骨干网络对计算机视觉下游任务的影响不言而喻,不仅对下游模型的性能影响很大,而且模型效率也极大地受此影响,但现有的大多骨干网络在真实应用中的效率并不理想,特别是缺乏针对 Intel CPU 平台所优化的骨干网络,我们测试了现有的主流轻量级模型,发现在 Intel CPU 平台上的效率并不理想,然而目前 Intel CPU 平台在工业界仍有大量使用场景,因此我们提出了 PP-LCNet 系列模型,PP-LCNetV2 是在 [PP-LCNetV1](./PP-LCNet.md) 基础上所提出的。
骨干网络对计算机视觉下游任务的影响不言而喻,不仅对下游模型的性能影响很大,而且模型效率也极大地受此影响,但现有的大多骨干网络在真实应用中的效率并不理想,特别是缺乏针对 Intel CPU 平台所优化的骨干网络,我们测试了现有的主流轻量级模型,发现在 Intel CPU 平台上的效率并不理想,然而目前 Intel CPU 平台在工业界仍有大量使用场景,因此我们提出了 PP-LCNet 系列模型,PP-LCNetV2 是在 [PP-LCNetV1](./PP-LCNet.md) 基础上所改进的。
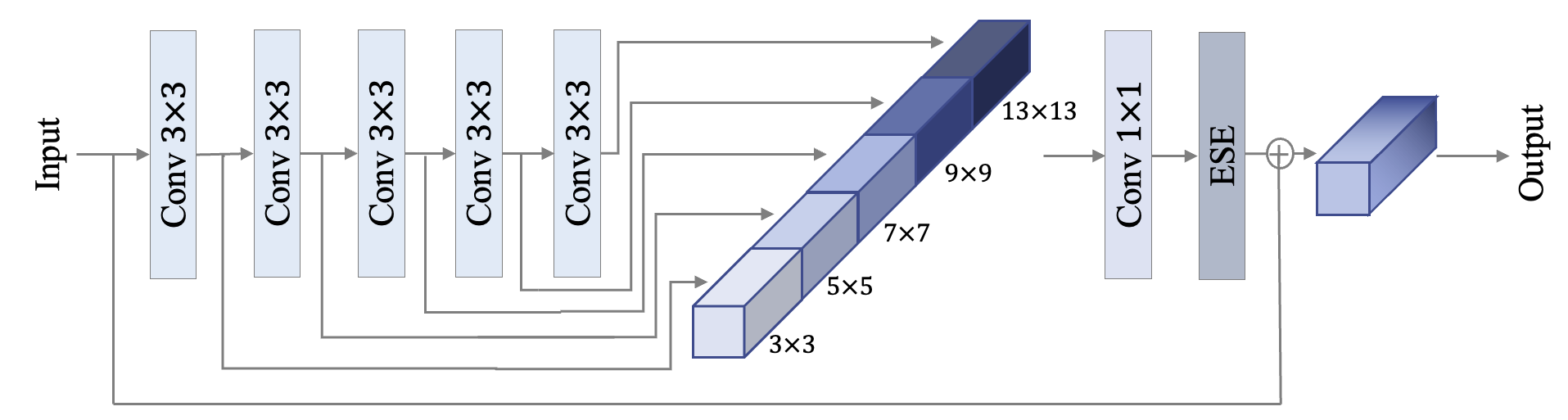
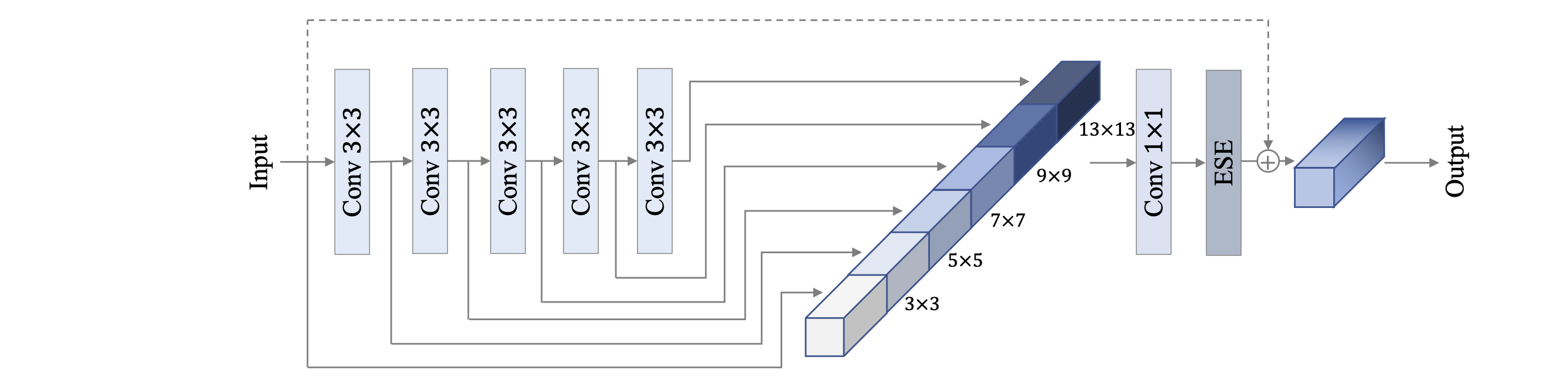
虽然 SE 模块能够为模型带来显著提高,但其对模型速度的影响同样不可忽视,在 PP-LCNetV1 中,我们发现在模型中后部使用 SE 模块能够获得最大化的收益。在 PP-LCNetV2 的优化过程中,我们以 Stage 为单位对 SE 模块的位置做了进一步实验,并发现在 Stage3 中使用能够取得更好的平衡。
虽然 SE 模块能够显著提高模型性能,但其对模型速度的影响同样不可忽视,在 PP-LCNetV1 中,我们发现在模型中后部使用 SE 模块能够获得最大化的收益。在 PP-LCNetV2 的优化过程中,我们以 Stage 为单位对 SE 模块的位置做了进一步实验,并发现在 Stage3 中使用能够取得更好的平衡。
## 3. 实验结果
在不使用额外数据的前提下,PPLCNetV2_base 模型在图像分类 ImageNet 数据集上能够取得超过 77% 的 Top1 Acc,同时在 Intel CPU 平台仅有 4.4 ms 以下的延迟,如下表所示,其中延时测试基于 Intel(R) Xeon(R) Gold 6271C CPU @ 2.60GHz 硬件平台,OpenVINO 推理平台。
在不使用额外数据的前提下,PPLCNetV2_base 模型在图像分类 ImageNet 数据集上能够取得超过 77% 的 Top1 Acc,同时在 Intel CPU 平台的推理时间在 4.4 ms 以下,如下表所示,其中推理时间基于 Intel(R) Xeon(R) Gold 6271C CPU @ 2.60GHz 硬件平台,OpenVINO 推理平台。
{kind=link}
{kind=link}