docs: supplement, test=document_fix
Showing
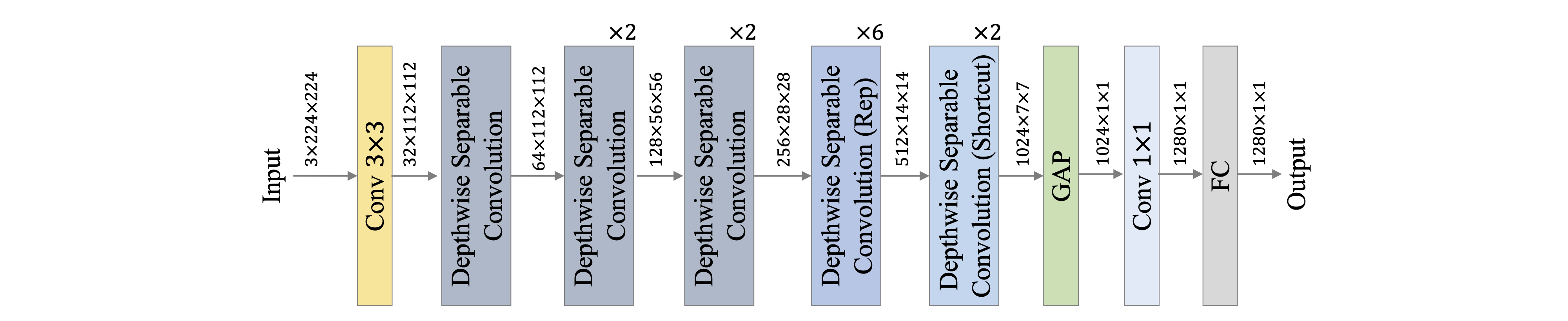
docs/images/PP-LCNetV2/net.png
0 → 100644
{kind=link}
275.1 KB
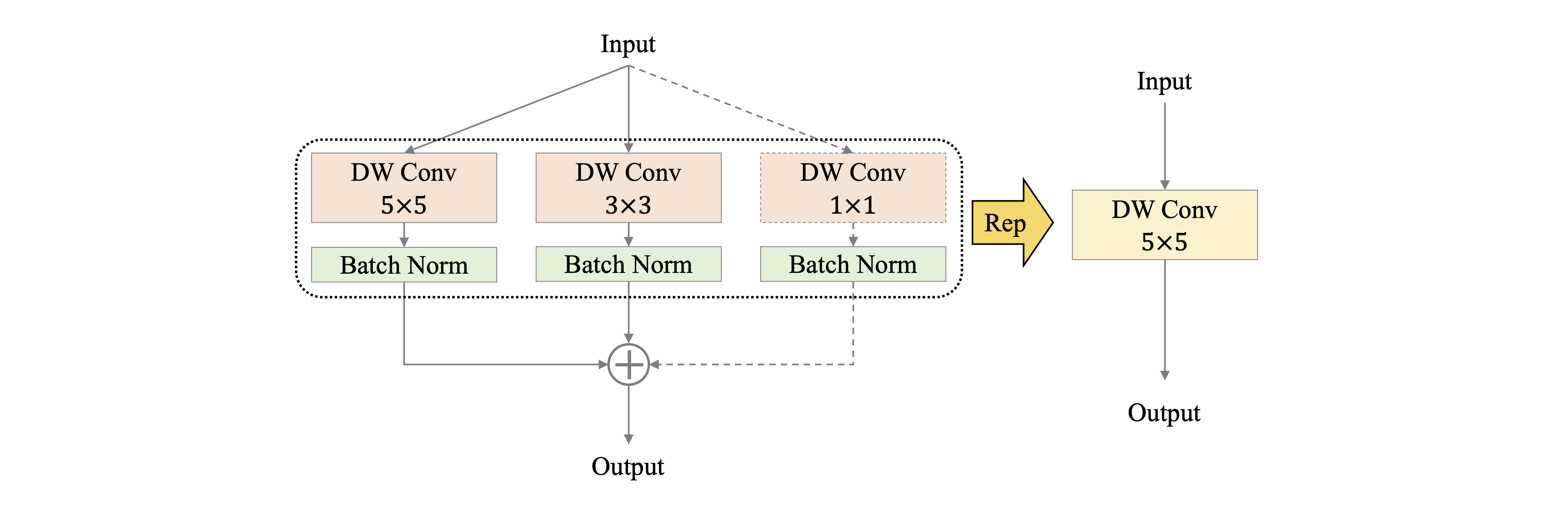
docs/images/PP-LCNetV2/rep.png
0 → 100644
{kind=link}
202.7 KB
{kind=link}
99.7 KB
{kind=link}

96.6 KB
275.1 KB
202.7 KB
99.7 KB
96.6 KB