Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleClas
提交
944763d7
P
PaddleClas
项目概览
PaddlePaddle
/
PaddleClas
接近 2 年 前同步成功
通知
116
Star
4999
Fork
1114
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
19
列表
看板
标记
里程碑
合并请求
6
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleClas
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
19
Issue
19
列表
看板
标记
里程碑
合并请求
6
合并请求
6
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
944763d7
编写于
10月 25, 2022
作者:
D
dongshuilong
提交者:
Walter
10月 25, 2022
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add fixmatch
上级
e1b2b6a8
变更
20
隐藏空白更改
内联
并排
Showing
20 changed file
with
1378 addition
and
30 deletion
+1378
-30
docs/zh_CN/training/semi_supervised_learning/FixMatch.md
docs/zh_CN/training/semi_supervised_learning/FixMatch.md
+206
-0
ppcls/arch/backbone/__init__.py
ppcls/arch/backbone/__init__.py
+1
-0
ppcls/arch/backbone/model_zoo/wideresnet.py
ppcls/arch/backbone/model_zoo/wideresnet.py
+238
-0
ppcls/configs/ssl/FixMatch/FixMatch_cifar10_250.yaml
ppcls/configs/ssl/FixMatch/FixMatch_cifar10_250.yaml
+175
-0
ppcls/configs/ssl/FixMatch/FixMatch_cifar10_40.yaml
ppcls/configs/ssl/FixMatch/FixMatch_cifar10_40.yaml
+175
-0
ppcls/configs/ssl/FixMatch/FixMatch_cifar10_4000.yaml
ppcls/configs/ssl/FixMatch/FixMatch_cifar10_4000.yaml
+175
-0
ppcls/data/__init__.py
ppcls/data/__init__.py
+4
-2
ppcls/data/dataloader/__init__.py
ppcls/data/dataloader/__init__.py
+1
-0
ppcls/data/dataloader/cifar.py
ppcls/data/dataloader/cifar.py
+115
-0
ppcls/data/dataloader/common_dataset.py
ppcls/data/dataloader/common_dataset.py
+2
-0
ppcls/data/preprocess/__init__.py
ppcls/data/preprocess/__init__.py
+1
-0
ppcls/engine/engine.py
ppcls/engine/engine.py
+28
-14
ppcls/engine/train/__init__.py
ppcls/engine/train/__init__.py
+1
-0
ppcls/engine/train/train.py
ppcls/engine/train/train.py
+1
-1
ppcls/engine/train/train_fixmatch.py
ppcls/engine/train/train_fixmatch.py
+165
-0
ppcls/engine/train/utils.py
ppcls/engine/train/utils.py
+6
-5
ppcls/loss/__init__.py
ppcls/loss/__init__.py
+2
-0
ppcls/loss/celoss.py
ppcls/loss/celoss.py
+8
-3
ppcls/optimizer/learning_rate.py
ppcls/optimizer/learning_rate.py
+45
-2
ppcls/optimizer/optimizer.py
ppcls/optimizer/optimizer.py
+29
-3
未找到文件。
docs/zh_CN/training/semi_supervised_learning/FixMatch.md
0 → 100644
浏览文件 @
944763d7
**简体中文 | English(TODO)**
# FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
**论文出处:**
[
https://arxiv.org/abs/2001.07685
](
https://arxiv.org/abs/2001.07685
)
## 目录
*
[
1. 原理介绍
](
#1-%E5%8E%9F%E7%90%86%E4%BB%8B%E7%BB%8D
)
*
[
2. 精度指标
](
#2-%E7%B2%BE%E5%BA%A6%E6%8C%87%E6%A0%87
)
*
[
3. 数据准备
](
#3-%E6%95%B0%E6%8D%AE%E5%87%86%E5%A4%87
)
*
[
4. 模型训练
](
#4-%E6%A8%A1%E5%9E%8B%E8%AE%AD%E7%BB%83
)
*
[
5. 模型评估与推理部署
](
#5-%E6%A8%A1%E5%9E%8B%E8%AF%84%E4%BC%B0%E4%B8%8E%E6%8E%A8%E7%90%86%E9%83%A8%E7%BD%B2
)
*
[
5.1 模型评估
](
#51-%E6%A8%A1%E5%9E%8B%E8%AF%84%E4%BC%B0
)
*
[
5.2 模型推理
](
#52-%E6%A8%A1%E5%9E%8B%E6%8E%A8%E7%90%86
)
*
[
5.2.1 推理模型准备
](
#521-%E6%8E%A8%E7%90%86%E6%A8%A1%E5%9E%8B%E5%87%86%E5%A4%87
)
*
[
5.2.2 基于 Python 预测引擎推理
](
#522-%E5%9F%BA%E4%BA%8E-python-%E9%A2%84%E6%B5%8B%E5%BC%95%E6%93%8E%E6%8E%A8%E7%90%86
)
*
[
5.2.3 基于 C++ 预测引擎推理
](
#523-%E5%9F%BA%E4%BA%8E-c-%E9%A2%84%E6%B5%8B%E5%BC%95%E6%93%8E%E6%8E%A8%E7%90%86
)
*
[
5.4 服务化部署
](
#54-%E6%9C%8D%E5%8A%A1%E5%8C%96%E9%83%A8%E7%BD%B2
)
*
[
5.5 端侧部署
](
#55-%E7%AB%AF%E4%BE%A7%E9%83%A8%E7%BD%B2
)
*
[
5.6 Paddle2ONNX 模型转换与预测
](
#56-paddle2onnx-%E6%A8%A1%E5%9E%8B%E8%BD%AC%E6%8D%A2%E4%B8%8E%E9%A2%84%E6%B5%8B
)
*
[
6. 参考资料
](
#6-%E5%8F%82%E8%80%83%E8%B5%84%E6%96%99
)
## 1. 原理介绍
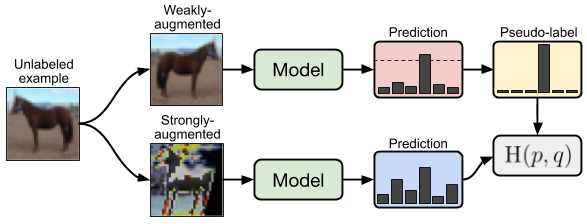
**作者提出一种简单而有效的半监督学习方法。主要是在有标签的数据训练的同时,对无标签的数据进行强弱两种不同的数据增强。如果无标签的数据弱数据增强的分类结果,大于阈值,则弱数据增强的输出标签作为软标签,对强数据增强的输出进行loss计算及模型训练。如示例图所示。**
## 2. 精度指标
**以下表格总结了复现的 FixMatch在 Cifar10 数据集上的精度指标。**
|
**Labels**
|
**40**
|
**250**
|
**4000**
|
| ---------------------------- | ----------------------- | ----------------------- | ----------------------- |
|
**Paper (tensorflow)**
|
**86.19 ± 3.37**
|
**94.93 ± 0.65**
|
**95.74 ± 0.05**
|
|
**pytorch版本**
|
**93.60**
|
**95.31**
|
**95.77**
|
|
**paddle版本**
|
**93.14**
|
**95.37**
|
**95.89**
|
**cifar10上,paddle版本配置文件及训练好的模型如下表所示**
|
**label**
|
**配置文件地址**
|
**模型下载链接**
|
| --------------- | -------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------ |
|
**40**
|
[
配置文件
](
../../../../ppcls/configs/ssl/FixMatch/FixMatch_cifar10_40.yaml
)
|
[
模型地址
](
https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/semi_superwised_learning/FixMatch_WideResNet_cifar10_label40.pdparams
)
|
|
**250**
|
[
配置文件
](
../../../../ppcls/configs/ssl/FixMatch/FixMatch_cifar10_250.yaml
)
|
[
模型地址
](
https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/semi_superwised_learning/FixMatch_WideResNet_cifar10_label250.pdparams
)
|
|
**4000**
|
[
配置文件
](
../../../../ppcls/configs/ssl/FixMatch/FixMatch_cifar10_4000.yaml
)
|
[
模型地址
](
https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/semi_superwised_learning/FixMatch_WideResNet_cifar10_label4000.pdparams
)
|
**接下来主要以**
`FixMatch/FixMatch_cifar10_40.yaml`
配置和训练好的模型文件为例,展示在cifar10数据集上进行训练、测试、推理的过程。
## 3. 数据准备
在训练及测试的过程中,cifar10数据集会自动下载,请保持联网。如网络问题,则提前下载好
[
相关数据
](
https://dataset.bj.bcebos.com/cifar/cifar-10-python.tar.gz
)
,并在以下命令中,添加如下参数
```
${cmd} -o DataLoader.Train.dataset.data_file=${data_file} -o DataLoader.UnLabelTrain.dataset.data_file=${data_file} -o DataLoader.Eval.dataset.data_file=${data_file}
```
**其中:**
`${cmd}`
为以下的命令,
`${data_file}`
是下载数据的路径。如4.1中单卡命令就改为:
```
shell
python tools/train.py
-c
ppcls/configs/ssl/FixMatch/FixMatch_cifar10_40.yaml
-o
DataLoader.Train.dataset.data_file
=
cifar-10-python.tar.gz
-o
DataLoader.UnLabelTrain.dataset.data_file
=
cifar-10-python.tar.gz
-o
DataLoader.Eval.dataset.data_file
=
cifar-10-python.tar.gz
```
## 4. 模型训练
1.
**执行以下命令开始训练**
**单卡训练:**
```
python tools/train.py -c ppcls/configs/ssl/FixMatch/FixMatch_cifar10_40.yaml
```
**注:单卡训练大约需要2-4个天。**
2.
