Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleClas
提交
af9b7e81
P
PaddleClas
项目概览
PaddlePaddle
/
PaddleClas
大约 2 年 前同步成功
通知
118
Star
4999
Fork
1114
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
19
列表
看板
标记
里程碑
合并请求
6
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleClas
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
19
Issue
19
列表
看板
标记
里程碑
合并请求
6
合并请求
6
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
af9b7e81
编写于
10月 14, 2021
作者:
C
cuicheng01
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Update PP-LCNet docs
上级
626c4f12
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
7 addition
and
2 deletion
+7
-2
README_ch.md
README_ch.md
+1
-1
docs/images/PP-LCNet/PP-LCNet-Acc.png
docs/images/PP-LCNet/PP-LCNet-Acc.png
+0
-0
docs/images/PP-LCNet/PP-LCNet.png
docs/images/PP-LCNet/PP-LCNet.png
+0
-0
docs/zh_CN/models/PPLCNet.md
docs/zh_CN/models/PPLCNet.md
+6
-1
未找到文件。
README_ch.md
浏览文件 @
af9b7e81
...
...
@@ -7,7 +7,7 @@
飞桨图像识别套件PaddleClas是飞桨为工业界和学术界所准备的一个图像识别任务的工具集,助力使用者训练出更好的视觉模型和应用落地。
**近期更新**
-
2021.09.17 增加PaddleClas自研PP-LCNet系列模型, 这些模型在Intel CPU上有较强的竞争力。PP-LCNet的介绍可以参考
[
论文
](
https://arxiv.org/pdf/2109.15099.pdf
)
或者
[
模型介绍
](
docs/zh_CN/models/PPLCNet.md
)
,相关指标和预训练权重可以从
[
这里
](
docs/zh_CN/ImageNet_models_
zh
.md
)
下载。
-
2021.09.17 增加PaddleClas自研PP-LCNet系列模型, 这些模型在Intel CPU上有较强的竞争力。PP-LCNet的介绍可以参考
[
论文
](
https://arxiv.org/pdf/2109.15099.pdf
)
或者
[
模型介绍
](
docs/zh_CN/models/PPLCNet.md
)
,相关指标和预训练权重可以从
[
这里
](
docs/zh_CN/ImageNet_models_
cn
.md
)
下载。
-
2021.08.11 更新7个
[
FAQ
](
docs/zh_CN/faq_series/faq_2021_s2.md
)
。
-
2021.06.29 添加Swin-transformer系列模型,ImageNet1k数据集上Top1 acc最高精度可达87.2%;支持训练预测评估与whl包部署,预训练模型可以从
[
这里
](
docs/zh_CN/models/models_intro.md
)
下载。
-
2021.06.22,23,24 PaddleClas官方研发团队带来技术深入解读三日直播课。课程回放:
[
https://aistudio.baidu.com/aistudio/course/introduce/24519
](
https://aistudio.baidu.com/aistudio/course/introduce/24519
)
...
...
docs/images/PP-LCNet/PP-LCNet-Acc.png
0 → 100644
浏览文件 @
af9b7e81
211.5 KB
docs/images/PP-LCNet/PP-LCNet.png
0 → 100644
浏览文件 @
af9b7e81
898.6 KB
docs/zh_CN/models/PPLCNet.md
浏览文件 @
af9b7e81
...
...
