Add FAQ 20201207 (#459)
* Add FAQ 20201207 * Fix FAQ20201207
Showing
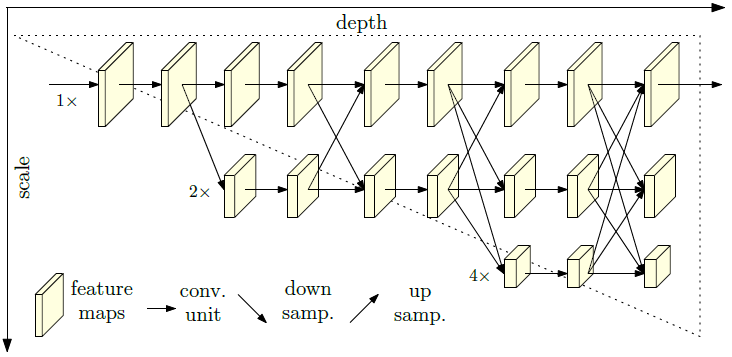
docs/images/faq/HRNet.png
0 → 100644
{kind=link}
30.3 KB
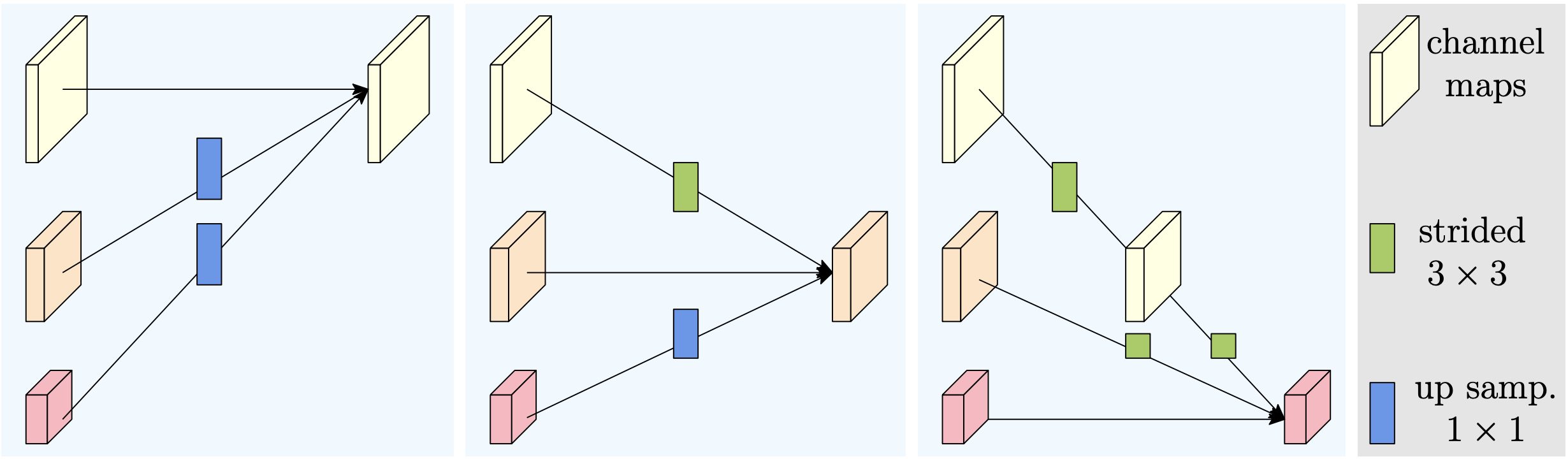
docs/images/faq/HRNet_block.png
0 → 100644
{kind=link}
144.6 KB
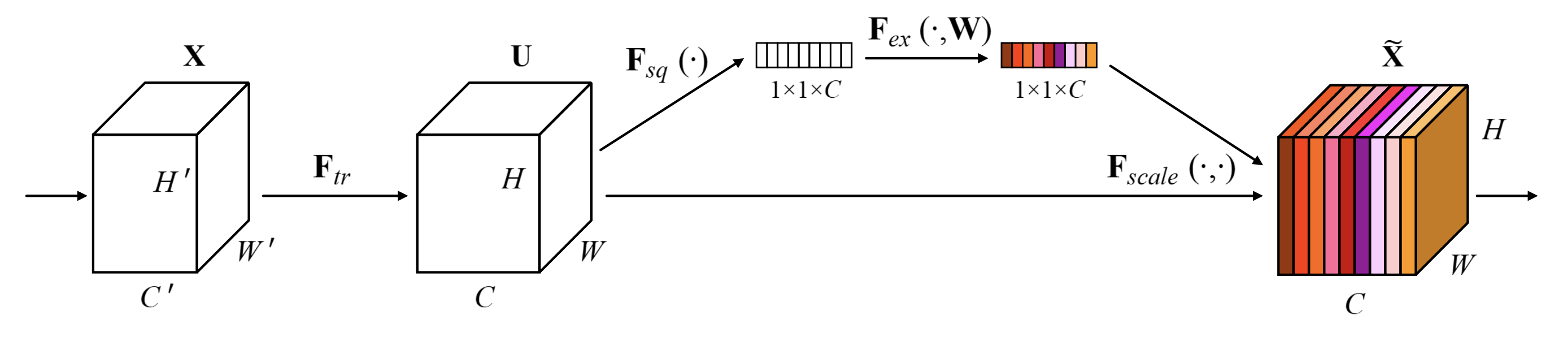
docs/images/faq/SE_structure.png
0 → 100644
{kind=link}
131.6 KB