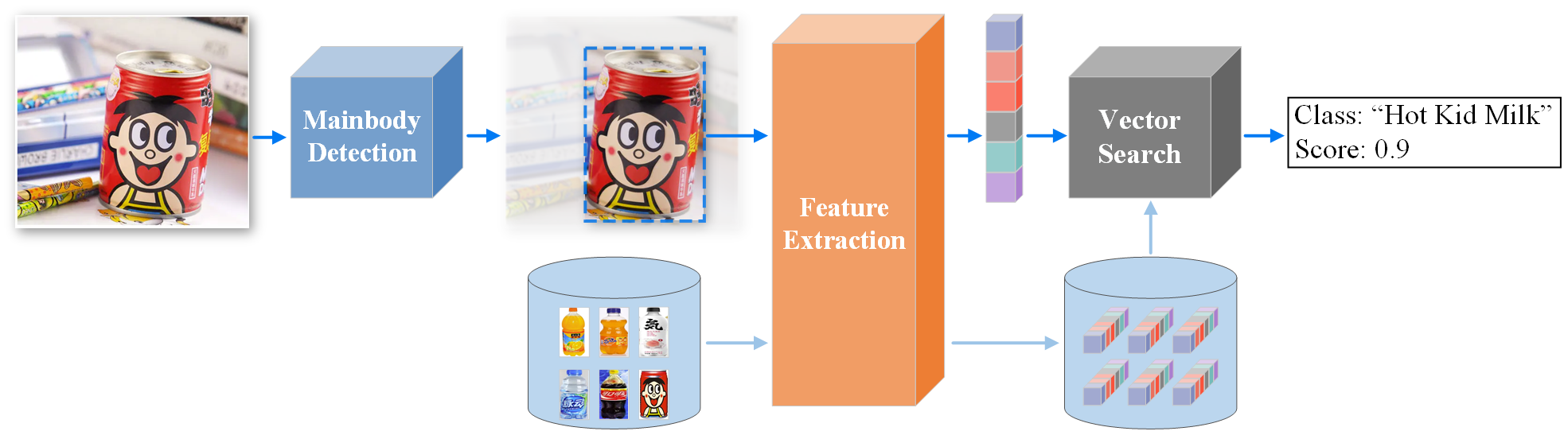
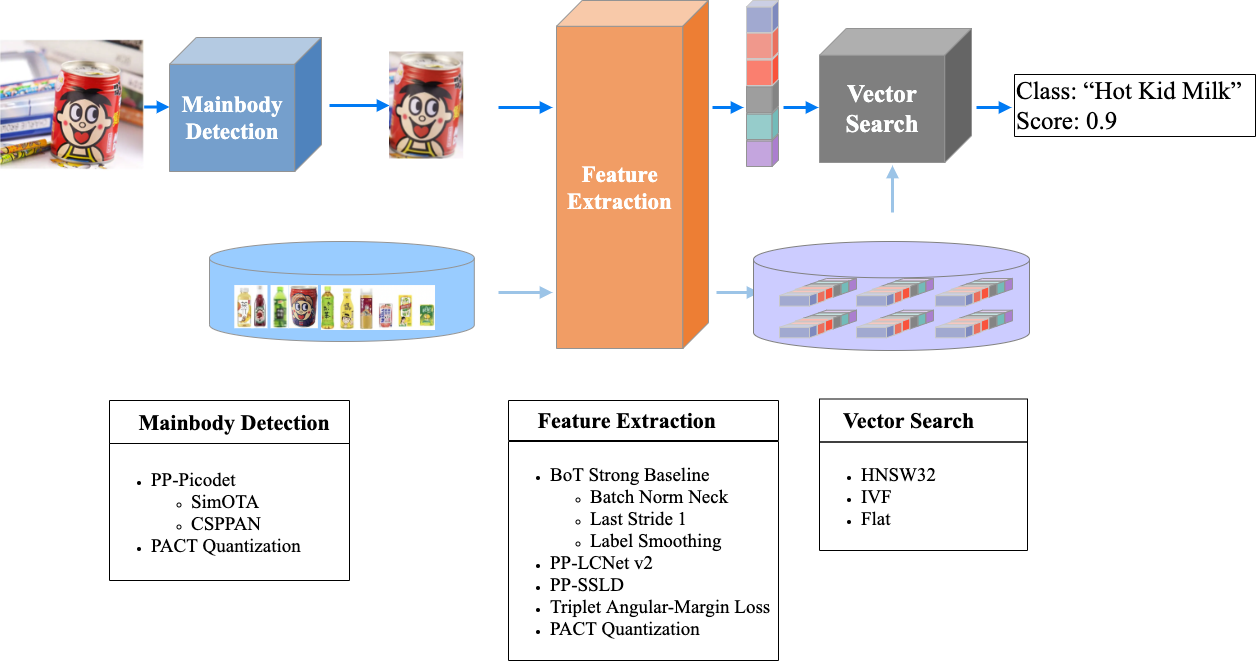
**注:** product数据集是为了验证PP-ShiTu的泛化性能而制作的数据集,所有的数据都没有在训练和测试集中出现。该数据包含8个大类(人脸、化妆品、地标、红酒、手表、车、运动鞋、饮料),299个小类。测试时,使用299个小类的标签进行测试;sop数据集来自[GPR1200: A Benchmark for General-Purpose Content-Based Image Retrieval](https://arxiv.org/abs/2111.13122),可视为“SOP”数据集的子集。
## 参考文献
1. Schall, Konstantin, et al. "GPR1200: A Benchmark for General-Purpose Content-Based Image Retrieval." International Conference on Multimedia Modeling. Springer, Cham, 2022.
2. Luo, Hao, et al. "A strong baseline and batch normalization neck for deep person re-identification." IEEE Transactions on Multimedia 22.10 (2019): 2597-2609.
{kind=link}
{kind=link}