Merge branch 'master' into support_1.8
Showing
configs/ResNet/ResNet50_fp16.yml
0 → 100644
{kind=link}
52.7 KB
{kind=link}
90.8 KB
{kind=link}

86.9 KB
{kind=link}
48.8 KB
docs/images/main_features_s.png
0 → 100644
{kind=link}

154.4 KB
{kind=link}
134.6 KB
{kind=link}
140.8 KB
{kind=link}
136.6 KB
{kind=link}
438.0 KB
{kind=link}
181.7 KB
{kind=link}
194.3 KB
{kind=link}
180.0 KB
{kind=link}
126.4 KB
{kind=link}
139.0 KB
{kind=link}
129.3 KB
{kind=link}
129.1 KB
{kind=link}

129.5 KB
{kind=link}
132.2 KB
{kind=link}

185.7 KB
{kind=link}
197.9 KB
{kind=link}
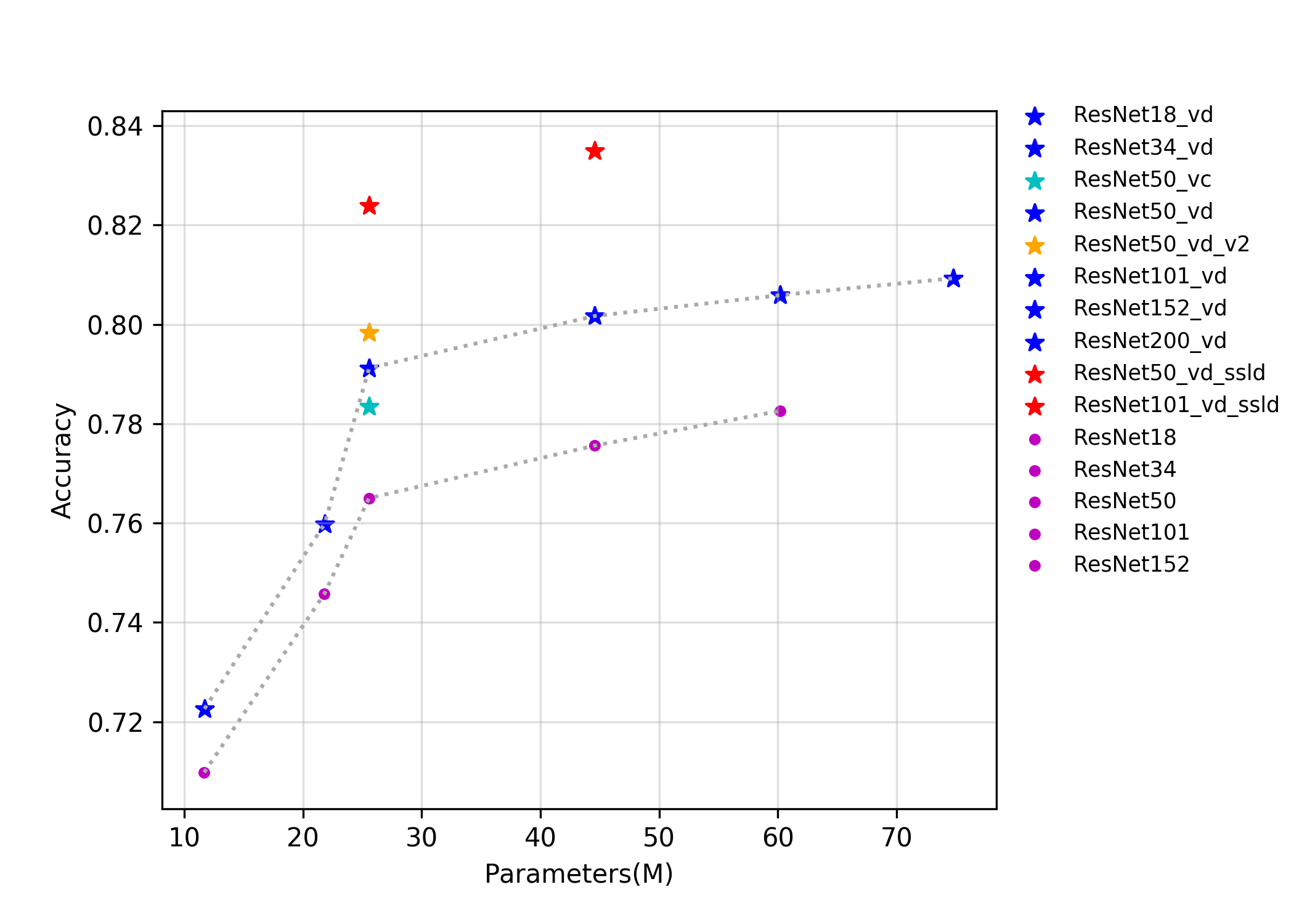