**查看训练日志和保存的模型参数文件**
训练过程中会在屏幕上实时打印loss等指标信息,同时会保存日志文件
`train.log`
、模型参数文件
`*.pdparams`
、优化器参数文件
`*.pdopt`
等内容到
`Global.output_dir`
指定的文件夹下,默认在
`PaddleClas/output/WideResNet/`
文件夹下。
## 5. 模型评估与推理部署
### 5.1 模型评估
准备用于评估的
`*.pdparams`
模型参数文件,可以使用训练好的模型,也可以使用
[
4. 模型训练
](
#4-%E6%A8%A1%E5%9E%8B%E8%AE%AD%E7%BB%83
)
中保存的模型。
*
以训练过程中保存的
`best_model_ema.ema.pdparams`
为例,执行如下命令即可进行评估。
```
python3.7 tools/eval.py \
-c ppcls/configs/ssl/FixMatch/FixMatch_cifar10_40.yaml \
-o Global.pretrained_model="./output/WideResNet/best_model_ema.ema"
```
*
以训练好的模型为例,下载提供的已经训练好的模型,到
`PaddleClas/pretrained_models`
文件夹中,执行如下命令即可进行评估。
```
# 下载模型
cd PaddleClas
mkdir pretrained_models
cd pretrained_models
wget https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/semi_superwised_learning/FixMatch_WideResNet_cifar10_label40.pdparams
cd ..
# 评估
python3.7 tools/eval.py \
-c ppcls/configs/ssl/FixMatch/FixMatch_cifar10_40.yaml \
-o Global.pretrained_model="pretrained_models/FixMatch_WideResNet_cifar10_label40"
```
**注:**
`pretrained_model`
后填入的地址不需要加
`.pdparams`
后缀,在程序运行时会自动补上。
*
查看输出结果
```
...
...
CELoss: 0.58960, loss: 0.58960, top1: 0.95312, top5: 0.98438, batch_cost: 3.00355s, reader_cost: 1.09548, ips: 21.30810 images/sec
ppcls INFO: [Eval][Epoch 0][Iter: 20/157]CELoss: 0.14618, loss: 0.14618, top1: 0.93601, top5: 0.99628, batch_cost: 0.02379s, reader_cost: 0.00016, ips: 2690.05243 images/sec
ppcls INFO: [Eval][Epoch 0][Iter: 40/157]CELoss: 0.01801, loss: 0.01801, top1: 0.93216, top5: 0.99505, batch_cost: 0.02716s, reader_cost: 0.00015, ips: 2356.48846 images/sec
ppcls INFO: [Eval][Epoch 0][Iter: 60/157]CELoss: 0.63351, loss: 0.63351, top1: 0.92982, top5: 0.99539, batch_cost: 0.02585s, reader_cost: 0.00015, ips: 2475.86506 images/sec
ppcls INFO: [Eval][Epoch 0][Iter: 80/157]CELoss: 0.85084, loss: 0.85084, top1: 0.93191, top5: 0.99576, batch_cost: 0.02578s, reader_cost: 0.00015, ips: 2482.59021 images/sec
ppcls INFO: [Eval][Epoch 0][Iter: 100/157]CELoss: 0.04171, loss: 0.04171, top1: 0.93147, top5: 0.99567, batch_cost: 0.02676s, reader_cost: 0.00015, ips: 2391.99053 images/sec
ppcls INFO: [Eval][Epoch 0][Iter: 120/157]CELoss: 0.89842, loss: 0.89842, top1: 0.93027, top5: 0.99561, batch_cost: 0.02647s, reader_cost: 0.00015, ips: 2418.24635 images/sec
ppcls INFO: [Eval][Epoch 0][Iter: 140/157]CELoss: 0.57866, loss: 0.57866, top1: 0.93107, top5: 0.99568, batch_cost: 0.02678s, reader_cost: 0.00015, ips: 2389.46068 images/sec
ppcls INFO: [Eval][Epoch 0][Avg]CELoss: 0.59721, loss: 0.59721, top1: 0.93140, top5: 0.99570
```
默认评估日志保存在
`PaddleClas/output/WideResNet/eval.log`
中,可以看到我们提供的模型在 cifar10 数据集上的评估指标为top1: 0.93140, top5: 0.99570
### 5.2 模型推理
#### 5.2.1 推理模型准备
将训练过程中保存的模型文件转换成 inference 模型,同样以
`best_model_ema.ema.pdparams`
为例,执行以下命令进行转换
```
python3.7 tools/export_model.py \
-c ppcls/configs/ssl/FixMatch_cifar10_40.yaml \
-o -o Global.pretrained_model=output/WideResNet/best_model_ema.ema \
-o Global.save_inference_dir="./deploy/inference"
```
#### 5.2.2 基于 Python 预测引擎推理
1.
修改
`PaddleClas/deploy/configs/inference_cls.yaml`
-
将
`infer_imgs:`
后的路径段改为 query 文件夹下的任意一张图片路径(下方配置使用的是
`demo.jpg`
图片的路径)
-
将
`rec_inference_model_dir:`
后的字段改为解压出来的 inference模型文件夹路径
-
将
`transform_ops:`
字段下的预处理配置改为
`FixMatch_cifar10_40.yaml`
中
`Eval.dataset`
下的预处理配置
```
Global:
infer_imgs: "demo"
rec_inference_model_dir: "./inferece"
batch_size: 1
use_gpu: False
enable_mkldnn: True
cpu_num_threads: 10
enable_benchmark: False
use_fp16: False
ir_optim: True
use_tensorrt: False
gpu_mem: 8000
enable_profile: False
RecPreProcess:
transform_ops:
- NormalizeImage:
scale: 1.0/255.0
mean: [0.4914, 0.4822, 0.4465]
std: [0.2471, 0.2435, 0.2616]
order: hwc
PostProcess: null
```
2.
执行推理命令
```
cd ./deploy/
python3.7 python/predict_rec.py -c ./configs/inference_rec.yaml
```
3.
查看输出结果,实际结果为一个长度10的向量,表示图像分类的结果,如
```
demo.JPG: [ 0.02560742 0.05221584 ... 0.11635944 -0.18817757
0.07170864]
```
#### 5.2.3 基于 C++ 预测引擎推理
PaddleClas 提供了基于 C++ 预测引擎推理的示例,您可以参考
[
服务器端 C++ 预测
](
../../deployment/image_classification/cpp/linux.md
)
来完成相应的推理部署。如果您使用的是 Windows 平台,可以参考基于 Visual Studio 2019 Community CMake 编译指南完成相应的预测库编译和模型预测工作。
### 5.4 服务化部署
Paddle Serving 提供高性能、灵活易用的工业级在线推理服务。Paddle Serving 支持 RESTful、gRPC、bRPC 等多种协议,提供多种异构硬件和多种操作系统环境下推理解决方案。更多关于Paddle Serving 的介绍,可以参考Paddle Serving 代码仓库。
PaddleClas 提供了基于 Paddle Serving 来完成模型服务化部署的示例,您可以参考
[
模型服务化部署
](
../../deployment/PP-ShiTu/paddle_serving.md
)
来完成相应的部署工作。
### 5.5 端侧部署
Paddle Lite 是一个高性能、轻量级、灵活性强且易于扩展的深度学习推理框架,定位于支持包括移动端、嵌入式以及服务器端在内的多硬件平台。更多关于 Paddle Lite 的介绍,可以参考Paddle Lite 代码仓库。
PaddleClas 提供了基于 Paddle Lite 来完成模型端侧部署的示例,您可以参考
[
端侧部署
](
../../deployment/image_classification/paddle_lite.md
)
来完成相应的部署工作。
### 5.6 Paddle2ONNX 模型转换与预测
Paddle2ONNX 支持将 PaddlePaddle 模型格式转化到 ONNX 模型格式。通过 ONNX 可以完成将 Paddle 模型到多种推理引擎的部署,包括TensorRT/OpenVINO/MNN/TNN/NCNN,以及其它对 ONNX 开源格式进行支持的推理引擎或硬件。更多关于 Paddle2ONNX 的介绍,可以参考Paddle2ONNX 代码仓库。
PaddleClas 提供了基于 Paddle2ONNX 来完成 inference 模型转换 ONNX 模型并作推理预测的示例,您可以参考
**
[
Paddle2ONNX 模型转换与预测
](
../../deployment/image_classification/paddle2onnx.md
)
来完成相应的部署工作。
### 6. 参考资料
1.
[
FixMatch
](
https://arxiv.org/abs/2001.07685
)
ppcls/arch/backbone/__init__.py
浏览文件 @
944763d7
...
@@ -77,6 +77,7 @@ from .variant_models.vgg_variant import VGG19Sigmoid
...
@@ -77,6 +77,7 @@ from .variant_models.vgg_variant import VGG19Sigmoid
from
.variant_models.pp_lcnet_variant
import
PPLCNet_x2_5_Tanh
from
.variant_models.pp_lcnet_variant
import
PPLCNet_x2_5_Tanh
from
.variant_models.pp_lcnetv2_variant
import
PPLCNetV2_base_ShiTu
from
.variant_models.pp_lcnetv2_variant
import
PPLCNetV2_base_ShiTu
from
.model_zoo.adaface_ir_net
import
AdaFace_IR_18
,
AdaFace_IR_34
,
AdaFace_IR_50
,
AdaFace_IR_101
,
AdaFace_IR_152
,
AdaFace_IR_SE_50
,
AdaFace_IR_SE_101
,
AdaFace_IR_SE_152
,
AdaFace_IR_SE_200
from
.model_zoo.adaface_ir_net
import
AdaFace_IR_18
,
AdaFace_IR_34
,
AdaFace_IR_50
,
AdaFace_IR_101
,
AdaFace_IR_152
,
AdaFace_IR_SE_50
,
AdaFace_IR_SE_101
,
AdaFace_IR_SE_152
,
AdaFace_IR_SE_200
from
.model_zoo.wideresnet
import
WideResNet
# help whl get all the models' api (class type) and components' api (func type)
# help whl get all the models' api (class type) and components' api (func type)
...
...
ppcls/arch/backbone/model_zoo/wideresnet.py
0 → 100644
浏览文件 @
944763d7
import
paddle
import
paddle.nn
as
nn
import
paddle.nn.functional
as
F
from
paddle
import
ParamAttr
"""
backbone option "WideResNet"
code in this file is adpated from
https://github.com/kekmodel/FixMatch-pytorch/blob/master/models/wideresnet.py
thanks!
"""
def
mish
(
x
):
"""Mish: A Self Regularized Non-Monotonic Neural Activation Function (https://arxiv.org/abs/1908.08681)"""
return
x
*
paddle
.
tanh
(
F
.
softplus
(
x
))
class
PSBatchNorm2D
(
nn
.
BatchNorm2D
):
"""How Does BN Increase Collapsed Neural Network Filters? (https://arxiv.org/abs/2001.11216)"""
def
__init__
(
self
,
num_features
,
alpha
=
0.1
,
eps
=
1e-05
,
momentum
=
0.999
,
weight_attr
=
None
,
bias_attr
=
None
):
super
().
