Merge pull request #2250 from RainFrost1/develop
更新shitu 主页、主体检测、库管理、lite_shitu文档
Showing
deploy/lite_shitu/README.md
已删除
100644 → 0
deploy/lite_shitu/README.md
0 → 120000
{kind=link}
{kind=link}
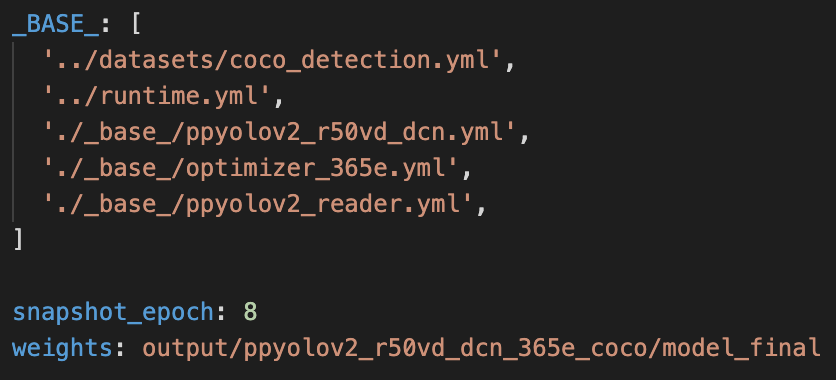
| W: | H:
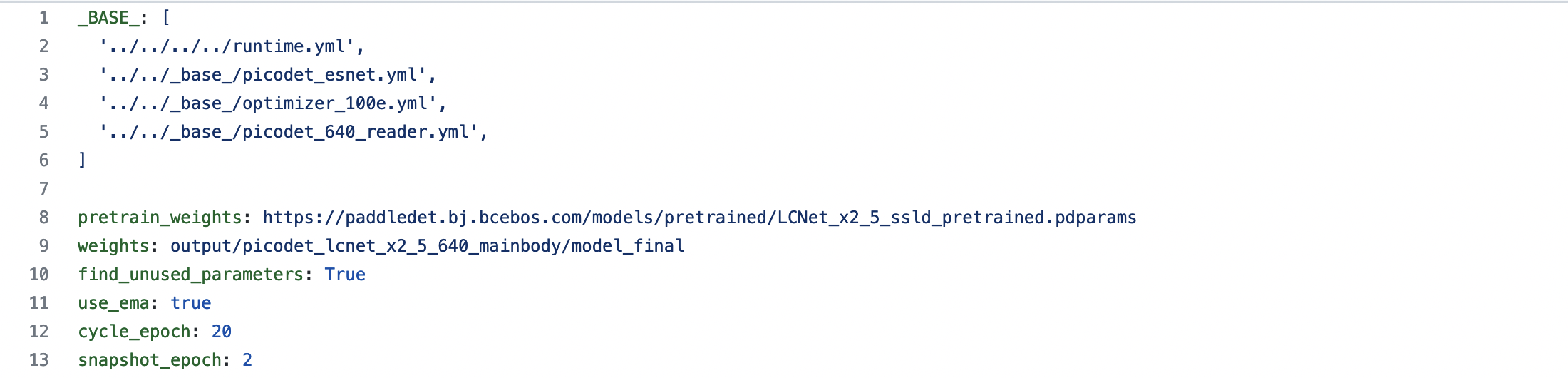
| W: | H:
{kind=link}
文件已移动
{kind=link}
111.3 KB
{kind=link}
753.8 KB
{kind=link}

1.2 MB
{kind=link}
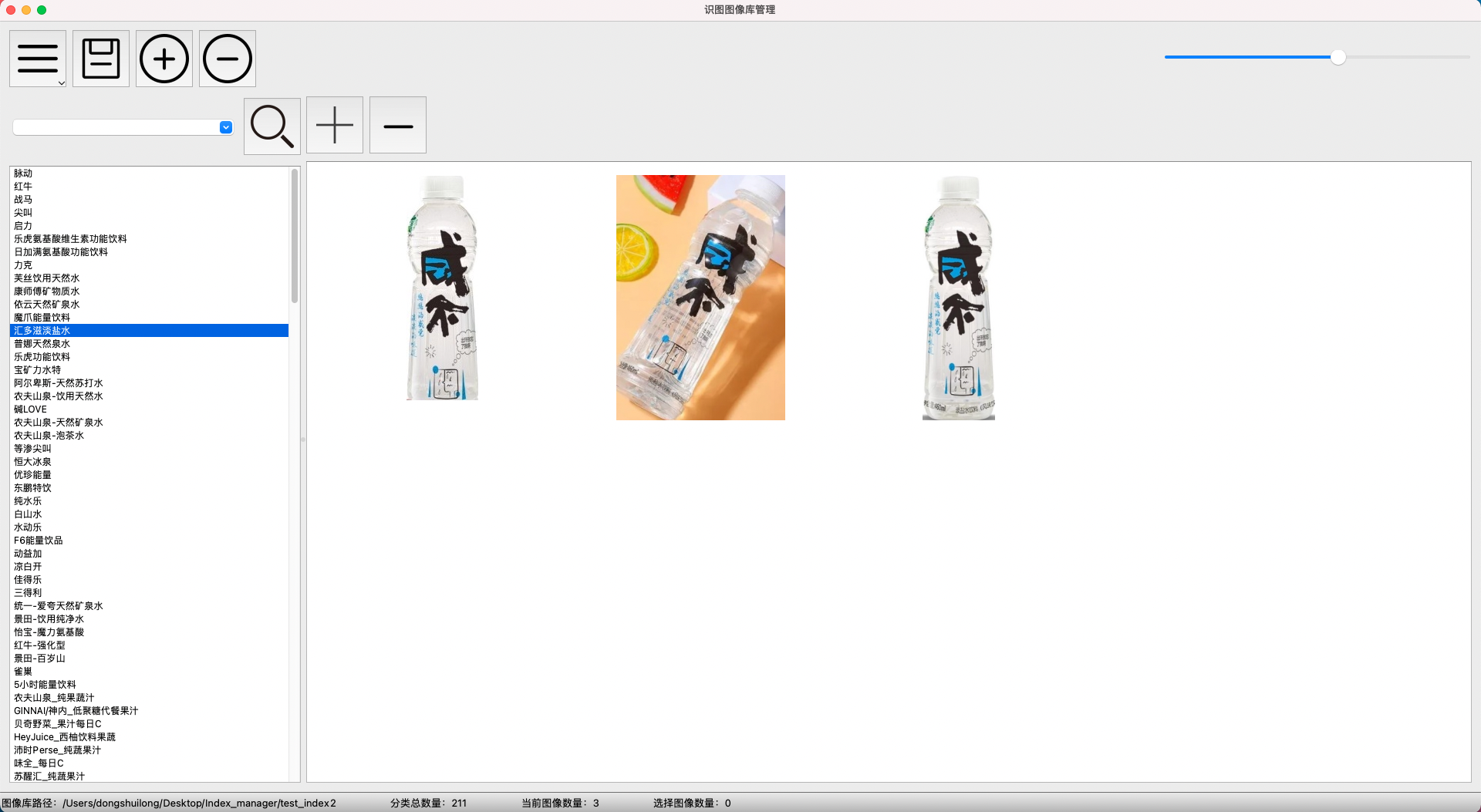
767.4 KB
{kind=link}
56.2 KB