训练特征提取网络部分做相关介绍,内容如下:
-
数据集及预处理方式
-
Backbone的具体设置
-
Loss函数的相关设置
全部的超参数及具体配置:
[
ResNet50_ReID.yaml
](
../../../ppcls/configs/Vehicle/ResNet50_ReID.yaml
)
## 1 数据集及预处理
### 1.1 VERI-Wild数据集
<img
src=
"../../images/recognotion/vehicle/cars.JPG"
style=
"zoom:50%;"
/>
此数据集是在一个大型闭路电视监控系统,在无约束的场景下,一个月内(30
*
24小时)中捕获的。该系统由174个摄像头组成,其摄像机分布在200多平方公里的大型区域。原始车辆图像集包含1200万个车辆图像,经过数据清理和标注,采集了416314张40671个不同的车辆图像。
[
具体详见论文
](
https://github.com/PKU-IMRE/VERI-Wild
)
### 1.2 数据预处理
由于原始的数据集中,车辆图像已经是由检测器检测后crop出的车辆图像,因此无需像训练
`ImageNet`
中图像crop操作。整体的数据增强方式,按照顺序如下:
-
图像
`Resize`
到224
-
随机水平翻转
-
[
AugMix
](
https://arxiv.org/abs/1912.02781v1
)
-
Normlize:归一化到0~1
-
[
RandomErasing
](
https://arxiv.org/pdf/1708.04896v2.pdf
)
## 2 Backbone的具体设置
具体是用
`ResNet50`
作为backbone,但在
`ResNet50`
基础上做了如下修改:
-
0在最后加入一个embedding 层,即1x1的卷积层,特征维度为512
具体代码:
[
ResNet50_last_stage_stride1
](
../../../ppcls/arch/backbone/variant_models/resnet_variant.py
)
## 3 Loss的设置
车辆ReID中,使用了
[
SupConLoss
](
https://arxiv.org/abs/2004.11362
)
+
[
ArcLoss
](
https://arxiv.org/abs/1801.07698
)
,其中权重比例为1:1
具体代码详见:
[
SupConLoss代码
](
../../../ppcls/loss/supconloss.py
)
、
[
ArcLoss代码
](
../../../ppcls/arch/gears/arcmargin.py
)
其他部分的具体设置,详见
[
配置文件
](
../../../ppcls/configs/Vehicle/ResNet50_ReID.yaml
)
。
docs/zh_CN/tutorials/config.md
浏览文件 @
dbbfbbe0
...
@@ -33,14 +33,26 @@
...
@@ -33,14 +33,26 @@
| ls_epsilon | label_smoothing epsilon值| 0 | float |
| ls_epsilon | label_smoothing epsilon值| 0 | float |
| use_distillation | 是否进行模型蒸馏 | False | bool |
| use_distillation | 是否进行模型蒸馏 | False | bool |
## 结构(ARCHITECTURE)
## 结构(ARCHITECTURE)
### 分类模型结构配置
| 参数名字 | 具体含义 | 默认值 | 可选值 |
| 参数名字 | 具体含义 | 默认值 | 可选值 |
|:---:|:---:|:---:|:---:|
|:---:|:---:|:---:|:---:|
| name | 模型结构名字 | "ResNet50_vd" | PaddleClas提供的模型结构 |
| name | 模型结构名字 | "ResNet50_vd" | PaddleClas提供的模型结构 |
| params | 模型传参 | {} | 模型结构所需的额外字典,如EfficientNet等配置文件中需要传入
`padding_type`
等参数,可以通过这种方式传入 |
| params | 模型传参 | {} | 模型结构所需的额外字典,如EfficientNet等配置文件中需要传入
`padding_type`
等参数,可以通过这种方式传入 |
### 识别模型结构配置
| 参数名字 | 具体含义 | 默认值 | 可选值 |
| :---------------: | :-----------------------: | :--------: | :----------------------------------------------------------: |
| name | 模型结构 | "RecModel" | ["RecModel"] |
| infer_output_key | inference时的输出值 | “feature” | ["feature", "logits"] |
| infer_add_softmax | infercne是否添加softmax | True | [True, False] |
| Backbone | 使用Backbone的名字 | | 需传入字典结构,包含
`name`
、
`pretrained`
等key值。其中
`name`
为分类模型名字,
`pretrained`
为布尔值 |
| BackboneStopLayer | Backbone中的feature输出层 | | 需传入字典结构,包含
`name`
key值,具体值为Backbone中的特征输出层的
`full_name`
|
| Neck | 添加的网络Neck部分 | | 需传入字典结构,Neck网络层的具体输入参数 |
| Head | 添加的网络Head部分 | | 需传入字典结构,Head网络层的具体输入参数 |
### 学习率(LEARNING_RATE)
### 学习率(LEARNING_RATE)
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}