__init__
(
num_features
,
momentum
,
eps
,
weight_attr
,
bias_attr
)
self
.
alpha
=
alpha
def
forward
(
self
,
x
):
return
super
().
forward
(
x
)
+
self
.
alpha
class
BasicBlock
(
nn
.
Layer
):
def
__init__
(
self
,
in_planes
,
out_planes
,
stride
,
drop_rate
=
0.0
,
activate_before_residual
=
False
):
super
(
BasicBlock
,
self
).
__init__
()
self
.
bn1
=
nn
.
BatchNorm2D
(
in_planes
,
momentum
=
0.999
)
self
.
relu1
=
nn
.
LeakyReLU
(
negative_slope
=
0.1
)
self
.
conv1
=
nn
.
Conv2D
(
in_planes
,
out_planes
,
kernel_size
=
3
,
stride
=
stride
,
padding
=
1
,
bias_attr
=
False
)
self
.
bn2
=
nn
.
BatchNorm2D
(
out_planes
,
momentum
=
0.999
)
self
.
relu2
=
nn
.
LeakyReLU
(
negative_slope
=
0.1
)
self
.
conv2
=
nn
.
Conv2D
(
out_planes
,
out_planes
,
kernel_size
=
3
,
stride
=
1
,
padding
=
1
,
bias_attr
=
False
)
self
.
drop_rate
=
drop_rate
self
.
equalInOut
=
(
in_planes
==
out_planes
)
self
.
convShortcut
=
(
not
self
.
equalInOut
)
and
nn
.
Conv2D
(
in_planes
,
out_planes
,
kernel_size
=
1
,
stride
=
stride
,
padding
=
0
,
bias_attr
=
False
)
or
None
self
.
activate_before_residual
=
activate_before_residual
def
forward
(
self
,
x
):
if
not
self
.
equalInOut
and
self
.
activate_before_residual
==
True
:
x
=
self
.
relu1
(
self
.
bn1
(
x
))
else
:
out
=
self
.
relu1
(
self
.
bn1
(
x
))
out
=
self
.
relu2
(
self
.
bn2
(
self
.
conv1
(
out
if
self
.
equalInOut
else
x
)))
if
self
.
drop_rate
>
0
:
out
=
F
.
dropout
(
out
,
p
=
self
.
drop_rate
,
training
=
self
.
training
)
out
=
self
.
conv2
(
out
)
return
paddle
.
add
(
x
if
self
.
equalInOut
else
self
.
convShortcut
(
x
),
out
)
class
NetworkBlock
(
nn
.
Layer
):
def
__init__
(
self
,
nb_layers
,
in_planes
,
out_planes
,
block
,
stride
,
drop_rate
=
0.0
,
activate_before_residual
=
False
):
super
(
NetworkBlock
,
self
).
__init__
()
self
.
layer
=
self
.
_make_layer
(
block
,
in_planes
,
out_planes
,
nb_layers
,
stride
,
drop_rate
,
activate_before_residual
)
def
_make_layer
(
self
,
block
,
in_planes
,
out_planes
,
nb_layers
,
stride
,
drop_rate
,
activate_before_residual
):
layers
=
[]
for
i
in
range
(
int
(
nb_layers
)):
layers
.
append
(
block
(
i
==
0
and
in_planes
or
out_planes
,
out_planes
,
i
==
0
and
stride
or
1
,
drop_rate
,
activate_before_residual
))
return
nn
.
Sequential
(
*
layers
)
def
forward
(
self
,
x
):
return
self
.
layer
(
x
)
class
Normalize
(
nn
.
Layer
):
""" Ln normalization copied from
https://github.com/salesforce/CoMatch
"""
def
__init__
(
self
,
power
=
2
):
super
(
Normalize
,
self
).
__init__
()
self
.
power
=
power
def
forward
(
self
,
x
):
norm
=
x
.
pow
(
self
.
power
).
sum
(
1
,
keepdim
=
True
).
pow
(
1.
/
self
.
power
)
out
=
x
.
divide
(
norm
)
return
out
class
Wide_ResNet
(
nn
.
Layer
):
def
__init__
(
self
,
num_classes
,
depth
=
28
,
widen_factor
=
2
,
drop_rate
=
0.0
,
proj
=
False
,
proj_after
=
False
,
low_dim
=
64
):
super
(
Wide_ResNet
,
self
).
__init__
()
# prepare self values
self
.
widen_factor
=
widen_factor
self
.
depth
=
depth
self
.
drop_rate
=
drop_rate
# if use projection head
self
.
proj
=
proj
# if use the output of projection head for classification
self
.
proj_after
=
proj_after
self
.
low_dim
=
low_dim
channels
=
[
16
,
16
*
widen_factor
,
32
*
widen_factor
,
64
*
widen_factor
]
assert
((
depth
-
4
)
%
6
==
0
)
n
=
(
depth
-
4
)
/
6
block
=
BasicBlock
# 1st conv before any network block
self
.
conv1
=
nn
.
Conv2D
(
3
,
channels
[
0
],
kernel_size
=
3
,
stride
=
1
,
padding
=
1
,
bias_attr
=
False
)
# 1st block
self
.
block1
=
NetworkBlock
(
n
,
channels
[
0
],
channels
[
1
],
block
,
1
,
drop_rate
,
activate_before_residual
=
True
)
# 2nd block
self
.
block2
=
NetworkBlock
(
n
,
channels
[
1
],
channels
[
2
],
block
,
2
,
drop_rate
)
# 3rd block
self
.
block3
=
NetworkBlock
(
n
,
channels
[
2
],
channels
[
3
],
block
,
2
,
drop_rate
)
# global average pooling and classifier
self
.
bn1
=
nn
.
BatchNorm2D
(
channels
[
3
],
momentum
=
0.999
)
self
.
relu
=
nn
.
LeakyReLU
(
negative_slope
=
0.1
)
# if proj after means we classify after projection head
# so we must change the in channel to low_dim of laster fc
if
self
.
proj_after
:
self
.
fc
=
nn
.
Linear
(
self
.
low_dim
,
num_classes
)
else
:
self
.
fc
=
nn
.
Linear
(
channels
[
3
],
num_classes
)
self
.
channels
=
channels
[
3
]
# projection head
if
self
.
proj
:
self
.
l2norm
=
Normalize
(
2
)
self
.
fc1
=
nn
.
Linear
(
64
*
self
.
widen_factor
,
64
*
self
.
widen_factor
)
self
.
relu_mlp
=
nn
.
LeakyReLU
(
negative_slope
=
0.1
)
self
.
fc2
=
nn
.
Linear
(
64
*
self
.
widen_factor
,
self
.
low_dim
)
def
forward
(
self
,
x
):
feat
=
self
.
conv1
(
x
)
feat
=
self
.
block1
(
feat
)
feat
=
self
.
block2
(
feat
)
feat
=
self
.
block3
(
feat
)
feat
=
self
.
relu
(
self
.
bn1
(
feat
))
feat
=
F
.
adaptive_avg_pool2d
(
feat
,
1
)
feat
=
paddle
.
reshape
(
feat
,
[
-
1
,
self
.
channels
])
if
self
.
proj
:
pfeat
=
self
.
fc1
(
feat
)
pfeat
=
self
.
relu_mlp
(
pfeat
)
pfeat
=
self
.
fc2
(
pfeat
)
pfeat
=
self
.
l2norm
(
pfeat
)
# if projection after classifiy, we classify last
if
self
.
proj_after
:
out
=
self
.
fc
(
pfeat
)
else
:
out
=
self
.
fc
(
feat
)
return
out
,
pfeat
# output
out
=
self
.