189.0 KB
{kind=link}

244.9 KB
{kind=link}
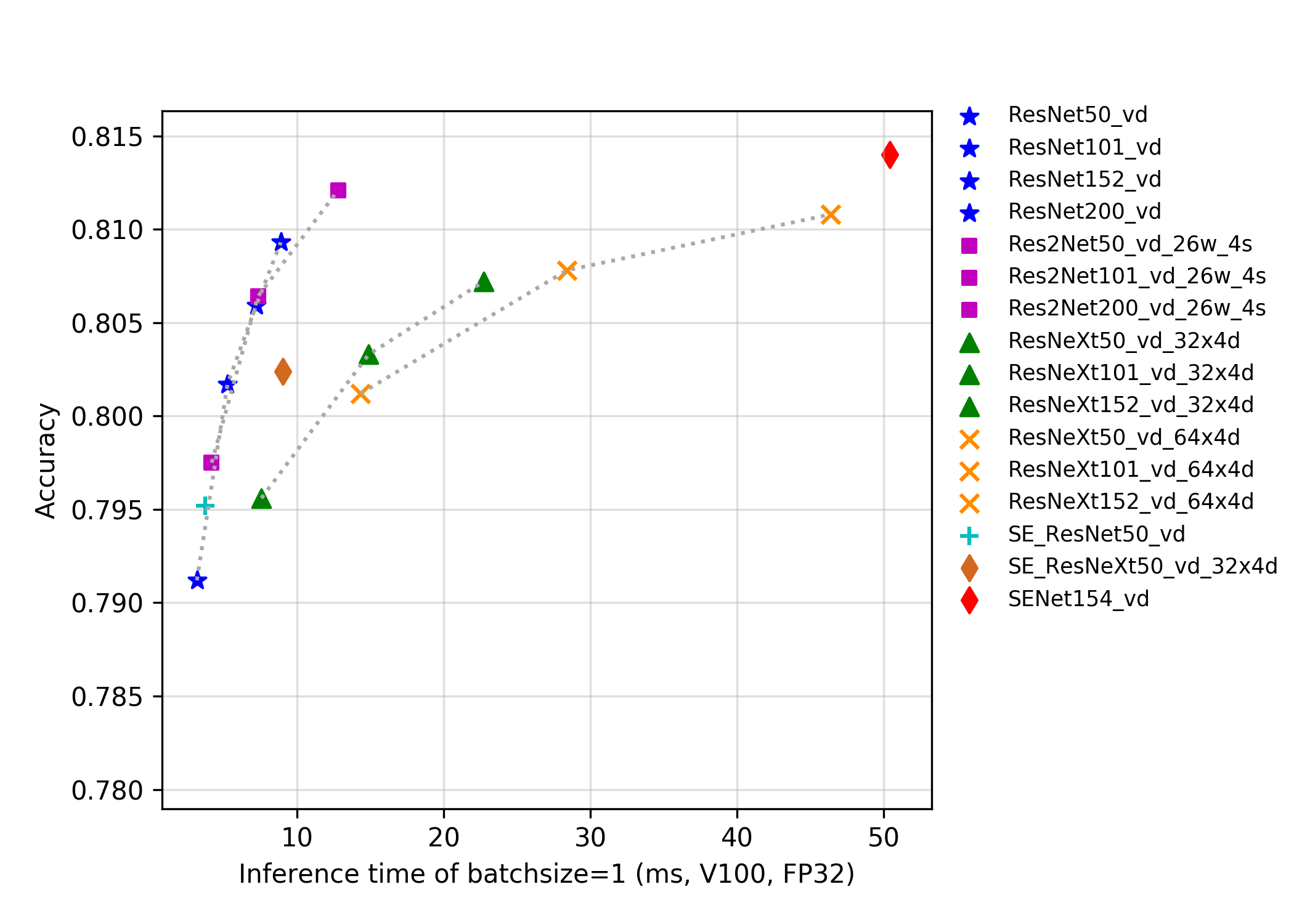
244.1 KB
{kind=link}
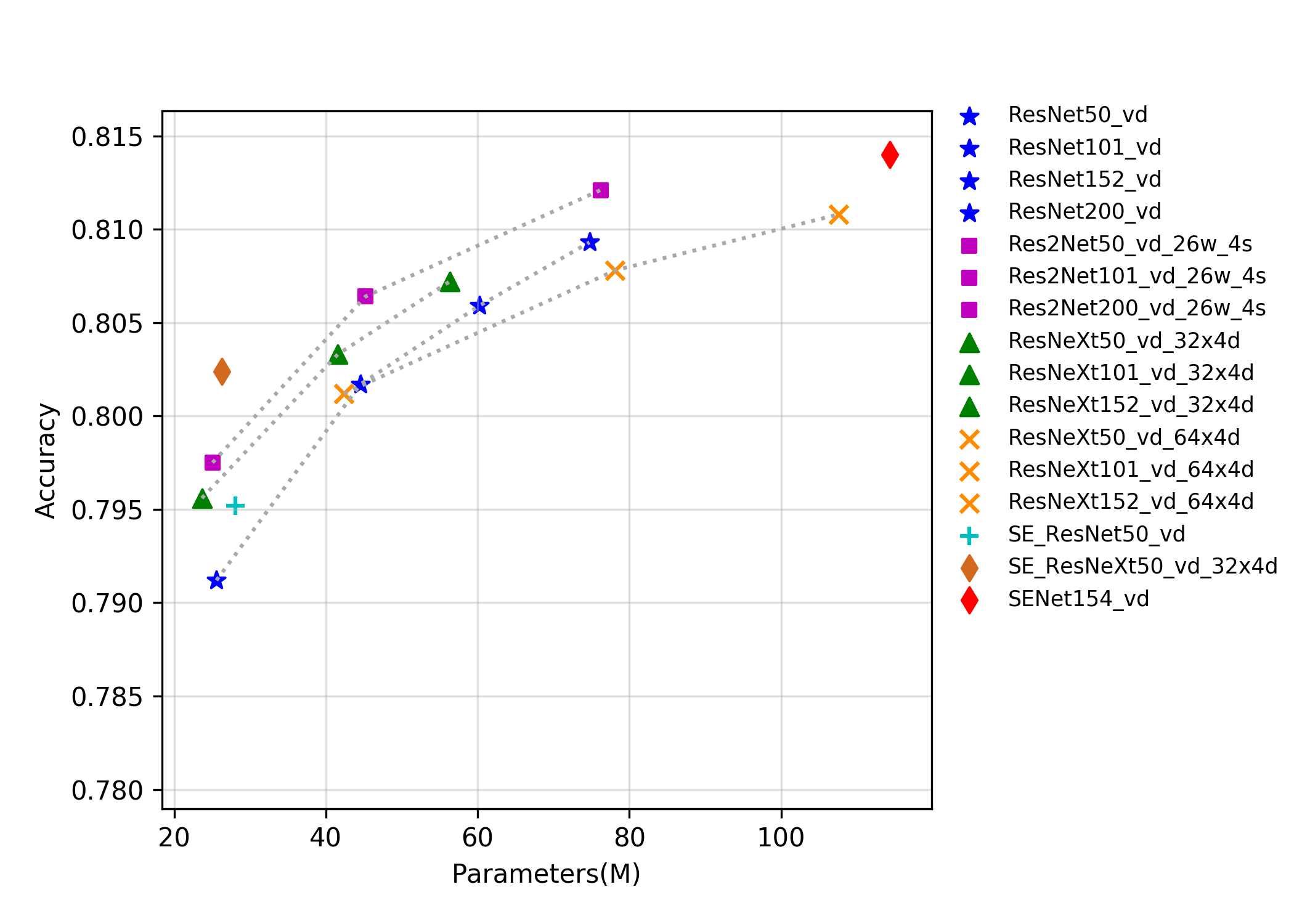
244.3 KB
{kind=link}
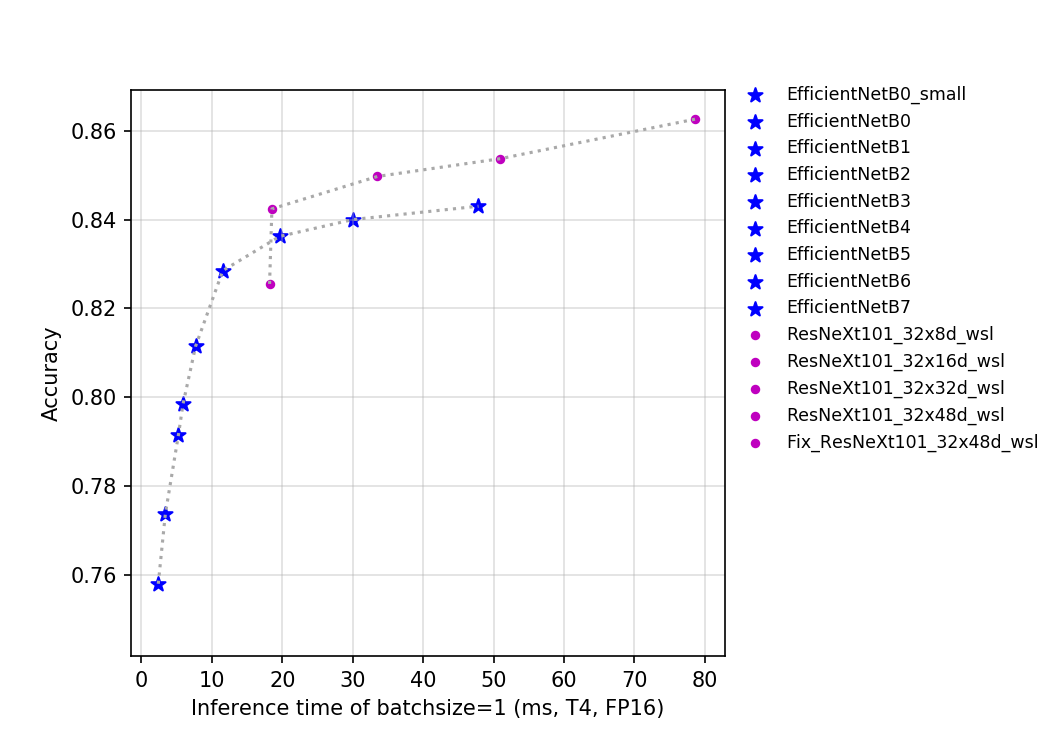
88.5 KB
{kind=link}
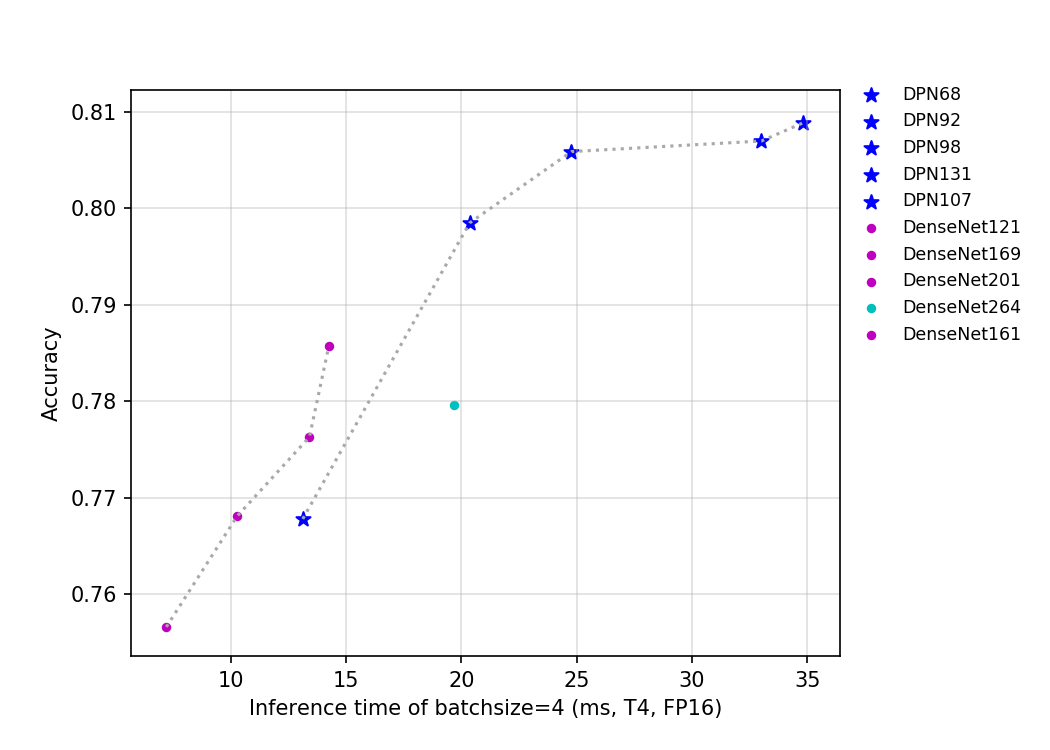
57.3 KB
