- Windows 环境,目前支持基于 `Visual Studio 2019 Community` 进行编译;此外,如果您希望通过生成 `sln解决方案` 的方式进行编译,可以参考该文档:[https://zhuanlan.zhihu.com/p/145446681](https://zhuanlan.zhihu.com/p/145446681)
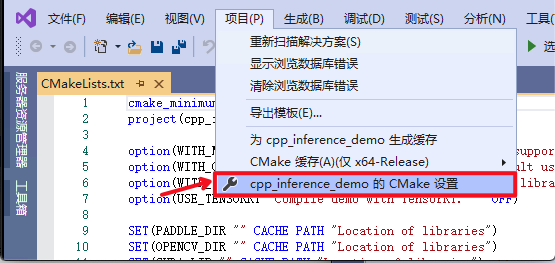
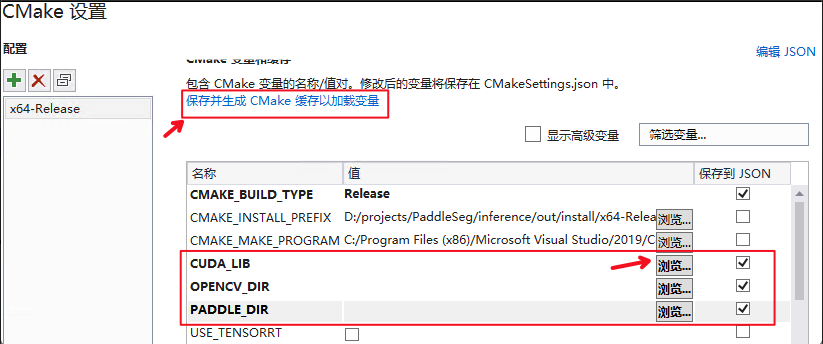
* 该文档主要介绍基于 Linux 环境下的 PaddleClas C++ 预测流程,如果需要在 Windows 环境下使用预测库进行 C++ 预测,具体编译方法请参考 [Windows下编译教程](./docs/windows_vs2019_build.md)。
### 1.1 编译opencv库
* 首先需要从 opencv 官网上下载在 Linux 环境下源码编译的包,以 3.4.7 版本为例,下载及解压缩命令如下:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}