fc
(
feat
)
return
out
def
WideResNet
(
depth
,
widen_factor
,
dropout
,
num_classes
,
proj
=
False
,
low_dim
=
64
,
**
kwargs
):
return
Wide_ResNet
(
depth
=
depth
,
widen_factor
=
widen_factor
,
drop_rate
=
dropout
,
num_classes
=
num_classes
,
proj
=
proj
,
low_dim
=
low_dim
,
**
kwargs
)
ppcls/configs/ssl/FixMatch/FixMatch_cifar10_250.yaml
0 → 100644
浏览文件 @
944763d7
# global configs
Global
:
checkpoints
:
null
pretrained_model
:
'
../test/torch2paddle_cifar10'
output_dir
:
./output_25
device
:
gpu
save_interval
:
-1
eval_during_train
:
True
eval_interval
:
1
epochs
:
1024
iter_per_epoch
:
1024
print_batch_step
:
20
use_visualdl
:
False
use_dali
:
False
train_mode
:
fixmatch
# used for static mode and model export
image_shape
:
[
3
,
224
,
224
]
save_inference_dir
:
./inference
SSL
:
tempture
:
1
threshold
:
0.95
EMA
:
decay
:
0.999
# AMP:
# scale_loss: 65536
# use_dynamic_loss_scaling: True
# # O1: mixed fp16
# level: O1
# model architecture
Arch
:
name
:
WideResNet
depth
:
28
widen_factor
:
2
dropout
:
0
num_classes
:
10
# loss function config for traing/eval process
Loss
:
Train
:
-
CELoss
:
weight
:
1.0
reduction
:
"
mean"
Eval
:
-
CELoss
:
weight
:
1.0
UnLabelLoss
:
Train
:
-
CELoss
:
weight
:
1.0
reduction
:
"
none"
Optimizer
:
name
:
Momentum
momentum
:
0.9
use_nesterov
:
True
no_weight_decay_name
:
bn bias
weight_decay
:
0.0005
lr
:
name
:
CosineFixmatch
learning_rate
:
0.03
num_warmup_steps
:
0
num_cycles
:
0.4375
# data loader for train and eval
DataLoader
:
Train
:
dataset
:
name
:
Cifar10
data_file
:
None
mode
:
'
train'
download
:
True
backend
:
'
pil'
sample_per_label
:
25
expand_labels
:
263
transform_ops
:
-
RandFlipImage
:
flip_code
:
1
-
Pad_paddle_vision
:
padding
:
4
padding_mode
:
reflect
-
RandCropImageV2
:
size
:
[
32
,
32
]
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.4914
,
0.4822
,
0.4465
]
std
:
[
0.2471
,
0.2435
,
0.2616
]
order
:
hwc
sampler
:
name
:
DistributedBatchSampler
batch_size
:
64
drop_last
:
True
shuffle
:
True
loader
:
num_workers
:
8
use_shared_memory
:
True
UnLabelTrain
:
dataset
:
name
:
Cifar10
data_file
:
None
mode
:
'
train'
download
:
True
backend
:
'
pil'
sample_per_label
:
None
transform_ops_weak
:
-
RandFlipImage
:
flip_code
:
1
-
Pad_paddle_vision
:
padding
:
4
padding_mode
:
reflect
-
RandCropImageV2
:
size
:
[
32
,
32
]
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.4914
,
0.4822
,
0.4465
]
std
:
[
0.2471
,
0.2435
,
0.2616
]
order
:
hwc
transform_ops_strong
:
-
RandFlipImage
:
flip_code
:
1
-
Pad_paddle_vision
:
padding
:
4
padding_mode
:
reflect
-
RandCropImageV2
:
size
:
[
32
,
32
]
-
RandAugment
:
num_layers
:
2
magnitude
:
10
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.4914
,
0.4822
,
0.4465
]
std
:
[
0.2471
,
0.2435
,
0.2616
]
order
:
hwc
sampler
:
name
:
DistributedBatchSampler
batch_size
:
448
drop_last
:
True
shuffle
:
True
loader
:
num_workers
:
8
use_shared_memory
:
True
Eval
:
dataset
:
name
:
Cifar10
data_file
:
None
mode
:
'
test'
download
:
True
backend
:
'
pil'
sample_per_label
:
None
transform_ops
:
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.4914
,
0.4822
,
0.4465
]
std
:
[
0.2471
,
0.2435
,
0.2616
]
order
:
hwc
sampler
:
name
:
DistributedBatchSampler
batch_size
:
64
drop_last
:
False
shuffle
:
True
loader
:
num_workers
:
4
use_shared_memory
:
True
Metric
:
Eval
:
-
TopkAcc
:
topk
:
[
1
,
5
]
\ No newline at end of file
ppcls/configs/ssl/FixMatch/FixMatch_cifar10_40.yaml
0 → 100644
浏览文件 @
944763d7
# global configs
Global
:
checkpoints
:
null
pretrained_model
:
'
https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/others/torch2paddle_weight/torch2paddle_initialize_cifar10_WideResNet_depth28_widenfactor2_classnum10.pdparams'
output_dir
:
./output
device
:
gpu
save_interval
:
-1
eval_during_train
:
True
eval_interval
:
1
epochs
:
1024
iter_per_epoch
:
1024
print_batch_step
:
20
use_visualdl
:
False
use_dali
:
False
train_mode
:
fixmatch
# used for static mode and model export
image_shape
:
[
3
,
224
,
224
]
save_inference_dir
:
./inference
SSL
:
tempture
:
1
threshold
:
0.95
EMA
:
decay
:
0.999
# AMP:
# scale_loss: 65536
# use_dynamic_loss_scaling: True
# # O1: mixed fp16
# level: O1
# model architecture
Arch
:
name
:
WideResNet
depth
:
28
widen_factor
:
2
dropout
:
0
num_classes
:
10
# loss function config for traing/eval process
Loss
:
Train
:
-
CELoss
:
weight
:
1.0
reduction
:
"
mean"
Eval
:
-
CELoss
:
weight
:
1.0
UnLabelLoss
:
Train
:
-
CELoss
:
weight
:
1.0
reduction
:
"
none"
Optimizer
:
name
:
Momentum
momentum
:
0.9
use_nesterov
:
True
no_weight_decay_name
:
bn bias
weight_decay
:
0.0005
lr
:
name
:
CosineFixmatch
learning_rate
:
0.03
num_warmup_steps
:
0
num_cycles
:
0.4375
# data loader for train and eval
DataLoader
:
Train
:
dataset
:
name
:
Cifar10
data_file
:
None
mode
:
'
train'
download
:
True
backend
:
'
pil'
sample_per_label
:
4
expand_labels
:
1639
transform_ops
:
-
RandFlipImage
:
flip_code
:
1
-
Pad_paddle_vision
:
padding
:
4
padding_mode
:
reflect
-
RandCropImageV2
:
size
:
[
32
,
32
]
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.4914
,
0.4822
,
0.4465
]
std
:
[
0.2471
,
0.2435
,
0.2616
]
order
:
hwc
sampler
:
name
:
DistributedBatchSampler
batch_size
:
64
drop_last
:
True
shuffle
:
True
loader
:
num_workers
:
8
use_shared_memory
:
True
UnLabelTrain
:
dataset
:
name
:
Cifar10
data_file
:
None
mode
:
'
train'
download
:
True
backend
:
'
pil'
sample_per_label
:
None
transform_ops_weak
:
-
RandFlipImage
:
flip_code
:
1
-
Pad_paddle_vision
:
padding
:
4
padding_mode
:
reflect
-
RandCropImageV2
:
size
:
[
32
,
32
]
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.4914
,
0.4822
,
0.4465
]
std
:
[
0.2471
,
0.2435
,
0.2616
]
order
:
hwc
transform_ops_strong
:
-
RandFlipImage
:
flip_code
:
1
-
Pad_paddle_vision
:
padding
:
4
padding_mode
:
reflect
-
RandCropImageV2
:
size
:
[
32
,
32
]
-
RandAugment
:
num_layers
:
2
magnitude
:
10
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.4914
,
0.4822
,
0.4465
]
std
:
[
0.2471
,
0.2435
,
0.2616
]
order
:
hwc
sampler
:
name
:
DistributedBatchSampler
batch_size
:
448
drop_last
:
True
shuffle
:
True
loader
:
num_workers
:
8
use_shared_memory
:
True
Eval
:
dataset
:
name
:
Cifar10
data_file
:
None
mode
:
'
test'
download
:
True
backend
:
'
pil'
sample_per_label
:
None
transform_ops
:
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.4914
,
0.4822
,
0.4465
]
std
:
[
0.2471
,
0.2435
,
0.2616
]
order
:
hwc
sampler
:
name
:
DistributedBatchSampler
batch_size
:
64
drop_last
:
False
shuffle
:
True
loader
:
num_workers
:
4
use_shared_memory
:
True
Metric
:
Eval
:
-
TopkAcc
:
topk
:
[
1
,
5
]
\ No newline at end of file
ppcls/configs/ssl/FixMatch/FixMatch_cifar10_4000.yaml
0 → 100644
浏览文件 @
944763d7
# global configs
Global
:
checkpoints
:
null
pretrained_model
:
'
https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/others/torch2paddle_weight/torch2paddle_initialize_cifar10_WideResNet_depth28_widenfactor2_classnum10.pdparams'
output_dir
:
./output
device
:
gpu
save_interval
:
-1
eval_during_train
:
True
eval_interval
:
1
epochs
:
1024
iter_per_epoch
:
1024
print_batch_step
:
20
use_visualdl
:
False
use_dali
:
False
train_mode
:
fixmatch
# used for static mode and model export
image_shape
:
[
3
,
224
,
224
]
save_inference_dir
:
./inference
SSL
:
tempture
:
1
threshold
:
0.95
EMA
:
decay
:
0.999
# AMP:
# scale_loss: 65536
# use_dynamic_loss_scaling: True
# # O1: mixed fp16
# level: O1
# model architecture
Arch
:
name
:
WideResNet
depth
:
28
widen_factor
:
2
dropout
:
0
num_classes
:
10
# loss function config for traing/eval process
Loss
:
Train
:
-
CELoss
:
weight
:
1.0
reduction
:
"
mean"
Eval
:
-
CELoss
:
weight
:
1.0
UnLabelLoss
:
Train
:
-
CELoss
:
weight
:
1.0
reduction
:
"
none"
Optimizer
:
name
:
Momentum
momentum
:
0.9
use_nesterov
:
True
no_weight_decay_name
:
bn bias
weight_decay
:
0.0005
lr
:
name
:
CosineFixmatch
learning_rate
:
0.03
num_warmup_steps
:
0
num_cycles
:
0.4375
# data loader for train and eval
DataLoader
:
Train
:
dataset
:
name
:
Cifar10
data_file
:
None
mode
:
'
train'
download
:
True
backend
:
'
pil'
sample_per_label
:
400
expand_labels
:
17
transform_ops
:
-
RandFlipImage
:
flip_code
:
1
-
Pad_paddle_vision
:
padding
:
4
padding_mode
:
reflect
-
RandCropImageV2
:
size
:
[
32
,
32
]
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.4914
,
0.4822
,
0.4465
]
std
:
[
0.2471
,
0.2435
,
0.2616
]
order
:
hwc
sampler
:
name
:
DistributedBatchSampler
batch_size
:
64
drop_last
:
True
shuffle
:
True
loader
:
num_workers
:
4
use_shared_memory
:
True
UnLabelTrain
:
dataset
:
name
:
Cifar10
data_file
:
None
mode
:
'
train'
download
:
True
backend
:
'
pil'
sample_per_label
:
None
transform_ops_weak
:
-
RandFlipImage
:
flip_code
:
1
-
Pad_paddle_vision
:
padding
:
4
padding_mode
:
reflect
-
RandCropImageV2
:
size
:
[
32
,
32
]
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.4914
,
0.4822
,
0.4465
]
std
:
[
0.2471
,
0.2435
,
0.2616
]
order
:
hwc
transform_ops_strong
:
-
RandFlipImage
:
flip_code
:
1
-
Pad_paddle_vision
:
padding
:
4
padding_mode
:
reflect
-
RandCropImageV2
:
size
:
[
32
,
32
]
-
RandAugment
:
num_layers
:
2
magnitude
:
10
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.4914
,
0.4822
,
0.4465
]
std
:
[
0.2471
,
0.2435
,
0.2616
]
order
:
hwc
sampler
:
name
:
DistributedBatchSampler
batch_size
:
448
drop_last
:
True
shuffle
:
True
loader
:
num_workers
:
4
use_shared_memory
:
True
Eval
:
dataset
:
name
:
Cifar10
data_file
:
None
mode
:
'
test'
download
:
True
backend
:
'
pil'
sample_per_label
:
None
transform_ops
:
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.4914
,
0.4822
,
0.4465
]
std
:
[
0.2471
,
0.2435
,
0.2616
]
order
:
hwc
sampler
:
name
:
DistributedBatchSampler
batch_size
:
64
drop_last
:
False
shuffle
:
True
loader
:
num_workers
:
4
use_shared_memory
:
True
Metric
:
Eval
:
-
TopkAcc
:
topk
:
[
1
,
5
]
\ No newline at end of file
ppcls/data/__init__.py
浏览文件 @
944763d7
...