{kind=link}
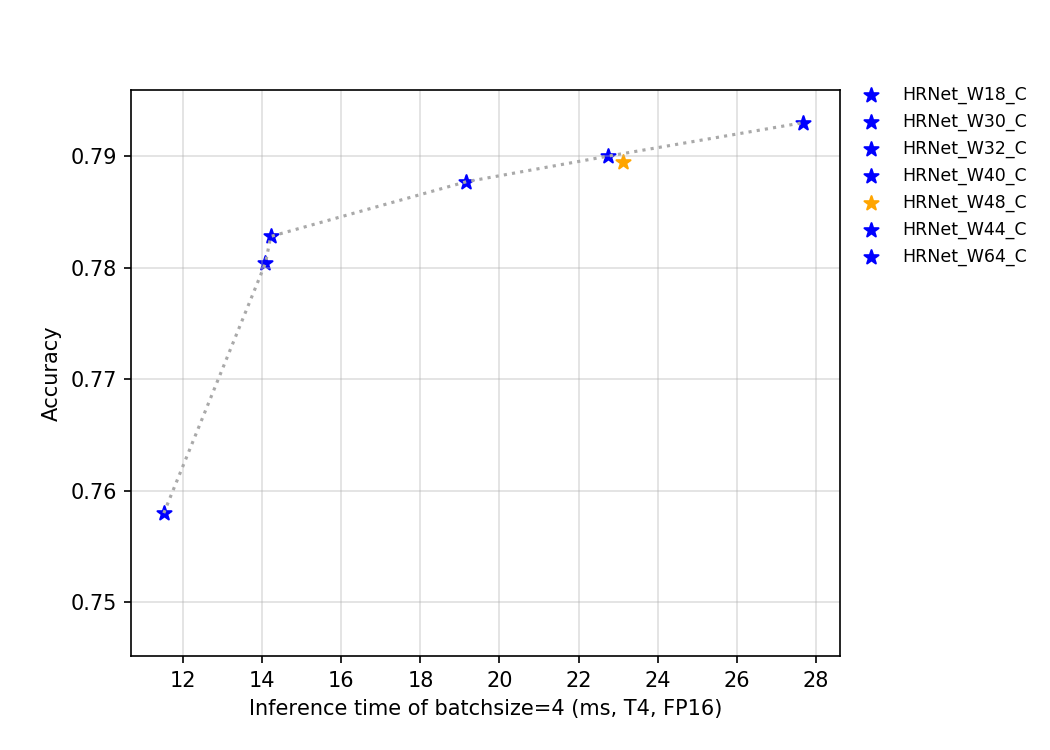
54.4 KB
{kind=link}

57.1 KB
{kind=link}
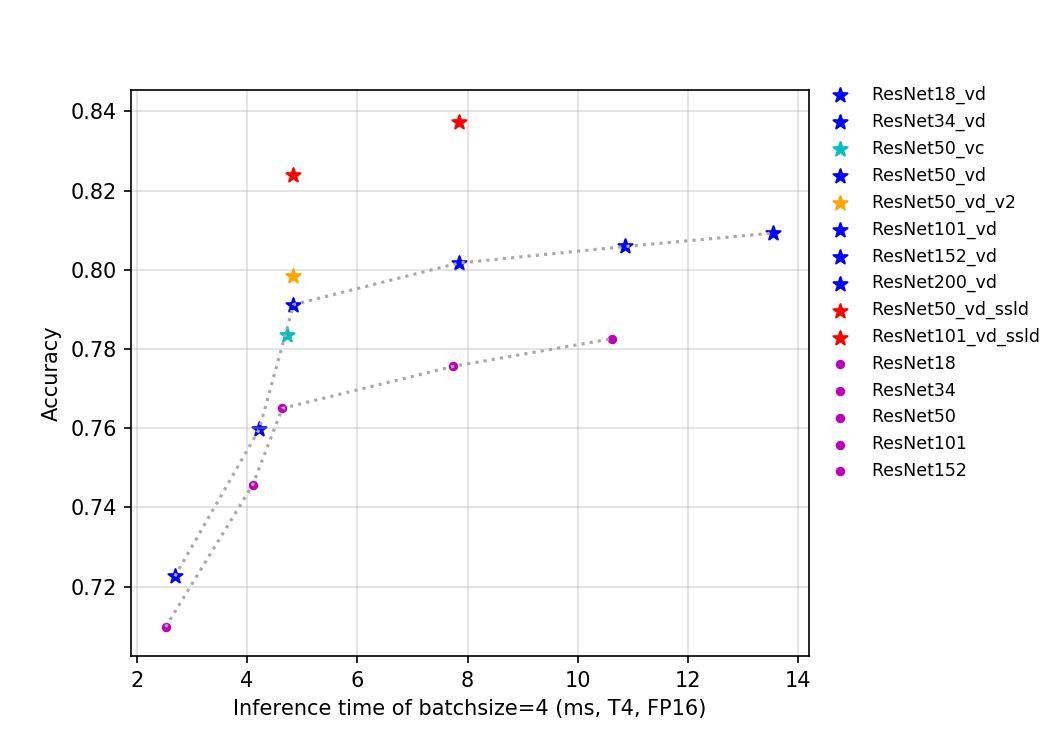
83.9 KB
{kind=link}
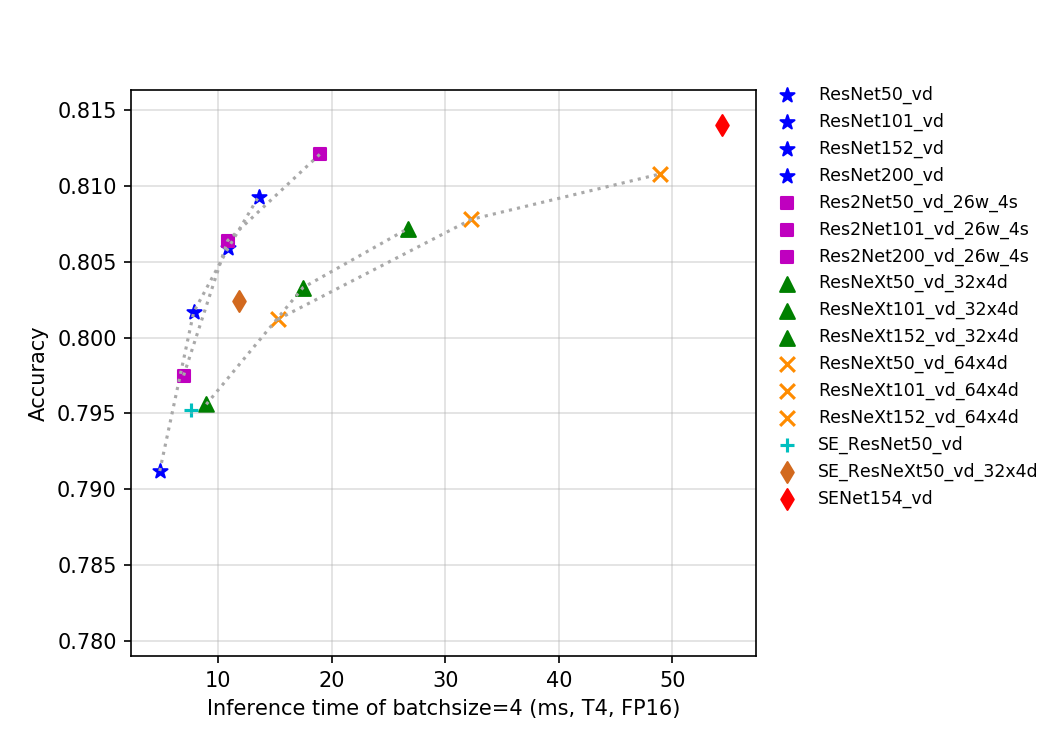
105.3 KB
{kind=link}
88.6 KB
{kind=link}
54.3 KB
{kind=link}
56.2 KB
{kind=link}
58.1 KB
{kind=link}
81.6 KB