@@ -7,10 +7,15 @@
## 介绍
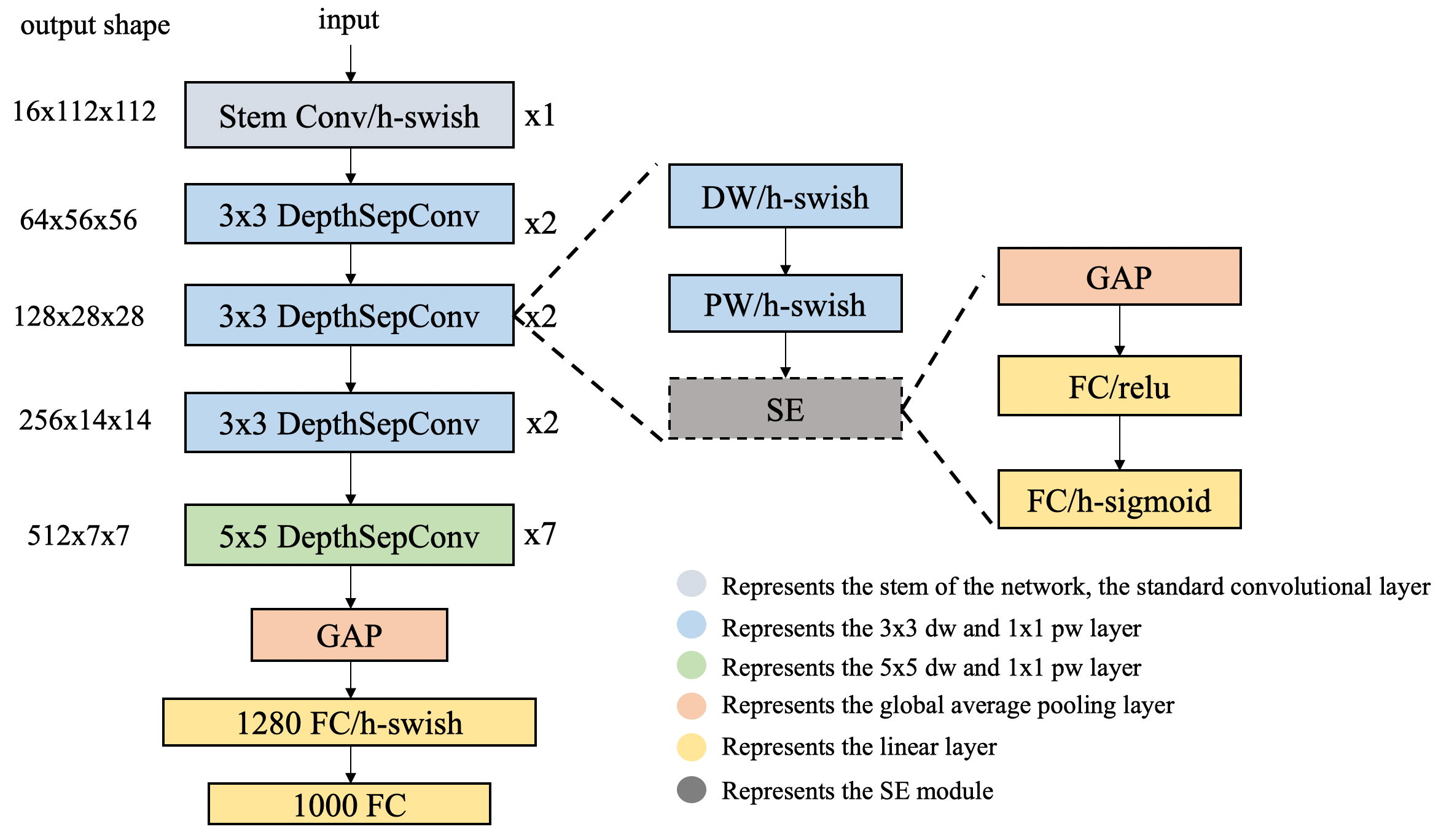
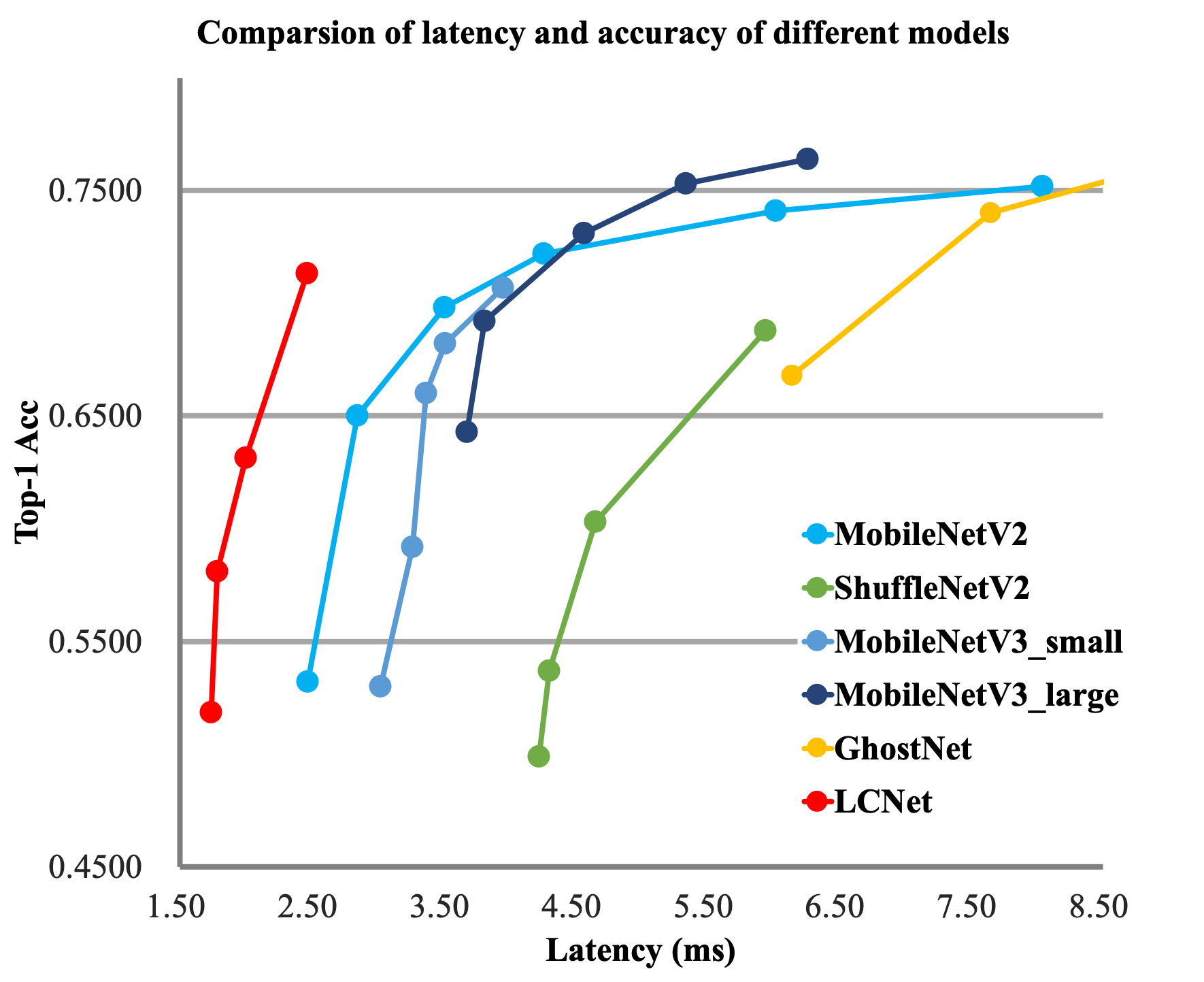
近年来,有很多轻量级的骨干网络问世,尤其最近两年,各种NAS搜索出的网络层出不穷,这些网络要么主打FLOPs或者Params上的优势,要么主打ARM设备上的推理速度的优势,很少有网络专门针对Intel CPU做特定的优化,导致这些网络在Intel CPU端的推理速度并不是很完美。基于此,我们针对Intel CPU设备以及其加速库MKLDNN设计了特定的骨干网络PP-LCNet,比起其他的轻量级的SOTA模型,该骨干网络可以在不增加推理时间的情况下,进一步提升模型的性能,最终大幅度超越现有的SOTA模型。与其他模型的对比图如下。

## 方法
网络结构整体如上图所示,我们经过大量的实验发现,在基于Intel CPU设备上,尤其当启用MKLDNN加速库后,很多看似不太耗时的操作反而会增加延时,比如elementwise-add操作、split-concat结构等。所以最终我们选用了结构尽可能精简、速度尽可能快的block组成我们的BaseNet(类似MobileNetV1)。基于BaseNet,我们通过实验,总结了四条几乎不增加延时但是可以提升模型精度的方法,融合这四条策略,我们组合成了PP-LCNet。下面对这四条策略一一介绍:
网络结构整体如下图所示。

我们经过大量的实验发现,在基于Intel CPU设备上,尤其当启用MKLDNN加速库后,很多看似不太耗时的操作反而会增加延时,比如elementwise-add操作、split-concat结构等。所以最终我们选用了结构尽可能精简、速度尽可能快的block组成我们的BaseNet(类似MobileNetV1)。基于BaseNet,我们通过实验,总结了四条几乎不增加延时但是可以提升模型精度的方法,融合这四条策略,我们组合成了PP-LCNet。下面对这四条策略一一介绍:
### 更好的激活函数
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}