@@ -32,6 +32,7 @@ from ppcls.data.dataloader.multi_scale_dataset import MultiScaleDataset
...
@@ -32,6 +32,7 @@ from ppcls.data.dataloader.multi_scale_dataset import MultiScaleDataset
from
ppcls.data.dataloader.person_dataset
import
Market1501
,
MSMT17
from
ppcls.data.dataloader.person_dataset
import
Market1501
,
MSMT17
from
ppcls.data.dataloader.face_dataset
import
FiveValidationDataset
,
AdaFaceDataset
from
ppcls.data.dataloader.face_dataset
import
FiveValidationDataset
,
AdaFaceDataset
from
ppcls.data.dataloader.custom_label_dataset
import
CustomLabelDataset
from
ppcls.data.dataloader.custom_label_dataset
import
CustomLabelDataset
from
ppcls.data.dataloader.cifar
import
Cifar10
,
Cifar100
# sampler
# sampler
from
ppcls.data.dataloader.DistributedRandomIdentitySampler
import
DistributedRandomIdentitySampler
from
ppcls.data.dataloader.DistributedRandomIdentitySampler
import
DistributedRandomIdentitySampler
...
@@ -67,8 +68,9 @@ def create_operators(params, class_num=None):
...
@@ -67,8 +68,9 @@ def create_operators(params, class_num=None):
def
build_dataloader
(
config
,
mode
,
device
,
use_dali
=
False
,
seed
=
None
):
def
build_dataloader
(
config
,
mode
,
device
,
use_dali
=
False
,
seed
=
None
):
assert
mode
in
[
assert
mode
in
[
'Train'
,
'Eval'
,
'Test'
,
'Gallery'
,
'Query'
'Train'
,
'Eval'
,
'Test'
,
'Gallery'
,
'Query'
,
'UnLabelTrain'
],
"Dataset mode should be Train, Eval, Test, Gallery, Query"
],
"Dataset mode should be Train, Eval, Test, Gallery, Query, UnLabelTrain"
assert
mode
in
config
.
keys
(),
"{} config not in yaml"
.
format
(
mode
)
# build dataset
# build dataset
if
use_dali
:
if
use_dali
:
from
ppcls.data.dataloader.dali
import
dali_dataloader
from
ppcls.data.dataloader.dali
import
dali_dataloader
...
...
ppcls/data/dataloader/__init__.py
浏览文件 @
944763d7
...
@@ -12,3 +12,4 @@ from ppcls.data.dataloader.pk_sampler import PKSampler
...
@@ -12,3 +12,4 @@ from ppcls.data.dataloader.pk_sampler import PKSampler
from
ppcls.data.dataloader.person_dataset
import
Market1501
,
MSMT17
from
ppcls.data.dataloader.person_dataset
import
Market1501
,
MSMT17
from
ppcls.data.dataloader.face_dataset
import
AdaFaceDataset
,
FiveValidationDataset
from
ppcls.data.dataloader.face_dataset
import
AdaFaceDataset
,
FiveValidationDataset
from
ppcls.data.dataloader.custom_label_dataset
import
CustomLabelDataset
from
ppcls.data.dataloader.custom_label_dataset
import
CustomLabelDataset
from
ppcls.data.dataloader.cifar
import
Cifar10
,
Cifar100
ppcls/data/dataloader/cifar.py
0 → 100644
浏览文件 @
944763d7
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from
__future__
import
print_function
import
numpy
as
np
import
cv2
from
ppcls.data
import
preprocess
from
ppcls.data.preprocess
import
transform
from
ppcls.data.dataloader.common_dataset
import
create_operators
from
paddle.vision.datasets
import
Cifar10
as
Cifar10_paddle
from
paddle.vision.datasets
import
Cifar100
as
Cifar100_paddle
class
Cifar10
(
Cifar10_paddle
):
def
__init__
(
self
,
data_file
=
None
,
mode
=
'train'
,
download
=
True
,
backend
=
'cv2'
,
sample_per_label
=
None
,
expand_labels
=
1
,
transform_ops
=
None
,
transform_ops_weak
=
None
,
transform_ops_strong
=
None
):
super
().
__init__
(
data_file
,
mode
,
None
,
download
,
backend
)
assert
isinstance
(
expand_labels
,
int
)
self
.
_transform_ops
=
create_operators
(
transform_ops
)
self
.
_transform_ops_weak
=
create_operators
(
transform_ops_weak
)
self
.
_transform_ops_strong
=
create_operators
(
transform_ops_strong
)
self
.
class_num
=
10
labels
=
[]
for
x
in
self
.
data
:
labels
.
append
(
x
[
1
])
labels
=
np
.
array
(
labels
)
if
isinstance
(
sample_per_label
,
int
):
index
=
[]
for
i
in
range
(
self
.
class_num
):
idx
=
np
.
where
(
labels
==
i
)[
0
]
idx
=
np
.
random
.
choice
(
idx
,
sample_per_label
,
False
)
index
.
extend
(
idx
)
index
=
index
*
expand_labels
data
=
[
self
.
data
[
x
]
for
x
in
index
]
self
.
data
=
data
def
__getitem__
(
self
,
idx
):
(
image
,
label
)
=
super
().
__getitem__
(
idx
)
if
self
.
_transform_ops
:
image1
=
transform
(
image
,
self
.
_transform_ops
)
image1
=
image1
.
transpose
((
2
,
0
,
1
))
return
(
image1
,
np
.
int64
(
label
))
elif
self
.
_transform_ops_weak
and
self
.
_transform_ops_strong
:
image2
=
transform
(
image
,
self
.
_transform_ops_weak
)
image2
=
image2
.
transpose
((
2
,
0
,
1
))
image3
=
transform
(
image
,
self
.
_transform_ops_strong
)
image3
=
image3
.
transpose
((
2
,
0
,
1
))
return
(
image2
,
image3
,
np
.
int64
(
label
))
class
Cifar100
(
Cifar100_paddle
):
def
__init__
(
self
,
data_file
=
None
,
mode
=
'train'
,
download
=
True
,
backend
=
'pil'
,
sample_per_label
=
None
,
expand_labels
=
1
,
transform_ops
=
None
,
transform_ops_weak
=
None
,
transform_ops_strong
=
None
):
super
().
__init__
(
data_file
,
mode
,
None
,
download
,
backend
)
assert
isinstance
(
expand_labels
,
int
)
self
.
_transform_ops
=
create_operators
(
transform_ops
)
self
.
_transform_ops_weak
=
create_operators
(
transform_ops_weak
)
self
.
_transform_ops_strong
=
create_operators
(
transform_ops_strong
)
self
.
class_num
=
100
labels
=
[]
for
x
in
self
.
data
:
labels
.
append
(
x
[
1
])
labels
=
np
.
array
(
labels
)
if
isinstance
(
sample_per_label
,
int
):
index
=
[]
for
i
in
range
(
self
.
class_num
):
idx
=
np
.
where
(
labels
==
i
)[
0
]
idx
=
np
.
random
.
choice
(
idx
,
sample_per_label
,
False
)
index
.
extend
(
idx
)
index
=
index
*
expand_labels
data
=
[
self
.
data
[
x
]
for
x
in
index
]
self
.
data
=
data
def
__getitem__
(
self
,
idx
):
(
image
,
label
)
=
super
().
__getitem__
(
idx
)
if
self
.
_transform_ops
:
image1
=
transform
(
image
,
self
.
_transform_ops
)
image1
=
image1
.
transpose
((
2
,
0
,
1
))
return
(
image1
,
np
.
int64
(
label
))
elif
self
.
_transform_ops_weak
and
self
.
_transform_ops_strong
:
image2
=
transform
(
image
,
self
.
_transform_ops_weak
)
image2
=
image2
.
transpose
((
2
,
0
,
1
))
image3
=
transform
(
image
,
self
.
_transform_ops_strong
)
image3
=
image3
.
transpose
((
2
,
0
,
1
))
return
(
image2
,
image3
,
np
.
int64
(
label
))
\ No newline at end of file
ppcls/data/dataloader/common_dataset.py
浏览文件 @
944763d7
...
@@ -30,6 +30,8 @@ def create_operators(params):
...
@@ -30,6 +30,8 @@ def create_operators(params):
Args:
Args:
params(list): a dict list, used to create some operators
params(list): a dict list, used to create some operators
"""
"""
if
params
is
None
:
return
None
assert
isinstance
(
params
,
list
),
(
'operator config should be a list'
)
assert
isinstance
(
params
,
list
),
(
'operator config should be a list'
)
ops
=
[]
ops
=
[]
for
operator
in
params
:
for
operator
in
params
:
...
...
ppcls/data/preprocess/__init__.py
浏览文件 @
944763d7
...
@@ -44,6 +44,7 @@ from ppcls.data.preprocess.ops.operators import RandomRotation
...
@@ -44,6 +44,7 @@ from ppcls.data.preprocess.ops.operators import RandomRotation
from
ppcls.data.preprocess.ops.operators
import
Padv2
from
ppcls.data.preprocess.ops.operators
import
Padv2
from
ppcls.data.preprocess.ops.operators
import
RandomRot90
from
ppcls.data.preprocess.ops.operators
import
RandomRot90
from
.ops.operators
import
format_data
from
.ops.operators
import
format_data
from
paddle.vision.transforms
import
Pad
as
Pad_paddle_vision
from
ppcls.data.preprocess.batch_ops.batch_operators
import
MixupOperator
,
CutmixOperator
,
OpSampler
,
FmixOperator
from
ppcls.data.preprocess.batch_ops.batch_operators
import
MixupOperator
,
CutmixOperator
,
OpSampler
,
FmixOperator
from
ppcls.data.preprocess.batch_ops.batch_operators
import
MixupCutmixHybrid
from
ppcls.data.preprocess.batch_ops.batch_operators
import
MixupCutmixHybrid
...