{kind=link}
80.8 KB
{kind=link}
49.3 KB
{kind=link}
50.6 KB
{kind=link}
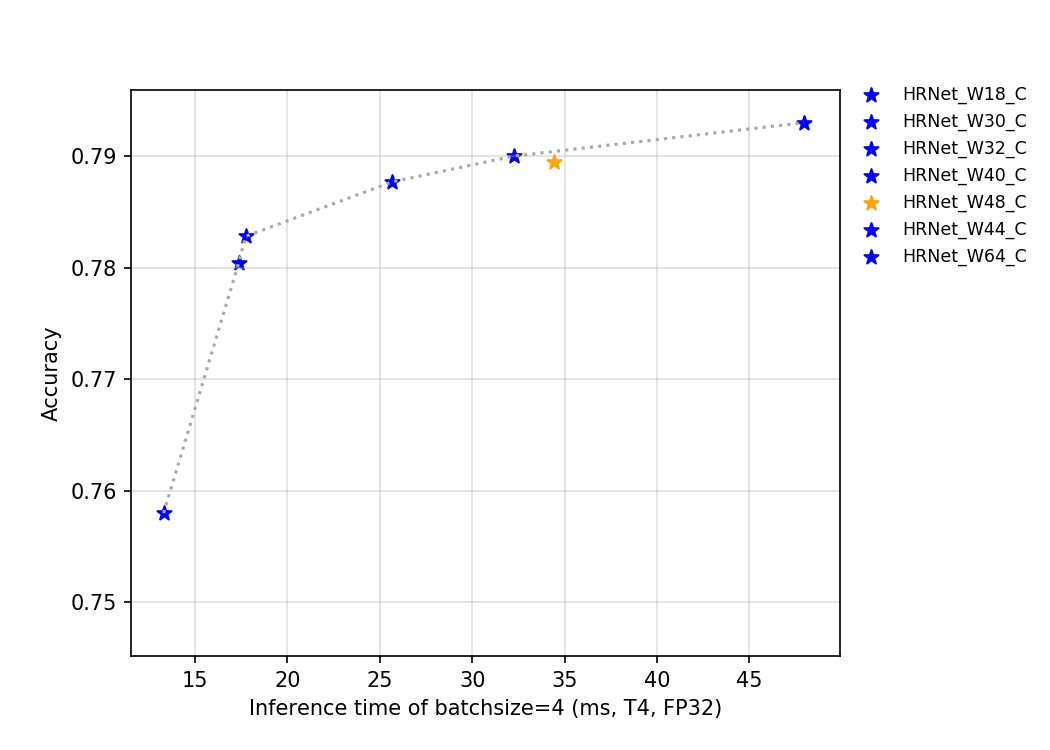
53.7 KB
{kind=link}
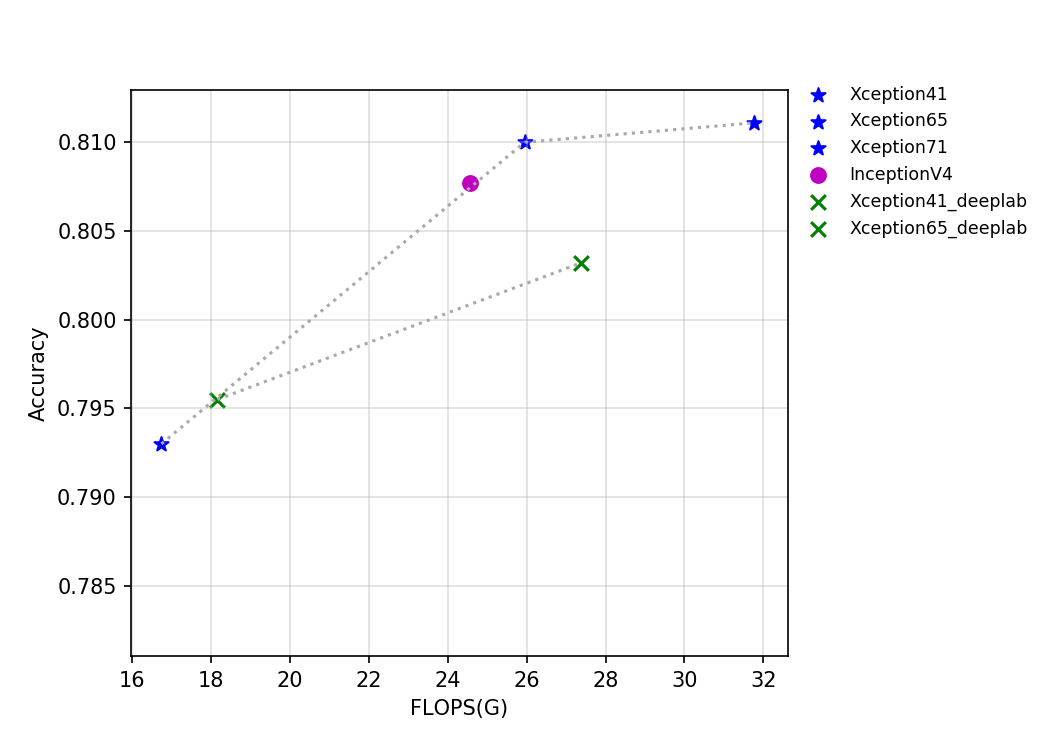
53.9 KB
{kind=link}
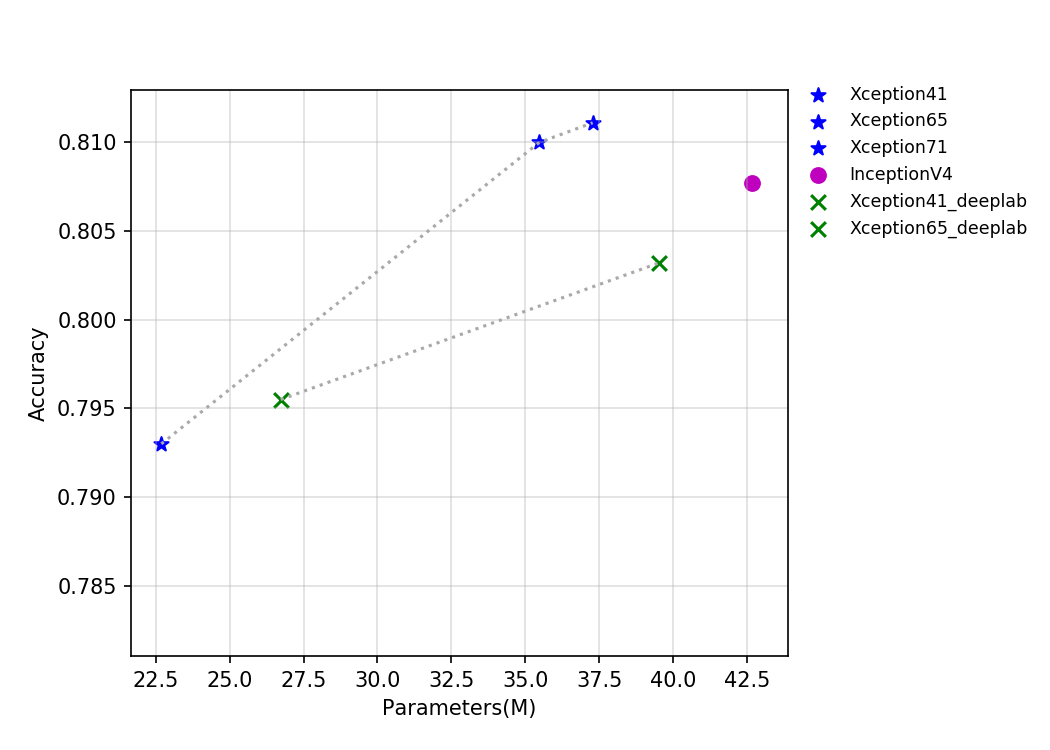
54.5 KB
{kind=link}
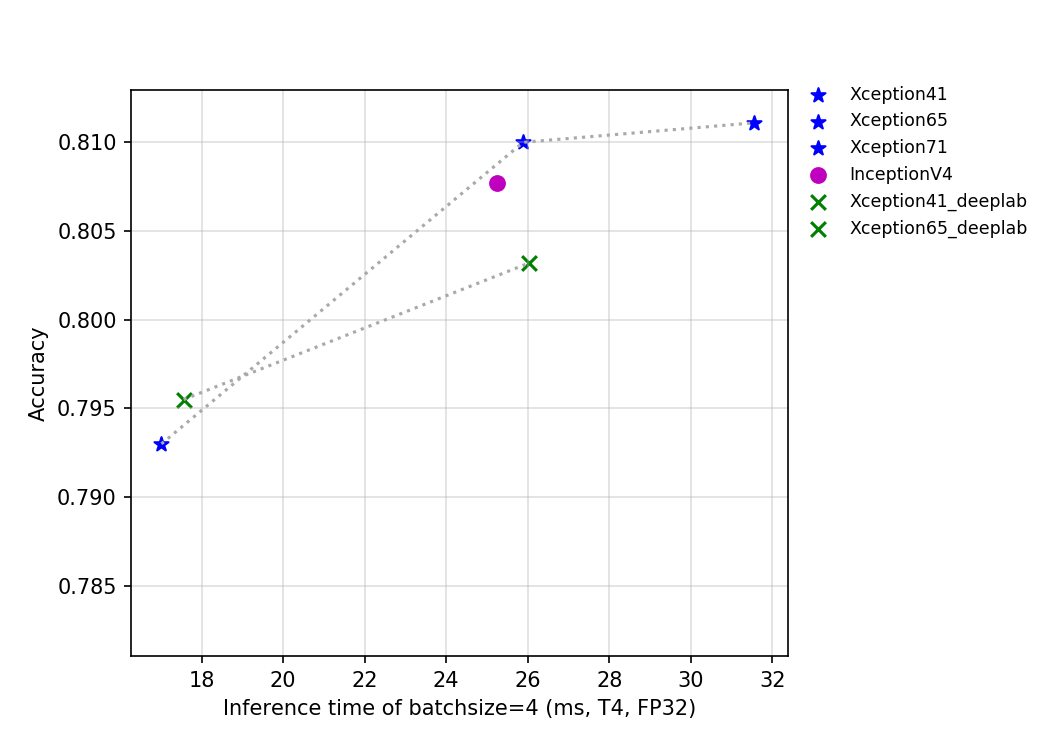
