Update faq_2021_s1 (#572)
Showing
docs/images/faq/ACNetFusion.png
0 → 100644
{kind=link}

132.8 KB
docs/images/faq/ACNetReParams.png
0 → 100644
{kind=link}
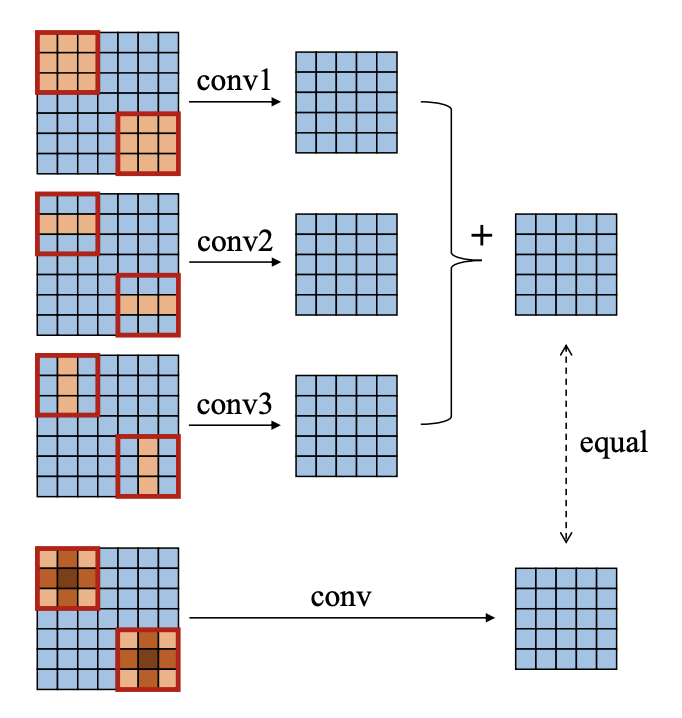
53.5 KB
docs/images/faq/DeployedACNet.png
0 → 100644
{kind=link}
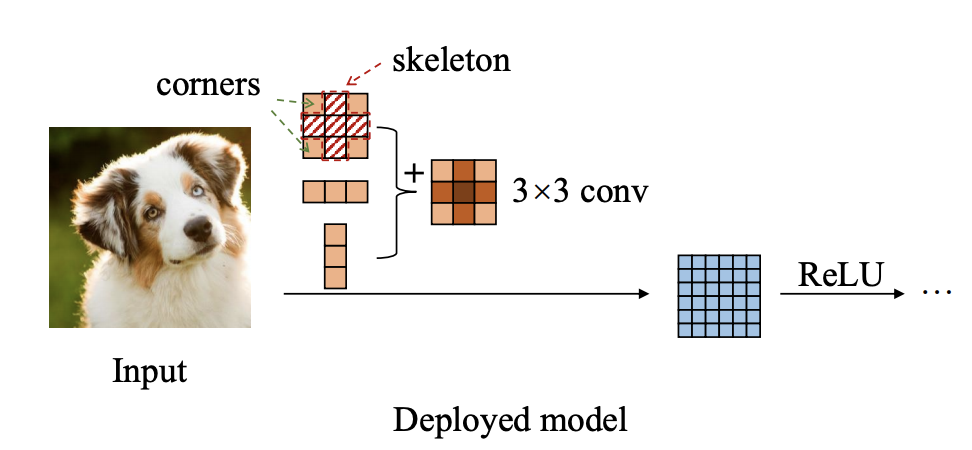
132.6 KB
{kind=link}
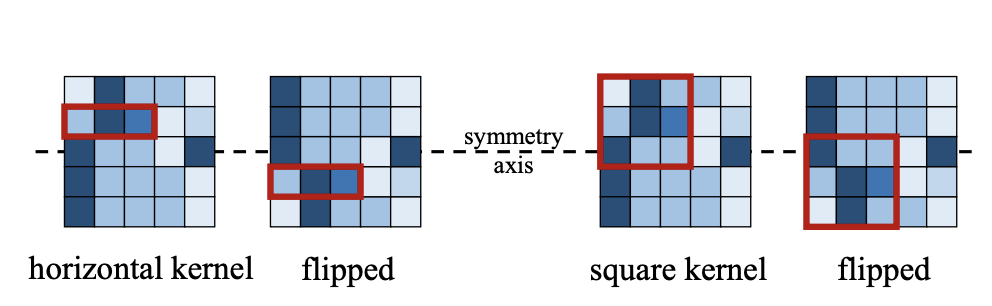
33.7 KB
{kind=link}
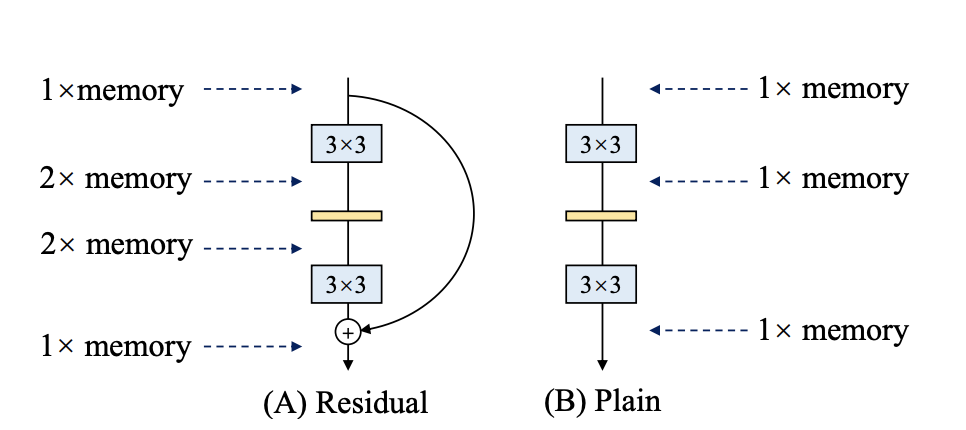
56.6 KB
docs/images/faq/RepVGG.png
0 → 100644
{kind=link}
106.3 KB
{kind=link}
161.9 KB
{kind=link}
119.6 KB