...
ppcls/engine/engine.py
浏览文件 @
944763d7
...
@@ -41,7 +41,7 @@ from ppcls.utils import save_load
...
@@ -41,7 +41,7 @@ from ppcls.utils import save_load
from
ppcls.data.utils.get_image_list
import
get_image_list
from
ppcls.data.utils.get_image_list
import
get_image_list
from
ppcls.data.postprocess
import
build_postprocess
from
ppcls.data.postprocess
import
build_postprocess
from
ppcls.data
import
create_operators
from
ppcls.data
import
create_operators
from
ppcls.engine
.train
import
train_epoch
from
ppcls.engine
import
train
as
train_method
from
ppcls.engine.train.utils
import
type_name
from
ppcls.engine.train.utils
import
type_name
from
ppcls.engine
import
evaluation
from
ppcls.engine
import
evaluation
from
ppcls.arch.gears.identity_head
import
IdentityHead
from
ppcls.arch.gears.identity_head
import
IdentityHead
...
@@ -54,6 +54,7 @@ class Engine(object):
...
@@ -54,6 +54,7 @@ class Engine(object):
self
.
config
=
config
self
.
config
=
config
self
.
eval_mode
=
self
.
config
[
"Global"
].
get
(
"eval_mode"
,
self
.
eval_mode
=
self
.
config
[
"Global"
].
get
(
"eval_mode"
,
"classification"
)
"classification"
)
self
.
train_mode
=
self
.
config
[
"Global"
].
get
(
"train_mode"
,
None
)
if
"Head"
in
self
.
config
[
"Arch"
]
or
self
.
config
[
"Arch"
].
get
(
"is_rec"
,
if
"Head"
in
self
.
config
[
"Arch"
]
or
self
.
config
[
"Arch"
].
get
(
"is_rec"
,
False
):
False
):
self
.
is_rec
=
True
self
.
is_rec
=
True
...
@@ -79,7 +80,11 @@ class Engine(object):
...
@@ -79,7 +80,11 @@ class Engine(object):
assert
self
.
eval_mode
in
[
assert
self
.
eval_mode
in
[
"classification"
,
"retrieval"
,
"adaface"
"classification"
,
"retrieval"
,
"adaface"
],
logger
.
error
(
"Invalid eval mode: {}"
.
format
(
self
.
eval_mode
))
],
logger
.
error
(
"Invalid eval mode: {}"
.
format
(
self
.
eval_mode
))
self
.
train_epoch_func
=
train_epoch
if
self
.
train_mode
is
None
:
self
.
train_epoch_func
=
train_method
.
train_epoch
else
:
self
.
train_epoch_func
=
getattr
(
train_method
,
"train_epoch_"
+
self
.
train_mode
)
self
.
eval_func
=
getattr
(
evaluation
,
self
.
eval_mode
+
"_eval"
)
self
.
eval_func
=
getattr
(
evaluation
,
self
.
eval_mode
+
"_eval"
)
self
.
use_dali
=
self
.
config
[
'Global'
].
get
(
"use_dali"
,
False
)
self
.
use_dali
=
self
.
config
[
'Global'
].
get
(
"use_dali"
,
False
)
...
@@ -119,6 +124,20 @@ class Engine(object):
...
@@ -119,6 +124,20 @@ class Engine(object):
if
self
.
mode
==
'train'
:
if
self
.
mode
==
'train'
:
self
.
train_dataloader
=
build_dataloader
(
self
.
train_dataloader
=
build_dataloader
(
self
.
config
[
"DataLoader"
],
"Train"
,
self
.
device
,
self
.
use_dali
)
self
.
config
[
"DataLoader"
],
"Train"
,
self
.
device
,
self
.
use_dali
)
if
self
.
config
[
"DataLoader"
].
get
(
'UnLabelTrain'
,
None
)
is
not
None
:
self
.
unlabel_train_dataloader
=
build_dataloader
(
self
.
config
[
"DataLoader"
],
"UnLabelTrain"
,
self
.
device
,
self
.
use_dali
)
else
:
self
.
unlabel_train_dataloader
=
None
self
.
iter_per_epoch
=
len
(
self
.
train_dataloader
)
-
1
if
platform
.
system
(
)
==
"Windows"
else
len
(
self
.
train_dataloader
)
if
self
.
config
[
"Global"
].
get
(
"iter_per_epoch"
,
None
):
# set max iteration per epoch mannualy, when training by iteration(s), such as XBM, FixMatch.
self
.
iter_per_epoch
=
self
.
config
[
"Global"
].
get
(
"iter_per_epoch"
)
self
.
iter_per_epoch
=
self
.
iter_per_epoch
//
self
.
update_freq
*
self
.
update_freq
if
self
.
mode
==
"eval"
or
(
self
.
mode
==
"train"
and
if
self
.
mode
==
"eval"
or
(
self
.
mode
==
"train"
and
self
.
config
[
"Global"
][
"eval_during_train"
]):
self
.
config
[
"Global"
][
"eval_during_train"
]):
if
self
.
eval_mode
in
[
"classification"
,
"adaface"
]:
if
self
.
eval_mode
in
[
"classification"
,
"adaface"
]:
...
@@ -142,8 +161,11 @@ class Engine(object):
...
@@ -142,8 +161,11 @@ class Engine(object):
# build loss
# build loss
if
self
.
mode
==
"train"
:
if
self
.
mode
==
"train"
:
loss_info
=
self
.
config
[
"Loss"
][
"Train"
]
label_loss_info
=
self
.
config
[
"Loss"
][
"Train"
]
self
.
train_loss_func
=
build_loss
(
loss_info
)
self
.
train_loss_func
=
build_loss
(
label_loss_info
)
unlabel_loss_info
=
self
.
config
.
get
(
"UnLabelLoss"
,
{}).
get
(
"Train"
,
None
)
self
.
unlabel_train_loss_func
=
build_loss
(
unlabel_loss_info
)
if
self
.
mode
==
"eval"
or
(
self
.
mode
==
"train"
and
if
self
.
mode
==
"eval"
or
(
self
.
mode
==
"train"
and
self
.
config
[
"Global"
][
"eval_during_train"
]):
self
.
config
[
"Global"
][
"eval_during_train"
]):
loss_config
=
self
.
config
.
get
(
"Loss"
,
None
)
loss_config
=
self
.
config
.
get
(
"Loss"
,
None
)
...
@@ -208,7 +230,7 @@ class Engine(object):
...
@@ -208,7 +230,7 @@ class Engine(object):
if
self
.
mode
==
'train'
:
if
self
.
mode
==
'train'
:
self
.
optimizer
,
self
.
lr_sch
=
build_optimizer
(
self
.
optimizer
,
self
.
lr_sch
=
build_optimizer
(
self
.
config
[
"Optimizer"
],
self
.
config
[
"Global"
][
"epochs"
],
self
.
config
[
"Optimizer"
],
self
.
config
[
"Global"
][
"epochs"
],
len
(
self
.
train_dataloader
)
//
self
.
update_freq
,
self
.
iter_per_epoch
//
self
.
update_freq
,
[
self
.
model
,
self
.
train_loss_func
])
[
self
.
model
,
self
.
train_loss_func
])
# AMP training and evaluating
# AMP training and evaluating
...
@@ -345,14 +367,6 @@ class Engine(object):
...
@@ -345,14 +367,6 @@ class Engine(object):
if
metric_info
is
not
None
:
if
metric_info
is
not
None
:
best_metric
.
update
(
metric_info
)
best_metric
.
update
(
metric_info
)
self
.
max_iter
=
len
(
self
.
train_dataloader
)
-
1
if
platform
.
system
(
)
==
"Windows"
else
len
(
self
.
train_dataloader
)
if
self
.
config
[
"Global"
].
get
(
"iter_per_epoch"
,
None
):
# set max iteration per epoch mannualy, when training by iteration(s), such as XBM, FixMatch.
self
.
max_iter
=
self
.
config
[
"Global"
].
get
(
"iter_per_epoch"
)
self
.
max_iter
=
self
.
max_iter
//
self
.
update_freq
*
self
.
update_freq
for
epoch_id
in
range
(
best_metric
[
"epoch"
]
+
1
,
for
epoch_id
in
range
(
best_metric
[
"epoch"
]
+
1
,
self
.
config
[
"Global"
][
"epochs"
]
+
1
):
self
.
config
[
"Global"
][
"epochs"
]
+
1
):
acc
=
0.0
acc
=
0.0
...
@@ -431,7 +445,7 @@ class Engine(object):
...
@@ -431,7 +445,7 @@ class Engine(object):
writer
=
self
.
vdl_writer
)
writer
=
self
.
vdl_writer
)
# save model
# save model
if
epoch_id
%
save_interval
==
0
:
if
save_interval
>
0
and
epoch_id
%
save_interval
==
0
:
save_load
.
save_model
(
save_load
.
save_model
(
self
.
model
,
self
.
model
,
self
.
optimizer
,
{
"metric"
:
acc
,
self
.
optimizer
,
{
"metric"
:
acc
,
...
...
ppcls/engine/train/__init__.py
浏览文件 @
944763d7
...
@@ -12,3 +12,4 @@
...
@@ -12,3 +12,4 @@
# See the License for the specific language governing permissions and
# See the License for the specific language governing permissions and
# limitations under the License.
# limitations under the License.
from
ppcls.engine.train.train
import
train_epoch
from
ppcls.engine.train.train
import
train_epoch
from
ppcls.engine.train.train_fixmatch
import
train_epoch_fixmatch
\ No newline at end of file
ppcls/engine/train/train.py
浏览文件 @
944763d7
...
@@ -25,7 +25,7 @@ def train_epoch(engine, epoch_id, print_batch_step):
...
@@ -25,7 +25,7 @@ def train_epoch(engine, epoch_id, print_batch_step):
if
not
hasattr
(
engine
,
"train_dataloader_iter"
):
if
not
hasattr
(
engine
,
"train_dataloader_iter"
):
engine
.
train_dataloader_iter
=
iter
(
engine
.
train_dataloader
)
engine
.
train_dataloader_iter
=
iter
(
engine
.
train_dataloader
)
for
iter_id
in
range
(
engine
.
max_iter
):
for
iter_id
in
range
(
engine
.
iter_per_epoch
):
# fetch data batch from dataloader
# fetch data batch from dataloader
try
:
try
:
batch
=
engine
.
train_dataloader_iter
.
next
()
batch
=
engine
.
train_dataloader_iter
.
next
()
...