58.2 KB
{kind=link}
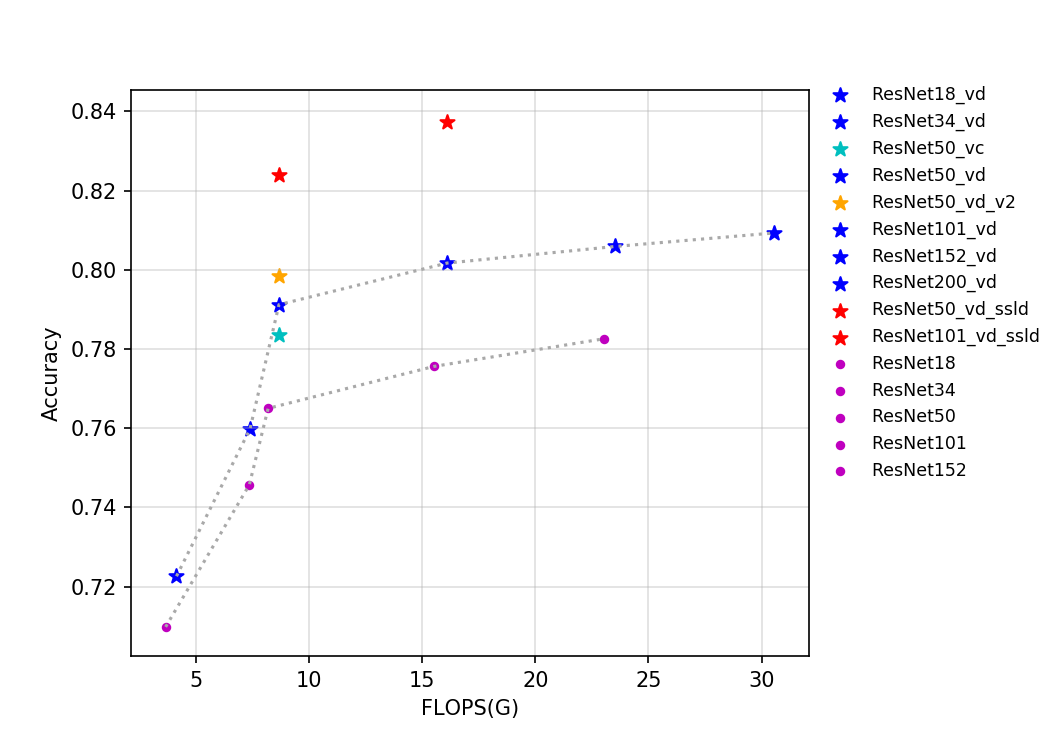
78.3 KB
{kind=link}
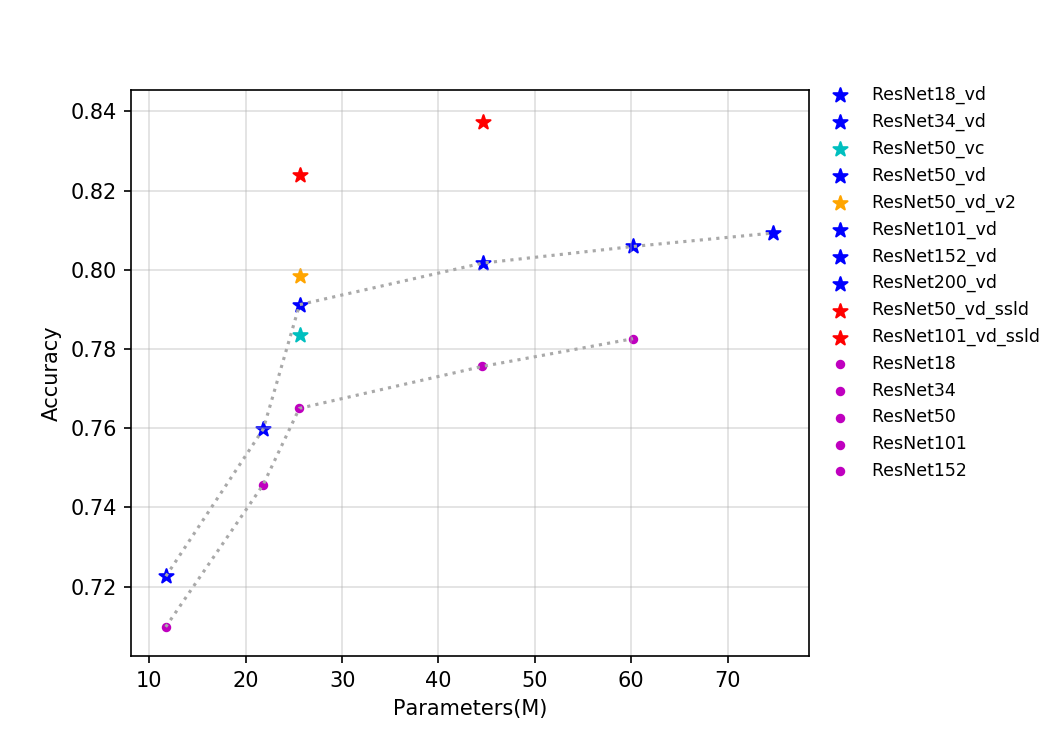
80.5 KB
{kind=link}
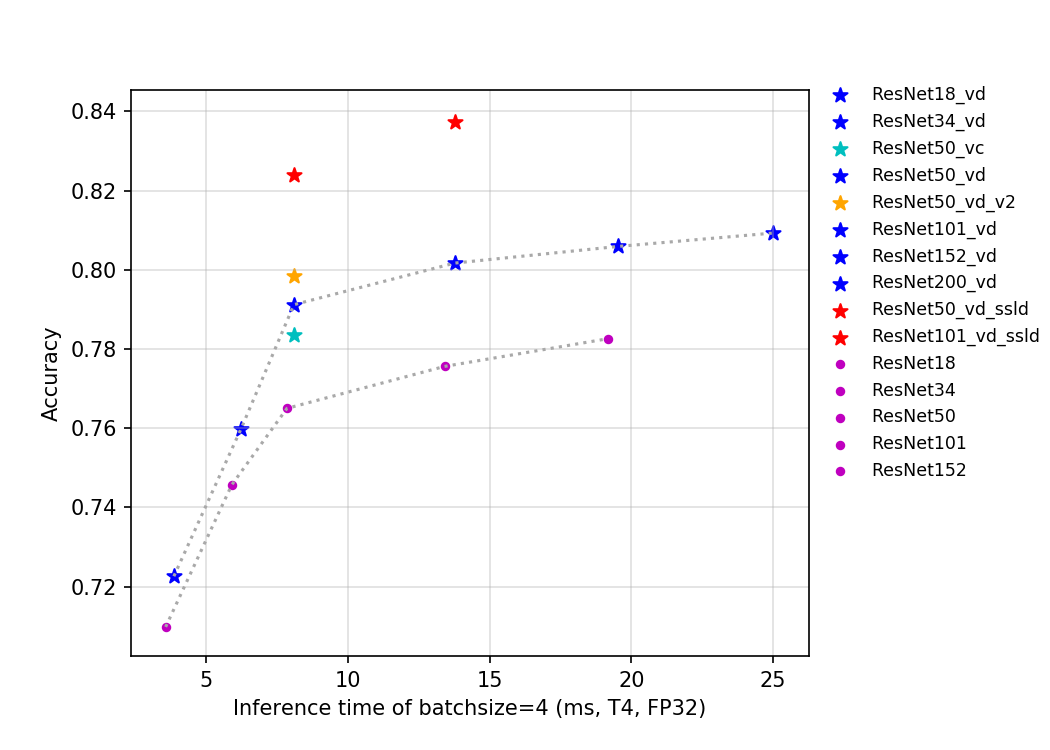
82.9 KB
{kind=link}
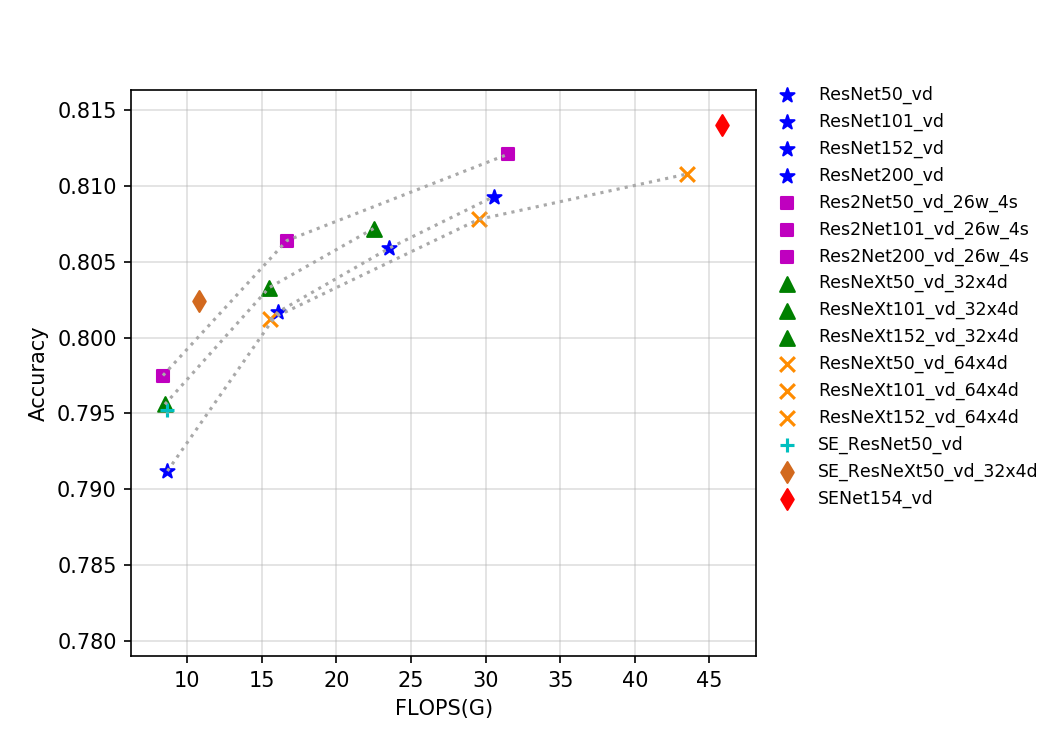
105.1 KB
{kind=link}
106.0 KB
{kind=link}
107.6 KB