...
ppcls/engine/train/train_fixmatch.py
0 → 100644
浏览文件 @
944763d7
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from
__future__
import
absolute_import
,
division
,
print_function
import
time
import
paddle
from
ppcls.engine.train.utils
import
update_loss
,
update_metric
,
log_info
from
ppcls.utils
import
profiler
from
paddle.nn
import
functional
as
F
import
numpy
as
np
def
train_epoch_fixmatch
(
engine
,
epoch_id
,
print_batch_step
):
tic
=
time
.
time
()
if
not
hasattr
(
engine
,
"train_dataloader_iter"
):
engine
.
train_dataloader_iter
=
iter
(
engine
.
train_dataloader
)
engine
.
unlabel_train_dataloader_iter
=
iter
(
engine
.
unlabel_train_dataloader
)
temperture
=
engine
.
config
[
"SSL"
].
get
(
"temperture"
,
1
)
threshold
=
engine
.
config
[
"SSL"
].
get
(
"threshold"
,
0.95
)
assert
engine
.
iter_per_epoch
is
not
None
,
"Global.iter_per_epoch need to be set."
threshold
=
paddle
.
to_tensor
(
threshold
)
for
iter_id
in
range
(
engine
.
iter_per_epoch
):
if
iter_id
>=
engine
.
iter_per_epoch
:
break
if
iter_id
==
5
:
for
key
in
engine
.
time_info
:
engine
.
time_info
[
key
].
reset
()
try
:
label_data_batch
=
engine
.
train_dataloader_iter
.
next
()
except
Exception
:
engine
.
train_dataloader_iter
=
iter
(
engine
.
train_dataloader
)
label_data_batch
=
engine
.
train_dataloader_iter
.
next
()
try
:
unlabel_data_batch
=
engine
.
unlabel_train_dataloader_iter
.
next
()
except
Exception
:
engine
.
unlabel_train_dataloader_iter
=
iter
(
engine
.
unlabel_train_dataloader
)
unlabel_data_batch
=
engine
.
unlabel_train_dataloader_iter
.
next
()
assert
len
(
unlabel_data_batch
)
==
3
assert
unlabel_data_batch
[
0
].
shape
==
unlabel_data_batch
[
1
].
shape
engine
.
time_info
[
"reader_cost"
].
update
(
time
.
time
()
-
tic
)
batch_size
=
label_data_batch
[
0
].
shape
[
0
]
+
unlabel_data_batch
[
0
].
shape
[
0
]
\
+
unlabel_data_batch
[
1
].
shape
[
0
]
engine
.
global_step
+=
1
# make inputs
inputs_x
,
targets_x
=
label_data_batch
inputs_u_w
,
inputs_u_s
,
targets_u
=
unlabel_data_batch
batch_size_label
=
inputs_x
.
shape
[
0
]
inputs
=
paddle
.
concat
([
inputs_x
,
inputs_u_w
,
inputs_u_s
],
axis
=
0
)
# image input
if
engine
.
amp
:
amp_level
=
engine
.
config
[
'AMP'
].
get
(
"level"
,
"O1"
).
upper
()
with
paddle
.
amp
.
auto_cast
(
custom_black_list
=
{
"flatten_contiguous_range"
,
"greater_than"
},
level
=
amp_level
):
loss_dict
,
logits_label
=
get_loss
(
engine
,
inputs
,
batch_size_label
,
temperture
,
threshold
,
targets_x
)
else
:
loss_dict
,
logits_label
=
get_loss
(
engine
,
inputs
,
batch_size_label
,
temperture
,
threshold
,
targets_x
)
# loss
loss
=
loss_dict
[
"loss"
]
# backward & step opt
if
engine
.
amp
:
scaled
=
engine
.
scaler
.
scale
(
loss
)
scaled
.
backward
()
for
i
in
range
(
len
(
engine
.
optimizer
)):
engine
.
scaler
.
minimize
(
engine
.
optimizer
[
i
],
scaled
)
else
:
loss
.
backward
()
for
i
in
range
(
len
(
engine
.
optimizer
)):
engine
.
optimizer
[
i
].
step
()
# step lr(by step)
for
i
in
range
(
len
(
engine
.
lr_sch
)):
if
not
getattr
(
engine
.
lr_sch
[
i
],
"by_epoch"
,
False
):
engine
.
lr_sch
[
i
].
step
()
# clear grad
for
i
in
range
(
len
(
engine
.
optimizer
)):
engine
.
optimizer
[
i
].
clear_grad
()
# update ema
if
engine
.
ema
:
engine
.
model_ema
.
update
(
engine
.
model
)
# below code just for logging
# update metric_for_logger
update_metric
(
engine
,
logits_label
,
label_data_batch
,
batch_size
)
# update_loss_for_logger
update_loss
(
engine
,
loss_dict
,
batch_size
)
engine
.
time_info
[
"batch_cost"
].
update
(
time
.
time
()
-
tic
)
if
iter_id
%
print_batch_step
==
0
:
log_info
(
engine
,
batch_size
,
epoch_id
,
iter_id
)
tic
=
time
.
time
()
# step lr(by epoch)
for
i
in
range
(
len
(
engine
.
lr_sch
)):
if
getattr
(
engine
.
lr_sch
[
i
],
"by_epoch"
,
False
):
engine
.
lr_sch
[
i
].
step
()
def
get_loss
(
engine
,
inputs
,
batch_size_label
,
temperture
,
threshold
,
targets_x
):
# For pytroch version, inputs need to use interleave and de_interleave
# to reshape and transpose inputs and logits, but it dosen't affect the
# result. So this paddle version dose not use the two transpose func.
# inputs = interleave(inputs, inputs.shape[0] // batch_size_label)
logits
=
engine
.
model
(
inputs
)
# logits = de_interleave(logits, inputs.shape[0] // batch_size_label)
logits_x
=
logits
[:
batch_size_label
]
logits_u_w
,
logits_u_s
=
logits
[
batch_size_label
:].
chunk
(
2
)
loss_dict_label
=
engine
.
train_loss_func
(
logits_x
,
targets_x
)
probs_u_w
=
F
.
softmax
(
logits_u_w
.
detach
()
/
temperture
,
axis
=-
1
)
p_targets_u
,
mask
=
get_psuedo_label_and_mask
(
probs_u_w
,
threshold
)
unlabel_celoss
=
engine
.
unlabel_train_loss_func
(
logits_u_s
,
p_targets_u
)[
"CELoss"
]
unlabel_celoss
=
(
unlabel_celoss
*
mask
).
mean
()
loss_dict
=
dict
()
for
k
,
v
in
loss_dict_label
.
items
():
if
k
!=
"loss"
:
loss_dict
[
k
+
"_label"
]
=
v
loss_dict
[
"CELoss_unlabel"
]
=
unlabel_celoss
loss_dict
[
"loss"
]
=
loss_dict_label
[
'loss'
]
+
unlabel_celoss
return
loss_dict
,
logits_x
def
get_psuedo_label_and_mask
(
probs_u_w
,
threshold
):
max_probs
=
paddle
.
max
(
probs_u_w
,
axis
=-
1
)
p_targets_u
=
paddle
.
argmax
(
probs_u_w
,
axis
=-
1
)
mask
=
paddle
.
greater_equal
(
max_probs
,
threshold
).
astype
(
'float'
)
return
p_targets_u
,
mask
def
interleave
(
x
,
size
):
s
=
list
(
x
.
shape
)
return
x
.
reshape
([
-
1
,
size
]
+
s
[
1
:]).
transpose
(
[
1
,
0
,
2
,
3
,
4
]).
reshape
([
-
1
]
+
s
[
1
:])
def
de_interleave
(
x
,
size
):
s
=
list
(
x
.
shape
)
return
x
.
reshape
([
size
,
-
1
]
+
s
[
1
:]).
transpose
(
[
1
,
0
,
2
]).
reshape
([
-
1
]
+
s
[
1
:])
ppcls/engine/train/utils.py
浏览文件 @
944763d7
...
@@ -53,13 +53,14 @@ def log_info(trainer, batch_size, epoch_id, iter_id):
...
@@ -53,13 +53,14 @@ def log_info(trainer, batch_size, epoch_id, iter_id):
ips_msg
=
"ips: {:.5f} samples/s"
.
format
(
ips_msg
=
"ips: {:.5f} samples/s"
.
format
(
batch_size
/
trainer
.
time_info
[
"batch_cost"
].
avg
)
batch_size
/
trainer
.
time_info
[
"batch_cost"
].
avg
)
eta_sec
=
(
(
trainer
.
config
[
"Global"
][
"epochs"
]
-
epoch_id
+
1
eta_sec
=
((
trainer
.
config
[
"Global"
][
"epochs"
]
-
epoch_id
+
1
)
*
)
*
trainer
.
max_iter
-
iter_id
)
*
trainer
.
time_info
[
"batch_cost"
].
avg
trainer
.
iter_per_epoch
-
iter_id
)
*
trainer
.
time_info
[
"batch_cost"
].
avg
eta_msg
=
"eta: {:s}"
.
format
(
str
(
datetime
.
timedelta
(
seconds
=
int
(
eta_sec
))))
eta_msg
=
"eta: {:s}"
.
format
(
str
(
datetime
.
timedelta
(
seconds
=
int
(
eta_sec
))))
logger
.
info
(
"[Train][Epoch {}/{}][Iter: {}/{}]{}, {}, {}, {}, {}"
.
format
(
logger
.
info
(
"[Train][Epoch {}/{}][Iter: {}/{}]{}, {}, {}, {}, {}"
.
format
(
epoch_id
,
trainer
.
config
[
"Global"
][
"epochs"
],
iter_id
,
epoch_id
,
trainer
.
config
[
"Global"
][
"epochs"
],
iter_id
,
trainer
.
iter_per_epoch
,
trainer
.
max_iter
,
lr_msg
,
metric_msg
,
time_msg
,
ips_msg
,
eta_msg
))
lr_msg
,
metric_msg
,
time_msg
,
ips_msg
,
eta_msg
))
for
i
,
lr
in
enumerate
(
trainer
.
lr_sch
):
for
i
,
lr
in
enumerate
(
trainer
.
lr_sch
):
logger
.
scaler
(
logger
.
scaler
(
...