{kind=link}
150.7 KB
{kind=link}
140.5 KB
{kind=link}
141.0 KB
{kind=link}
57.8 KB
{kind=link}
88.5 KB
{kind=link}

55.8 KB
{kind=link}
55.5 KB
{kind=link}
85.5 KB
{kind=link}
106.0 KB
{kind=link}
174.9 KB
{kind=link}
356.5 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
docs/images/models/mobile_arm_top1.png
100755 → 100644
{kind=link}
{kind=link}
| W: | H:

| W: | H:
{kind=link}
590.3 KB
{kind=link}

312.2 KB
{kind=link}
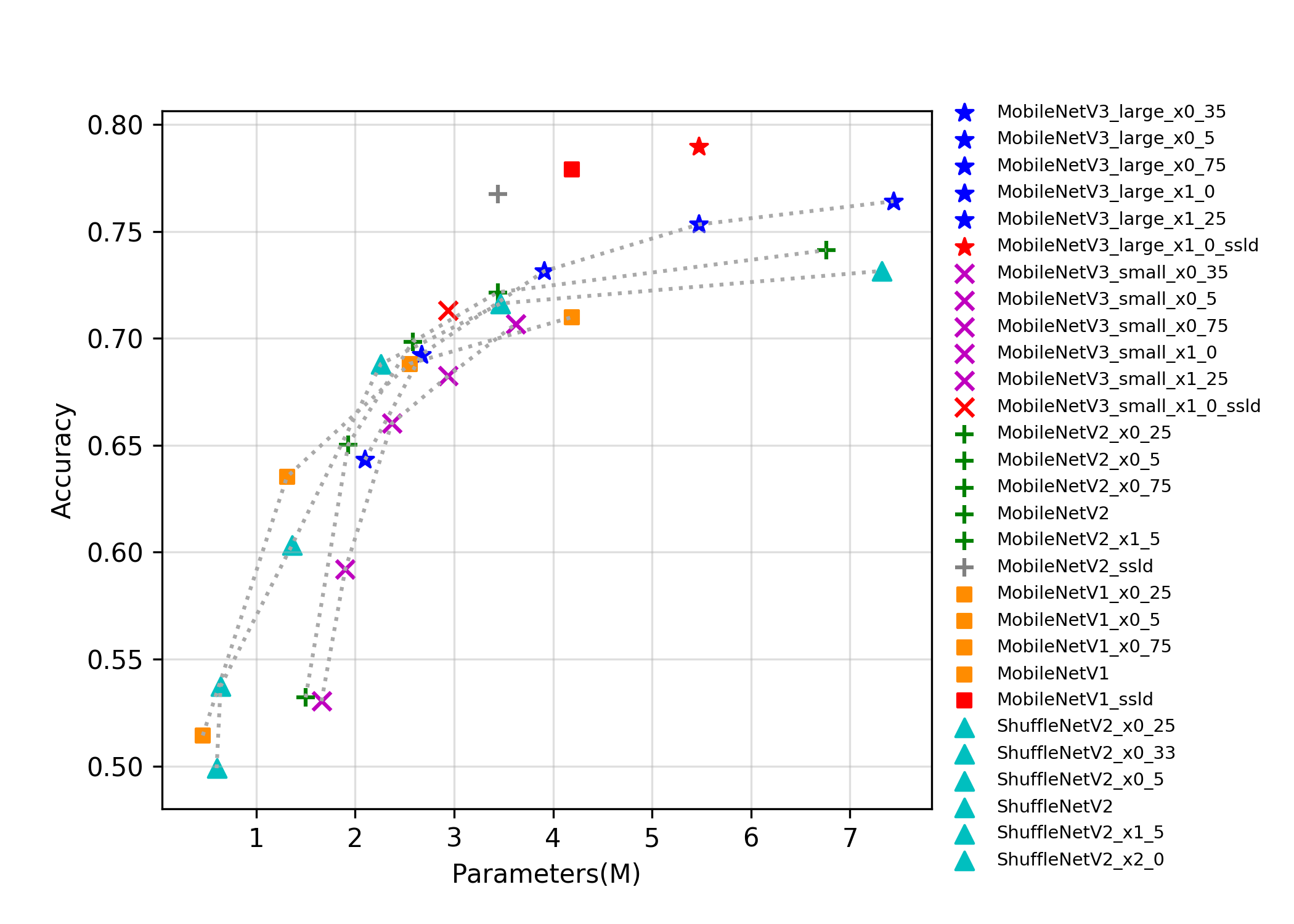
313.7 KB
tools/export_serving_model.py
0 → 100644
tools/lite/benchmark.sh
0 → 100644
tools/serving/utils.py
0 → 100644