...
ppcls/loss/__init__.py
浏览文件 @
944763d7
...
@@ -77,6 +77,8 @@ class CombinedLoss(nn.Layer):
...
@@ -77,6 +77,8 @@ class CombinedLoss(nn.Layer):
def
build_loss
(
config
):
def
build_loss
(
config
):
if
config
is
None
:
return
None
module_class
=
CombinedLoss
(
copy
.
deepcopy
(
config
))
module_class
=
CombinedLoss
(
copy
.
deepcopy
(
config
))
logger
.
debug
(
"build loss {} success."
.
format
(
module_class
))
logger
.
debug
(
"build loss {} success."
.
format
(
module_class
))
return
module_class
return
module_class
ppcls/loss/celoss.py
浏览文件 @
944763d7
...
@@ -26,11 +26,13 @@ class CELoss(nn.Layer):
...
@@ -26,11 +26,13 @@ class CELoss(nn.Layer):
Cross entropy loss
Cross entropy loss
"""
"""
def
__init__
(
self
,
epsilon
=
None
):
def
__init__
(
self
,
reduction
=
"mean"
,
epsilon
=
None
):
super
().
__init__
()
super
().
__init__
()
if
epsilon
is
not
None
and
(
epsilon
<=
0
or
epsilon
>=
1
):
if
epsilon
is
not
None
and
(
epsilon
<=
0
or
epsilon
>=
1
):
epsilon
=
None
epsilon
=
None
self
.
epsilon
=
epsilon
self
.
epsilon
=
epsilon
assert
reduction
in
[
"mean"
,
"sum"
,
"none"
]
self
.
reduction
=
reduction
def
_labelsmoothing
(
self
,
target
,
class_num
):
def
_labelsmoothing
(
self
,
target
,
class_num
):
if
len
(
target
.
shape
)
==
1
or
target
.
shape
[
-
1
]
!=
class_num
:
if
len
(
target
.
shape
)
==
1
or
target
.
shape
[
-
1
]
!=
class_num
:
...
@@ -55,8 +57,11 @@ class CELoss(nn.Layer):
...
@@ -55,8 +57,11 @@ class CELoss(nn.Layer):
soft_label
=
True
soft_label
=
True
else
:
else
:
soft_label
=
False
soft_label
=
False
loss
=
F
.
cross_entropy
(
x
,
label
=
label
,
soft_label
=
soft_label
)
loss
=
F
.
cross_entropy
(
loss
=
loss
.
mean
()
x
,
label
=
label
,
soft_label
=
soft_label
,
reduction
=
self
.
reduction
)
return
{
"CELoss"
:
loss
}
return
{
"CELoss"
:
loss
}
...
...
ppcls/optimizer/learning_rate.py
浏览文件 @
944763d7
...
@@ -14,10 +14,10 @@
...
@@ -14,10 +14,10 @@
from
__future__
import
(
absolute_import
,
division
,
print_function
,
from
__future__
import
(
absolute_import
,
division
,
print_function
,
unicode_literals
)
unicode_literals
)
import
math
import
types
import
types
from
abc
import
abstractmethod
from
abc
import
abstractmethod
from
typing
import
Union
from
typing
import
Union
from
paddle.optimizer
import
lr
from
paddle.optimizer
import
lr
from
ppcls.utils
import
logger
from
ppcls.utils
import
logger
...
@@ -421,7 +421,6 @@ class ReduceOnPlateau(LRBase):
...
@@ -421,7 +421,6 @@ class ReduceOnPlateau(LRBase):
last_epoch (int, optional): last epoch. Defaults to -1.
last_epoch (int, optional): last epoch. Defaults to -1.
by_epoch (bool, optional): learning rate decays by epoch when by_epoch is True, else by iter. Defaults to False.
by_epoch (bool, optional): learning rate decays by epoch when by_epoch is True, else by iter. Defaults to False.
"""
"""
def
__init__
(
self
,
def
__init__
(
self
,
epochs
,
epochs
,
step_each_epoch
,
step_each_epoch
,
...
@@ -475,3 +474,47 @@ class ReduceOnPlateau(LRBase):
...
@@ -475,3 +474,47 @@ class ReduceOnPlateau(LRBase):
setattr
(
learning_rate
,
"by_epoch"
,
self
.
by_epoch
)
setattr
(
learning_rate
,
"by_epoch"
,
self
.
by_epoch
)
return
learning_rate
return
learning_rate
class
CosineFixmatch
(
LRBase
):
"""Cosine decay in FixMatch style
Args:
epochs (int): total epoch(s)
step_each_epoch (int): number of iterations within an epoch
learning_rate (float): learning rate
num_warmup_steps (int): the number warmup steps.
warmunum_cycles (float, optional): the factor for cosine in FixMatch learning rate. Defaults to 7 / 16.
last_epoch (int, optional): last epoch. Defaults to -1.
by_epoch (bool, optional): learning rate decays by epoch when by_epoch is True, else by iter. Defaults to False.
"""
def
__init__
(
self
,
epochs
,
step_each_epoch
,
learning_rate
,
num_warmup_steps
,
num_cycles
=
7
/
16
,
last_epoch
=-
1
,
by_epoch
=
False
):
self
.
epochs
=
epochs
self
.
step_each_epoch
=
step_each_epoch
self
.
learning_rate
=
learning_rate
self
.
num_warmup_steps
=
num_warmup_steps
self
.
num_cycles
=
num_cycles
self
.
last_epoch
=
last_epoch
def
__call__
(
self
):
def
_lr_lambda
(
current_step
):
if
current_step
<
self
.
num_warmup_steps
:
return
float
(
current_step
)
/
float
(
max
(
1
,
self
.
num_warmup_steps
))
no_progress
=
float
(
current_step
-
self
.
num_warmup_steps
)
/
\
float
(
max
(
1
,
self
.
epochs
*
self
.
step_each_epoch
-
self
.
num_warmup_steps
))
return
max
(
0.
,
math
.
cos
(
math
.
pi
*
self
.
num_cycles
*
no_progress
))
learning_rate
=
lr
.
LambdaDecay
(
learning_rate
=
self
.
learning_rate
,
lr_lambda
=
_lr_lambda
,
last_epoch
=
self
.
last_epoch
)
setattr
(
learning_rate
,
"by_epoch"
,
self
.
by_epoch
)
return
learning_rate
\ No newline at end of file
ppcls/optimizer/optimizer.py
浏览文件 @
944763d7
...
@@ -93,24 +93,49 @@ class Momentum(object):
...
@@ -93,24 +93,49 @@ class Momentum(object):
momentum
,
momentum
,
weight_decay
=
None
,
weight_decay
=
None
,
grad_clip
=
None
,
grad_clip
=
None
,
multi_precision
=
True
):
use_nesterov
=
False
,
multi_precision
=
True
,
no_weight_decay_name
=
None
):
super
().
__init__
()
super
().
__init__
()
self
.
learning_rate
=
learning_rate
self
.
learning_rate
=
learning_rate
self
.
momentum
=
momentum
self
.
momentum
=
momentum
self
.
weight_decay
=
weight_decay
self
.
weight_decay
=
weight_decay
self
.
grad_clip
=
grad_clip
self
.
grad_clip
=
grad_clip
self
.
multi_precision
=
multi_precision
self
.
multi_precision
=
multi_precision
self
.
use_nesterov
=
use_nesterov
self
.
no_weight_decay_name_list
=
no_weight_decay_name
.
split
(
)
if
no_weight_decay_name
else
[]
def
__call__
(
self
,
model_list
):
def
__call__
(
self
,
model_list
):
# model_list is None in static graph
# model_list is None in static graph
parameters
=
sum
([
m
.
parameters
()
for
m
in
model_list
],
parameters
=
None
[])
if
model_list
else
None
if
len
(
self
.
no_weight_decay_name_list
)
>
0
:
params_with_decay
=
[]
params_without_decay
=
[]
for
m
in
model_list
:
params
=
[
p
for
n
,
p
in
m
.
named_parameters
()
\
if
not
any
(
nd
in
n
for
nd
in
self
.
no_weight_decay_name_list
)]
params_with_decay
.
extend
(
params
)
params
=
[
p
for
n
,
p
in
m
.
named_parameters
()
\
if
any
(
nd
in
n
for
nd
in
self
.
no_weight_decay_name_list
)]
params_without_decay
.
extend
(
params
)
parameters
=
[{
"params"
:
params_with_decay
,
"weight_decay"
:
self
.
weight_decay
},
{
"params"
:
params_without_decay
,
"weight_decay"
:
0.0
}]
else
:
parameters
=
sum
([
m
.
parameters
()
for
m
in
model_list
],
[])
if
model_list
else
None
opt
=
optim
.
Momentum
(
opt
=
optim
.
Momentum
(
learning_rate
=
self
.
learning_rate
,
learning_rate
=
self
.
learning_rate
,
momentum
=
self
.
momentum
,
momentum
=
self
.
momentum
,
weight_decay
=
self
.
weight_decay
,
weight_decay
=
self
.
weight_decay
,
grad_clip
=
self
.
grad_clip
,
grad_clip
=
self
.
grad_clip
,
multi_precision
=
self
.
multi_precision
,
multi_precision
=
self
.
multi_precision
,
use_nesterov
=
self
.
use_nesterov
,
parameters
=
parameters
)
parameters
=
parameters
)
if
hasattr
(
opt
,
'_use_multi_tensor'
):
if
hasattr
(
opt
,
'_use_multi_tensor'
):
opt
=
optim
.
Momentum
(
opt
=
optim
.
Momentum
(
...
@@ -120,6 +145,7 @@ class Momentum(object):
...
@@ -120,6 +145,7 @@ class Momentum(object):
grad_clip
=
self
.
grad_clip
,
grad_clip
=
self
.
grad_clip
,
multi_precision
=
self
.
multi_precision
,
multi_precision
=
self
.
multi_precision
,
parameters
=
parameters
,
parameters
=
parameters
,
use_nesterov
=
self
.
use_nesterov
,
use_multi_tensor
=
True
)
use_multi_tensor
=
True
)
return
opt
return
opt
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录